
Nibaldo
@CyberMath4
ML Engineer | Master in Advanced & Applied AI | MSc Statistics | MSc Full Stack Web Developer | Math Teacher | Bachelor Engineering Sciences | From 🇪🇸🇨🇱
You might like








DeepSeek-OCR is the best OCR ever. It parses this extremely hard to read handwritten letter written by mathematician Ramanujan in 1913 with a frightening degree of accuracy. Not perfect, but beats former best dots ocr. Bonus points if you can spot the errors. Try it here:


This is the JPEG moment for AI. Optical compression doesn't just make context cheaper. It makes AI memory architectures viable. Training data bottlenecks? Solved. - 200k pages/day on ONE GPU - 33M pages/day on 20 nodes - Every multimodal model is data-constrained. Not anymore.…


Agentic Context Engineering Great paper on agentic context engineering. The recipe: Treat your system prompts and agent memory as a living playbook. Log trajectories, reflect to extract actionable bullets (strategies, tool schemas, failure modes), then merge as append-only…


🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model! ✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context. 👉 Now live on App, Web, and API. 💰 API prices cut by 50%+! 1/n

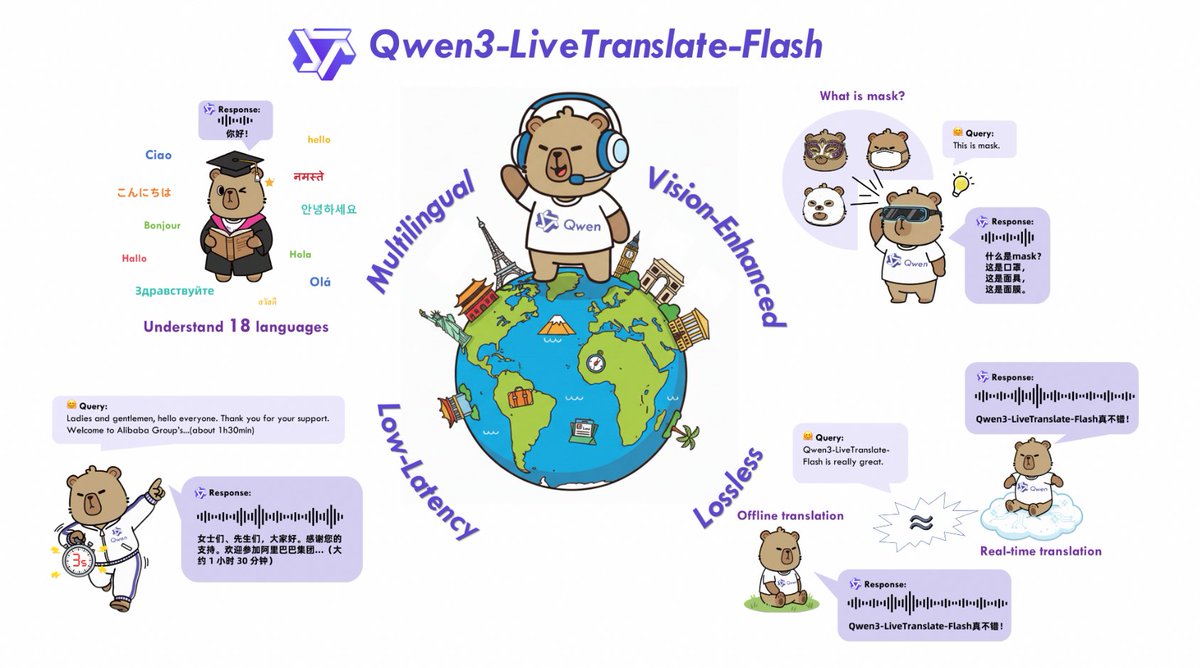
🚀 Introducing Qwen3-LiveTranslate-Flash — Real‑Time Multimodal Interpretation — See It, Hear It, Speak It! 🌐 Wide language coverage — Understands 18 languages & 6 dialects, speaks 10 languages. 👁️ Vision‑Enhanced Comprehension — Reads lips, gestures, on‑screen text and…

Microsoft introduces Latent Zoning Network (LZN) A unified principle for generative modeling, representation learning, and classification. LZN uses a shared Gaussian latent space and modular encoders/decoders to tackle all three core ML problems at once!

