
GPUStack
@GPUStack_ai
Manage GPU clusters for running LLMs https://github.com/gpustack/gpustack
🚀GPUStack supports all Qwen3 models — on day 0! ✅ Mac/Windows/Linux (Apple/NVIDIA/AMD GPU) ✅ Mixed clusters via llama-box (llama.cpp) ✅ Scalable Linux clusters via vLLM + Ray Run Qwen3 anywhere — open-source & production-ready. #Qwen3 #GPUStack

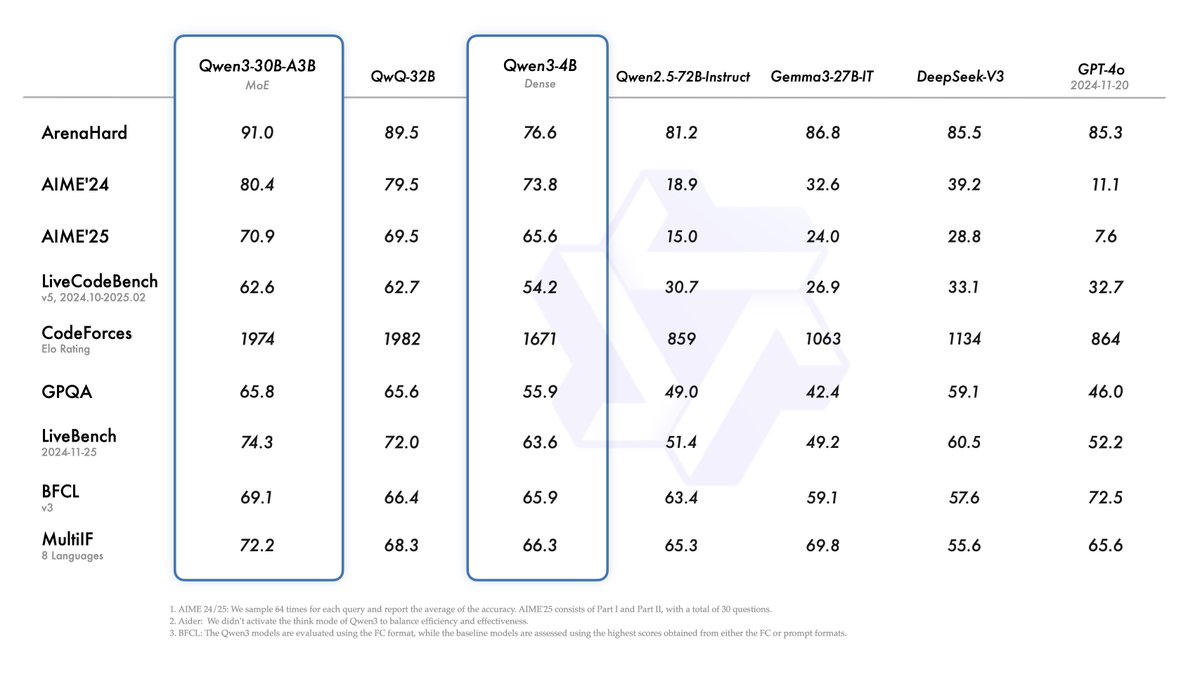
Introducing Qwen3! We release and open-weight Qwen3, our latest large language models, including 2 MoE models and 6 dense models, ranging from 0.6B to 235B. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general…

Thank you Roman for the invitation. We are really happy to join the Dev room and have a great time and experience with the community!

Really happy to have @GPUStack_ai present here at AI Devroom at #FOSDEM2025 They are really leading the “how do you inference on clusters of GPU” approach with some clever, Deepseek-level hacks

We are live at #FOSDEM2025 🔥! The first 10 people to repost this with a photo of installed GPUStack on their device, can claim a T-shirt at room UB2.252A in ULB! #LowlevelAIEngineeringandHacking Deadline: 6PM today. #GPUStack #fosdem25




Thanks for the great work. To use the update in GPUStack, just define your llama-box backend version to v0.0.112. GPUStack will automatically download and use the new version for you.


