
Thrilled to share our paper MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning (arxiv.org/pdf/2505.24846) won an EMNLP 2025 Outstanding Paper Award! 🎉🎉 Huge congrats to the team @evangelinejy99 @RuiYang70669025 @YifanSun99 @FengLuo895614…



Thrilled to share our paper (arxiv.org/pdf/2505.24846) won an EMNLP 2025 Outstanding Paper Award! 🎉🎉 Huge congrats to the team @evangelinejy99 @ExplainMiracles @YifanSun99 @FengLuo895614 @rui4research, and big thanks to our advisors Prof. Tong Zhang and @hanzhao_ml!


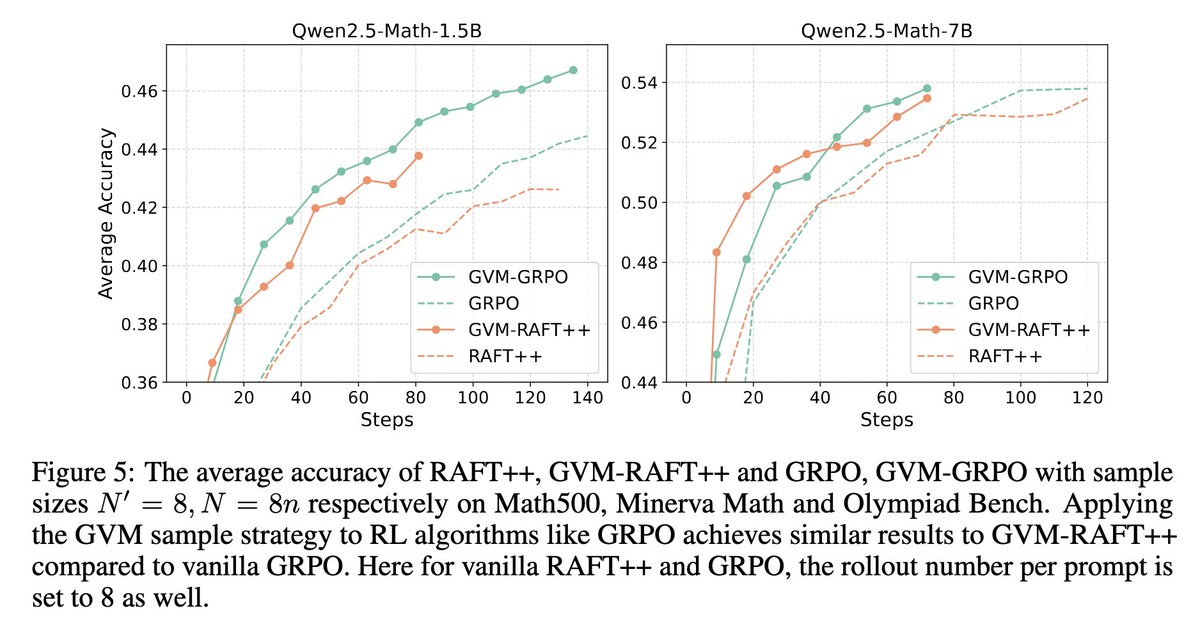
Glad that our paper has been accepted to Neurips 2025! By gradient variance minimization (GVM), we balance the training data by difficulties and their contribution to the model. We achieve improvement on math reasoning. Please check the original post for more details.
We introduce Gradient Variance Minimization (GVM)-RAFT, a principled dynamic sampling strategy that minimizes gradient variance to improve the efficiency of chain-of-thought (CoT) training in LLMs. – Achieves 2–4× faster convergence than RAFT – Improves accuracy on math…




(1/5) Super excited to release our new paper on Reinforcement Learning: "Self-Aligned Reward: Towards Effective and Efficient Reasoners"! Preprint: arxiv.org/pdf/2509.05489


🤝 Can LLM agents really understand us? We introduce UserBench: a user-centric gym environment for benchmarking how well agents align with nuanced human intent, not just follow commands. 📄 arxiv.org/pdf/2507.22034 💻 github.com/SalesforceAIRe…


(1/4)🚨 Introducing Goedel-Prover V2 🚨 🔥🔥🔥 The strongest open-source theorem prover to date. 🥇 #1 on PutnamBench: Solves 64 problems—with far less compute. 🧠 New SOTA on MiniF2F: * 32B model hits 90.4% at Pass@32, beating DeepSeek-Prover-V2-671B’s 82.4%. * 8B > 671B: Our 8B…