🚀 Introducing Qwen3-Next-80B-A3B — the FUTURE of efficient LLMs is here! 🔹 80B params, but only 3B activated per token → 10x cheaper training, 10x faster inference than Qwen3-32B.(esp. @ 32K+ context!) 🔹Hybrid Architecture: Gated DeltaNet + Gated Attention → best of speed &…


Updated & turned my Big LLM Architecture Comparison article into a narrated video lecture. The 11 LLM architectures covered in this video: 1. DeepSeek V3/R1 2. OLMo 2 3. Gemma 3 4. Mistral Small 3.1 5. Llama 4 6. Qwen3 7. SmolLM3 8. Kimi 2 9. GPT-OSS 10. Grok 2.5 11. GLM-4.5

3T tokens, ~1800 languages, 2 models - we’re releasing mmBERT, a modern multilingual encoder model!


.@OpenAI has been cooking! Here is OpenAI's Ollama cookbook cookbook.openai.com/articles/gpt-o…
cookbook.openai.com
How to run gpt-oss locally with Ollama | OpenAI Cookbook
Want to get OpenAI gpt-oss running on your own hardware? This guide will walk you through how to use Ollama to set up gpt-oss-20b or gpt-...



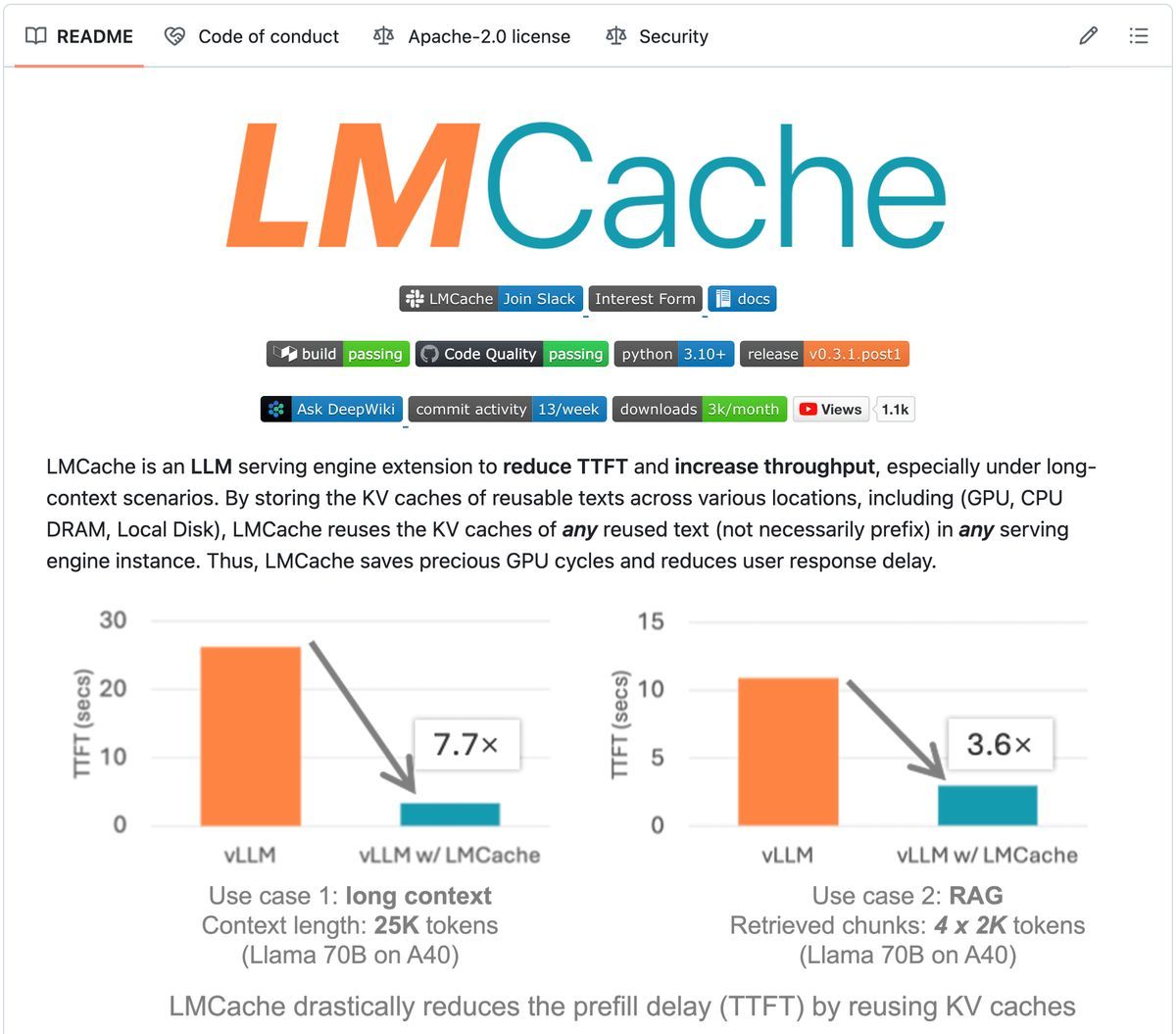
This is the fastest serving engine for LLMs! LMCache cuts time-to-first-token by 7x and slashes GPU costs dramatically. Think of it as a smart caching layer that remembers everything your LLM has processed before. 100% open-source, makes vLLM go brr...
So, I did some coding this week... - Qwen3 Coder Flash (30B-A3B) - Mixture-of-Experts setup with 128 experts, 8 active per token - In pure PyTorch (optimized for human readability) - in a standalone Jupyter notebook - Runs on a single A100


