



Really important work! It's easy to say (as many of us do) that more diverse/multilingual data is the best solution to various reliability challenges. But what data? How much? Which languages? What are the tradeoffs? All very understudied questions. Congrats, Shayne & team!

📢Thrilled to introduce ATLAS 🗺️: scaling laws beyond English, for pretraining, finetuning, and the curse of multilinguality. The largest public, multilingual scaling study to-date—we ran 774 exps (10M-8B params, 400+ languages) to answer: 🌍Are scaling laws different by…



Twitter seem to be only now finding about these bad boys. It has been around for some time and it's insane what people can do with them

The biggest mistake in thinking about AI and robots? expecting it to act human. It won’t and that’s exactly why it’ll be 1000× more capable i.e. this RC helicopter shows what machines can do when you remove the anthropomorphism layer in your expectations

Some thoughts/experiences on this for people to onboard to use Muon (unfortunately, it is not as easy as element-wise AdamW to use ...). In the open-source community, I helped onboard Muon into PyTorch and Megatron-LM, and I usually follow these steps to develop Muon on a…

Whenever people ask me, “Is Muon optimizer just hype?” I need to show them this. Muon isn’t just verified and used in Kimi; other frontier labs like OpenAI are using it and its variants. It’s also in PyTorch stable now!


Hi @JeffDean, what’s the plan for releasing the code for this line of work? None of these papers so far seem to have released any code



We've just finished some work on improving the sensitivity of Muon to the learning rate, and exploring a lot of design choices. If you want to see how we did this, follow me ....1/x (Work lead by the amazing @CrichaelMawshaw)


the date is november 6th, 2025. you can download the most powerful agentic artificial intelligence in the world for free, under a permissive license and so it is a good day!

🚀 Hello, Kimi K2 Thinking! The Open-Source Thinking Agent Model is here. 🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%) 🔹 Executes up to 200 – 300 sequential tool calls without human interference 🔹 Excels in reasoning, agentic search, and coding 🔹 256K context window Built…


to continue the PipelineRL glazing, @finbarrtimbers implemented PipelineRL for open-instruct a little bit ago and it ended up being probably the single biggest speedup to our overall pipeline. We went from 2-week long RL runs to 5-day runs, without sacrificing performance…


Don't sleep on PipelineRL -- this is one of the biggest jumps in compute efficiency of RL setups that we found in the ScaleRL paper (also validated by Magistral & others before)! What's the problem PipelineRL solves? In RL for LLMs, we need to send weight updates from trainer to…




What really matters in matrix-whitening optimizers (Shampoo/SOAP/PSGD/Muon)? We ran a careful comparison, dissecting each algorithm. Interestingly, we find that proper matrix-whitening can be seen as *two* transformations, and not all optimizers implement both. Blog:…

I crossed an interesting threshold yesterday, which I think many other mathematicians have been crossing recently as well. In the middle of trying to prove a result, I identified a statement that looked true and that would, if true, be useful to me. 1/3

you see that new attention variant? you’re going to be writing our custom CUDA kernel for it



Insane result and while the smaller training-inference gap makes sense, I cannot believe it has such a huge effect

FP16 can have a smaller training-inference gap compared to BFloat16, thus fits better for RL. Even the difference between RL algorithms vanishes once FP16 is adopted. Surprising!


between minimax ditching linear attention and kimi finding a variant that outperform full attention I’m completely confused
Kimi Linear Tech Report is dropped! 🚀 huggingface.co/moonshotai/Kim… Kimi Linear: A novel architecture that outperforms full attention with faster speeds and better performance—ready to serve as a drop-in replacement for full attention, featuring our open-sourced KDA kernels! Kimi…


You see: - a new arch that is better and faster than full attention verified with Kimi-style solidness. I see: - Starting with inferior performance even on short contexts. Nothing works and nobody knows why. - Tweaking every possible hyper-parameter to grasp what is wrong. -…
Kimi Linear Tech Report is dropped! 🚀 huggingface.co/moonshotai/Kim… Kimi Linear: A novel architecture that outperforms full attention with faster speeds and better performance—ready to serve as a drop-in replacement for full attention, featuring our open-sourced KDA kernels! Kimi…

7/12 You can clearly see the scaling in performance: With just 1 loop (T=1), the model performs poorly. At T=4 loops, its reasoning and math capabilities are much improved, reaching SOTA levels. More “thinking” directly translates to stronger capabilities.


> you are > MiniMax M2 pretrain lead > now everyone’s asking why you went full attention again > “aren’t you supposed to be the efficiency gang?” > efficient attention? yeah we tried > we trained small hybrids > looked good > matched full attention on paper > scaled up >…

MiniMax M2 Tech Blog 3: Why Did M2 End Up as a Full Attention Model? On behave of pre-training lead Haohai Sun. (zhihu.com/question/19653…) I. Introduction As the lead of MiniMax-M2 pretrain, I've been getting many queries from the community on "Why did you turn back the clock…

You can do TRM/HRM with reinforcement learning!

HRM-Agent: Using the Hierarchical Reasoning Model in Reinforcement Learning Paper: arxiv.org/abs/2510.22832 The Hierarchical Reasoning Model (HRM) has impressive reasoning abilities given its small size, but has only been applied to supervised, static, fully-observable problems.