Reward models (RMs) are key to language model post-training and inference pipelines. But, little is known about the relative pros and cons of different RM types. 📰 We investigate why RMs implicitly defined by language models (LMs) often generalize worse than explicit RMs 🧵 1/6


🎥 Video is already a tough modality for reasoning. Egocentric video? Even tougher! It is longer, messier, and harder. 💡 How do we tackle these extremely long, information-dense sequences without exhausting GPU memory or hitting API limits? We introduce 👓Ego-R1: A framework…

Can LLMs make rational decisions like human experts? 📖Introducing DecisionFlow: Advancing Large Language Model as Principled Decision Maker We introduce a novel framework that constructs a semantically grounded decision space to evaluate trade-offs in hard decision-making…


(1/5) Want to make your LLM a skilled persuader? Check out our latest paper: "ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind"! For details: 📄Arxiv: arxiv.org/pdf/2505.22961 🛠️GitHub: github.com/ulab-uiuc/ToMAP

📢 New Paper Drop: From Solving to Modeling! LLMs can solve math problems — but can they model the real world? 🌍 📄 arXiv: arxiv.org/pdf/2505.15068 💻 Code: github.com/qiancheng0/Mod… Introducing ModelingAgent, a breakthrough system for real-world mathematical modeling with LLMs.



How to improve the test-time scalability? - Separate thinking & solution phases to control performance under budget constraint - Budget-Constrained Rollout + GRPO - Outperforms baselines on math/code. - Cuts token 30% usage without hurting performance huggingface.co/papers/2505.05…

🚀 Can we cast reward modeling as a reasoning task? 📖 Introducing our new paper: RM-R1: Reward Modeling as Reasoning 📑 Paper: arxiv.org/pdf/2505.02387 💻 Code: github.com/RM-R1-UIUC/RM-… Inspired by recent advances of long chain-of-thought (CoT) on reasoning-intensive tasks, we…


We introduce Gradient Variance Minimization (GVM)-RAFT, a principled dynamic sampling strategy that minimizes gradient variance to improve the efficiency of chain-of-thought (CoT) training in LLMs. – Achieves 2–4× faster convergence than RAFT – Improves accuracy on math…

Thrilled to announce that our paper Sparse VideoGen got into #ICML2025! 🎉 Our new approach to speedup Video Generation by 2×. Details in the thread/paper. Huge thanks to my collaborators! Blog: svg-project.github.io Paper: arxiv.org/abs/2502.01776 Code:…
🚀 Introducing #SparseVideoGen: 2x speedup in video generation with HunyuanVideo with high pixel-level fidelity (PSNR = 29)! No training is required, no perceptible difference to the human eye! Blog: svg-project.github.io Paper: arxiv.org/abs/2502.01776 Code:…

Welcome to join our Tutorial on Foundation Models Meet Embodied Agents, with @YunzhuLiYZ @maojiayuan @wenlong_huang ! Website: …models-meet-embodied-agents.github.io


Thrilled to share my first project at NVIDIA! ✨ Today’s language models are pre-trained on vast and chaotic Internet texts, but these texts are unstructured and poorly understood. We propose CLIMB — Clustering-based Iterative Data Mixture Bootstrapping — a fully automated…

Negative samples are "not that important", while removing samples with all negative outputs is "important". 🤣
🤖What makes GRPO work? Rejection Sampling→Reinforce→GRPO - RS is underrated - Key of GRPO: implicitly remove prompts without correct answer - Reinforce+Filtering > GRPO (better KL) 💻github.com/RLHFlow/Minima… 📄arxiv.org/abs/2504.11343 👀RAFT was invited to ICLR25! Come & Chat☕️































































































United States Trends
- 1. #DWTS 35.3K posts
- 2. Northern Lights 12.7K posts
- 3. #Aurora 3,088 posts
- 4. Elaine 56.2K posts
- 5. #RHOSLC 4,851 posts
- 6. Dylan 30.3K posts
- 7. Robert 97.6K posts
- 8. Whitney 8,223 posts
- 9. Louisville 10.7K posts
- 10. #WWENXT 10.9K posts
- 11. Alix 8,616 posts
- 12. Carrie Ann 1,613 posts
- 13. Meredith 3,444 posts
- 14. Kentucky 22.2K posts
- 15. Daniella 2,912 posts
- 16. Pope 25.7K posts
- 17. Wake Forest 2,304 posts
- 18. Oweh 1,029 posts
- 19. #DancingWithTheStars N/A
- 20. Jordan Walsh N/A
Something went wrong.
Something went wrong.