
はち
@CurveWeb
IT企業勤務。犬とコーヒーが好き。 HuggingFace → https://huggingface.co/HachiML Note → https://note.com/hatti8 LLM, Synthetic data(合成データ), Agent Systemについて発言します
You might like









OpenAI o1再現を目指し、LLMの推論能力を高めるライブラリを作成しました。 MCTSアルゴリズムを簡単にLLM(CoTデータ学習済)に統合して推論できるようにしてあります。 また、Transformersとなるべく近い使い方になっているので比較的簡単に試せると思います。 github.com/Hajime-Y/reaso…


Unlocking the Power of Multi-Agent LLM for Reasoning Designing and optimizing multi-agent systems is important. This paper analyzes multi‑agent systems where one meta‑thinking agent plans and another reasoning agent executes, and identifies a lazy agent failure mode. They find…


The memory folding mechanism proposed in this paper is great. It makes sense that agents should spend time explicitly compressing their memory into a semantic / organized format to avoid context explosion. Worth mentioning though that memory compression / retention in agents…


Open-source, private, local alternative to Manus AI! AgenticSeek is an autonomous agent that browses the web, writes code, and plans tasks, all on your device. It runs entirely on your hardware, ensuring complete privacy and zero cloud dependency. Key Features: 🔒 Local &…


cool idea from Meta What if we augment CoT + RL’s token space thinking into a “latent space”? This research proposes “The Free Transformer”, with a way to let LLMs make global decisions within a latent space (via VAE encoder) that could later simplify autoregressive sampling


Now in research preview: gpt-oss-safeguard Two open-weight reasoning models built for safety classification. openai.com/index/introduc…


Introducing Chronos-2: a foundation model that enables forecasting with an arbitrary number of dimensions in a zero-shot manner, outperforming existing time series foundation models by a substantial margin: amzn.to/4nkHQqp

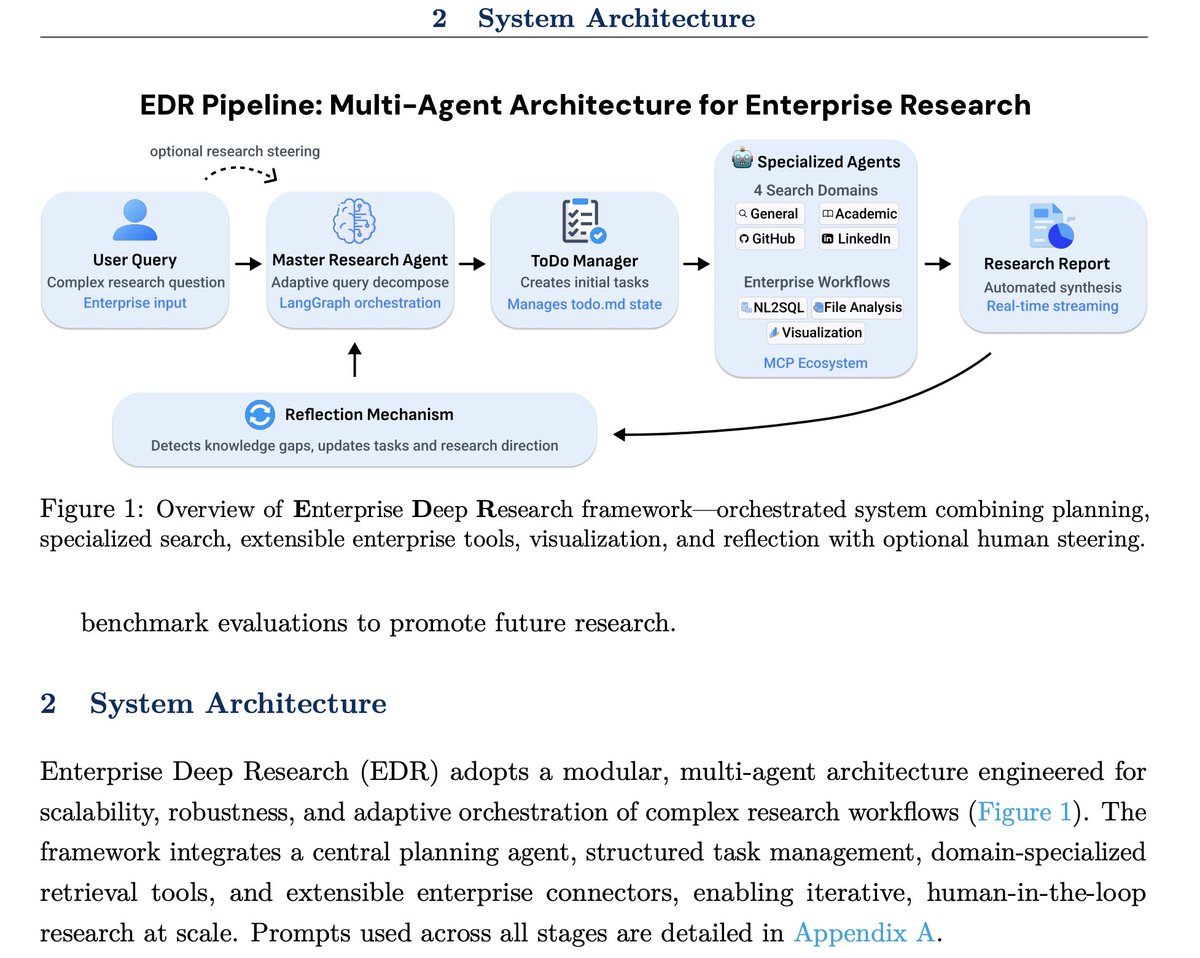
People are sleeping on Deep Agents. Start using them now. This is a fun paper showcasing how to put together advanced deep agents for enterprise use cases. Uses the best techniques: task decomposition, planning, specialized subagents, MCP for NL2SQL, file analysis, and more.