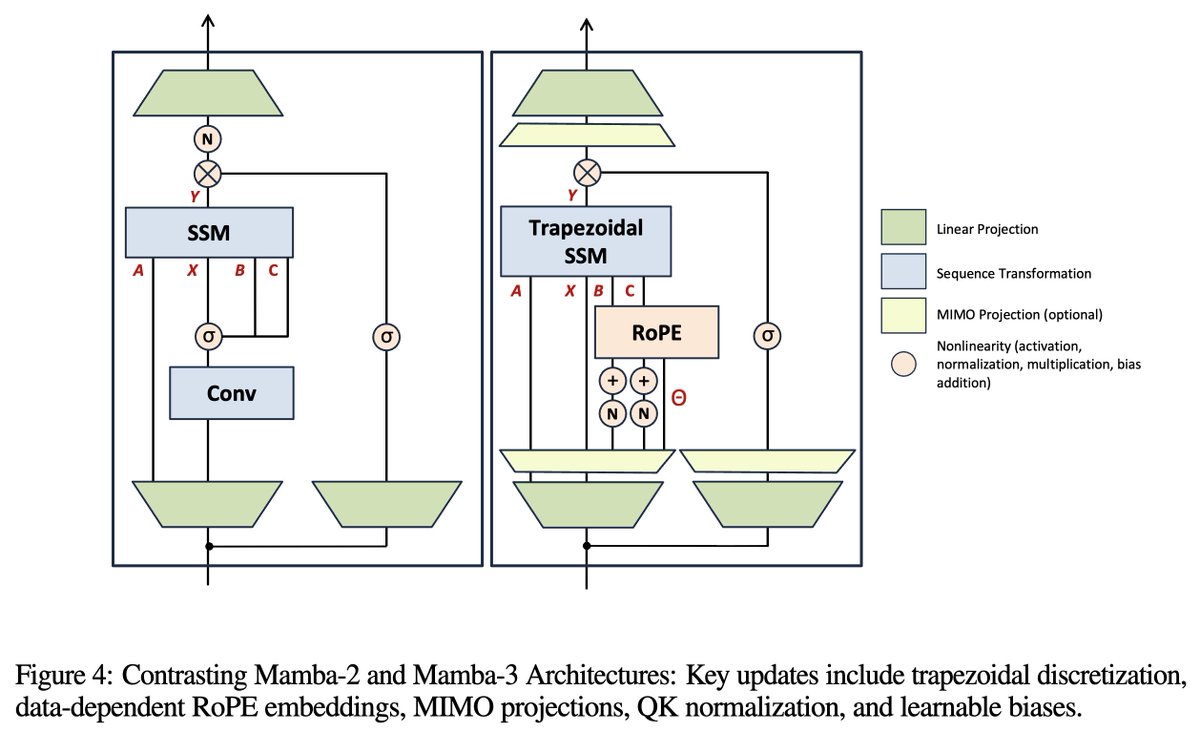
🎉 Our paper "Tensor Product Attention Is All You Need" has been accepted as NeurIPS 2025 Spotlight (Top 3%)! The Camera Ready version of TPA has been publicly available on the arXiv now: arxiv.org/abs/2501.06425 ⚡️TPA is stronger and faster than GQA and MLA, and is compatible…

🎉Our paper, "Tensor Product Attention Is All You Need," has been accepted for a spotlight presentation at the 2025 Conference on Neural Information Processing Systems (NeurIPS 2025)! See arxiv.org/abs/2501.06425 and github.com/tensorgi/TPA for details!
![yifan_zhang_'s tweet card. [NeurIPS 2025 Spotlight] TPA: Tensor ProducT ATTenTion Transformer (T6) (https://arxiv.org/abs/2501.06425) - tensorgi/TPA](https://pbs.twimg.com/card_img/1986658792302317568/nTQ7cgnS?format=jpg&name=orig)

I have a thing for empirical deep dive into learning dynamics like done in this paper. Sounds like muP mostly helps the early training, while wd affects the long term.

The Maximal Update Parameterization (µP) allows LR transfer from small to large models, saving costly tuning. But why is independent weight decay (IWD) essential for it to work? We find µP stabilizes early training (like an LR warmup), but IWD takes over in the long term! 🧵

































































































United States Trendy
- 1. Rosalina 41.5K posts
- 2. Bowser Jr 13.5K posts
- 3. Jeffrey Epstein 95.4K posts
- 4. $SENS $0.70 Senseonics CGM N/A
- 5. $LMT $450.50 Lockheed F-35 N/A
- 6. #NASDAQ_MYNZ N/A
- 7. Virginia Giuffre 8,786 posts
- 8. $APDN $0.20 Applied DNA N/A
- 9. Michael Wolff 6,841 posts
- 10. H-1B 74.6K posts
- 11. AJ Brown 5,744 posts
- 12. Marvin Harrison Jr. N/A
- 13. Jameis 5,650 posts
- 14. Mario Galaxy 92.1K posts
- 15. Delaware 8,046 posts
- 16. #wednesdaymotivation 5,530 posts
- 17. House Democrats 45K posts
- 18. Captain Marvel 2,504 posts
- 19. Humanity 98.6K posts
- 20. Luigi 10.8K posts
Something went wrong.
Something went wrong.