The wait is over: Deep Think is here. At I/O, we previewed the frontiers of Gemini’s thinking capabilities. Now, @Google AI Ultra subscribers can experience it in the Gemini app. With Deep Think, Gemini 2.5 is able to intelligently extend its "thinking time" so it can generate…





Don’t let your AI project die in a notebook. You don’t need more features. You need structure. This is the folder setup that actually ships from day one. 📁 𝗧𝗵𝗲 𝗳𝗼𝗹𝗱𝗲𝗿 𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 𝘁𝗵𝗮𝘁 𝘄𝗼𝗿𝗸𝘀 Forget monolithic scripts. You need this: /config 🔹YAML…



5 techniques to fine-tune LLMs, explained visually! Fine-tuning large language models traditionally involved adjusting billions of parameters, demanding significant computational power and resources. However, the development of some innovative methods have transformed this…

We made a Guide to teach you how to Fine-tune LLMs correctly! Learn about: • Choosing the right parameters & training method • RL, GRPO, DPO & CPT • Data prep, Overfitting & Evaluation • Training with Unsloth & deploy on vLLM, Ollama, Open WebUI 🔗 docs.unsloth.ai/get-started/fi…































































































United States Trends
- 1. New York 18.8K posts
- 2. New York 18.8K posts
- 3. Virginia 505K posts
- 4. $TAPIR 1,608 posts
- 5. #DWTS 39.8K posts
- 6. Texas 211K posts
- 7. Prop 50 168K posts
- 8. Cuomo 395K posts
- 9. TURN THE VOLUME UP 13.1K posts
- 10. Sixers 12.7K posts
- 11. Bulls 35K posts
- 12. Jay Jones 96.4K posts
- 13. #Election2025 15.6K posts
- 14. Harden 9,112 posts
- 15. Embiid 6,037 posts
- 16. Maxey 7,833 posts
- 17. Eugene Debs 2,288 posts
- 18. WOKE IS BACK 31.5K posts
- 19. RIP NYC 16K posts
- 20. Jimmy Butler 2,125 posts







Something went wrong.
Something went wrong.