"「Attention Is All You Need」の共著者(Sakana AI の CTO)、「トランスフォーマーにはうんざり」と語る" という記事から: ・AI研究が「トランスフォーマー」という一つの技術に偏りすぎている ・AI研究の現状は危険なほど視野が狭くなっている…

Just 2 days after Google, we have another big quantum computing breakthrough IBM says one of its key quantum error correction algorithms now can run in real time on AMD FPGA (field programmable gate array) chips, no exotic hardware is needed. This breakthrough could make…


Knowledge Flow show LLMs can push past context limits by carrying a tiny editable knowledge list across attempts. Hits 100% on AIME25 using text only, so test time memory can unlock big gains. This approach achieved a 100% accuracy on AIME 2025 using only open-source models,…


Can LLMs reason beyond context limits? 🤔 Introducing Knowledge Flow, a training-free method that helped gpt-oss-120b & Qwen3-235B achieve 100% on the AIME-25, no tools. How? like human deliberation, for LLMs. 📝 Blog: yufanzhuang.notion.site/knowledge-flow 💻 Code: github.com/EvanZhuang/kno…


Googleの量子アドバンテージきたー thequantuminsider.com/2025/10/22/goo… スクランブリングのあるダイナミクスにおいて2次のOTOCを測って、「構成的な干渉」を見ました。簡単に言うと量子コンピュータで物理現象をみました もちろん反論も出てます。 nature.com/articles/d4158… 原論文はnature.com/articles/s4158…


🚀 Excited to share a major update to our “Mixture of Cognitive Reasoners” (MiCRo) paper! We ask: What benefits can we unlock by designing language models whose inner structure mirrors the brain’s functional specialization? More below 🧠👇 cognitive-reasoners.epfl.ch

ByteDance introduced a major advancement in long-context modeling with linearly scaling compute. 👏 Addresses a core challenge in AI—balancing efficiency and fidelity when processing extended sequences—by drawing inspiration from biological memory systems. On 128k tests, FLOPs…


🚨BREAKING: A new open-source multi-agent LLM trading framework in Python It's called TradingAgents. Here's what it does (and how to get it for FREE): 🧵




The standard way to improve reasoning in LLMs is to train on long chains of thought. But these traces are often brute-force and shallow. Introducing RLAD, where models instead learn _reasoning abstractions_: concise textual strategies that guide structured exploration. 1/N🧵

Today we’re introducing GDPval, a new evaluation that measures AI on real-world, economically valuable tasks. Evals ground progress in evidence instead of speculation and help track how AI improves at the kind of work that matters most. openai.com/index/gdpval-v0


ShinkaEvolve出ました!LLMを使ったコード自動改善のフレームワークです。Sakana AI版AlphaEvolve……と言うと話は簡単ですが、性能も使いやすさも様々な工夫があり、凄く良く出来てます。自分も面白い利用を既に何度か試してまして、このソフトウェアの大ファンです。その話はまた後日……!

We’re excited to introduce ShinkaEvolve: An open-source framework that evolves programs for scientific discovery with unprecedented sample-efficiency. Blog: sakana.ai/shinka-evolve/ Code: github.com/SakanaAI/Shink… Like AlphaEvolve and its variants, our framework leverages LLMs to…

New from Meta FAIR: Code World Model (CWM), a 32B-parameter research model designed to explore how world models can transform code generation and reasoning about code. We believe in advancing research in world modeling and are sharing CWM under a research license to help empower…

New on the Anthropic Engineering blog: writing effective tools for LLM agents. AI agents are only as powerful as the tools we give them. So how do we make those tools more effective? We share our best tips for developers: anthropic.com/engineering/wr…

















































































































United States Trends
- 1. Northern Lights 46.2K posts
- 2. #Aurora 9,858 posts
- 3. #hazbinhotelspoilers 2,123 posts
- 4. #chaggie 4,044 posts
- 5. #huskerdust 7,971 posts
- 6. #DWTS 53.3K posts
- 7. Carmilla 2,354 posts
- 8. MIND-BLOWING 35.7K posts
- 9. AI-driven Web3 N/A
- 10. H-1B 36.6K posts
- 11. Justin Edwards 2,528 posts
- 12. Superb 22.4K posts
- 13. Sabonis 6,265 posts
- 14. SPECTACULAR 25.1K posts
- 15. Creighton 2,338 posts
- 16. Louisville 18.2K posts
- 17. Wike 220K posts
- 18. H1-B 4,230 posts
- 19. Gonzaga 2,995 posts
- 20. Cleto 2,643 posts









Something went wrong.
Something went wrong.