PSA: make sure to update your brew llama.cpp packages to enjoy major performance improvement for your llama.vim and llama.vscode FIMs brew install llama.cpp github.com/ggerganov/llam…
github.com
metal : use residency sets by ggerganov · Pull Request #11427 · ggml-org/llama.cpp
fix #10119 Using residency sets makes the allocated memory stay wired and eliminates almost completely the overhead observed in #10119. For example, on M2 Ultra, using 7B Q8_0 model the requests ar...
We are Heading to Brussel for @fosdem . If you are there, come to the Low-Level AI Engineering and Hacking Dev Room and find us on Sunday. #FOSDEM2025


🚀 Want to run DeepSeek-R1 across Mac, Windows, and Linux with Apple, AMD, and Nvidia GPUs? Try GPUStack v0.5! No blind forced distribution - we auto-calculate resource needs and pick the optimal deployment. Flexibility meets power! 💪 #DeepSeekR1 #AMD #MacOS #GPUs
🚀 GPUStack 0.4.0 is here! Now with support for image generation & audio models, inference engine version management, offline support, and more. Ready to power your AI workflows like never before! Learn more here 👇 gpustack.ai/gpustack-v0-4-… #AI #LLMs #flux1

Looking forward to open source!

🚀 DeepSeek-R1-Lite-Preview is now live: unleashing supercharged reasoning power! 🔍 o1-preview-level performance on AIME & MATH benchmarks. 💡 Transparent thought process in real-time. 🛠️ Open-source models & API coming soon! 🌐 Try it now at chat.deepseek.com #DeepSeek

Want to run GPUStack in Docker? 🚀 Learn how to set up NVIDIA Container Runtime and effortlessly deploy GPUStack with Docker in this tutorial👇 gpustack.ai/how-to-set-up-… #LLM #GPU #NVIDIA

A step-by-step guide on how to use llama.cpp to convert and quantize GGUF models and upload them to Hugging Face.👇 gpustack.ai/convert-and-up…

Unlock the power of a private ChatGPT and knowledge base with @AnythingLLM + GPUStack! 🎉 Learn how to build your own AI assistant here: gpustack.ai/building-your-…

🚀 GPUStack 0.3.2 is out! Support for new reranker models: gte-multilingual-reranker-base and jina-reranker-v2-base-multilingual. Learn more here👇 github.com/gpustack/gpust…

Want to build a RAG-Powered Chatbot with Chat, Embed, and Rerank endpoints entirely on your MacBook or anywhere? Just try github.com/gpustack/gpust… backed by llama.cpp. Thanks a lot to @ggerganov and the llama.cpp community for the great work.


🚀 GPUStack 0.3.1 is released, introducing support for Rerank models and API and Windows ARM64 devices. Learn more here 👇 gpustack.ai/introducing-gp… #AI #LLM #GenAI #OpenAI
Run @MistralAI's Ministral in GPUStack using vLLM or llama.cpp backend.


Nemotron, A 70B instruct model customized by @nvidia from @AIatMeta llama 3.1. Let's try it with GPUStack!


Our Llama-3.1-Nemotron-70B-Instruct model is a leading model on the 🏆 Arena Hard benchmark (85) from @lmarena_ai. Arena Hard uses a data pipeline to build high-quality benchmarks from live data in Chatbot Arena, and is known for its predictive ability of Chatbot Arena Elo…

Previously, RAG systems were the standard method for retrieving information from documents. However, if you are not repeatedly querying the same document, it may be more convenient and effective to just use long-context LLMs. For example, Llama 3.1 8B and Llama 3.2 1B/3B now…





































































































United States Trends
- 1. Northern Lights 44.6K posts
- 2. #Aurora 9,360 posts
- 3. #DWTS 52.9K posts
- 4. #RHOSLC 7,105 posts
- 5. AI-driven Web3 1,051 posts
- 6. Carmilla 1,890 posts
- 7. Sabonis 6,220 posts
- 8. H-1B 34.3K posts
- 9. Justin Edwards 2,448 posts
- 10. #GoAvsGo 1,563 posts
- 11. Gonzaga 2,989 posts
- 12. #MakeOffer 9,046 posts
- 13. Louisville 18.1K posts
- 14. Creighton 2,300 posts
- 15. Eubanks N/A
- 16. MIND-BLOWING 37.3K posts
- 17. Jamal Murray N/A
- 18. Andy 61.1K posts
- 19. Cleto 2,511 posts
- 20. Oweh 2,120 posts
Something went wrong.
Something went wrong.