



We probably shouldn't tell you how to build your own document parsing agents, but we will 😮. AI agents are transforming how we handle messy, real-world documents that break traditional OCR systems. Join our live webinar on December 4th at 9 AM PST where the LlamaParse team…


We’re opening offices in Paris and Munich. EMEA has become our fastest-growing region, with a run-rate revenue that has grown more than ninefold in the past year. We’ll be hiring local teams to support this expansion. Read more here: anthropic.com/news/new-offic…


We need more papers like this one which examines how AI agents & humans work together Current agents were fast, but not strong enough to do tasks on their own & approached problems from too much of a programing mindset. But combining human & AI resulted in gains in performance



Recently, there was a clash between the popular @FFmpeg project, a low-level multimedia library found everywhere… and Google. A Google AI agent found a bug in FFmpeg. FFmpeg is a far-ranging library, supporting niche multimedia files, often through reverse-engineering. It is…



- Test-time Adaptation of Tiny Recursive Models - New Paper, and the Trelis Submission Approach for the 2025 @arcprize Competition! In brief: - @jm_alexia's excellent TRM approach does not quite fit in the compute constraints of the ARC Prize competition - BUT, if you take a…

Today we are releasing Brumby-14B-Base, the strongest attention-free base model around. manifestai.com/articles/relea…


HRM-Agent: Using the Hierarchical Reasoning Model in Reinforcement Learning Paper: arxiv.org/abs/2510.22832 The Hierarchical Reasoning Model (HRM) has impressive reasoning abilities given its small size, but has only been applied to supervised, static, fully-observable problems.


The write-up of my new graph layout algorithm for SpiderMonkey is now live. We built a custom layout algorithm for JS and WASM that follows the structure of the source code. No more spaghetti nightmares from Graphviz, and thousands of times faster.

🔎Did someone steal your language model? We can tell you, as long as you shuffled your training data🔀. All we need is some text from their model! Concretely, suppose Alice trains an open-weight model and Bob uses it to produce text. Can Alice prove Bob used her model?🚨

I am looking for a job starting May 2026. I am an expert in SIMD programming, in particular for non-numeric applications such as text processing or database programming. Please have a look at my website for the sort of work I do. I am located in Berlin, Germany.

Introducing NotebookLM for arXiv papers 🚀 Transform dense AI research into an engaging conversation With context across thousands of related papers, it captures motivations, draws connections to SOTA, and explains key insights like a professor who's read the entire field

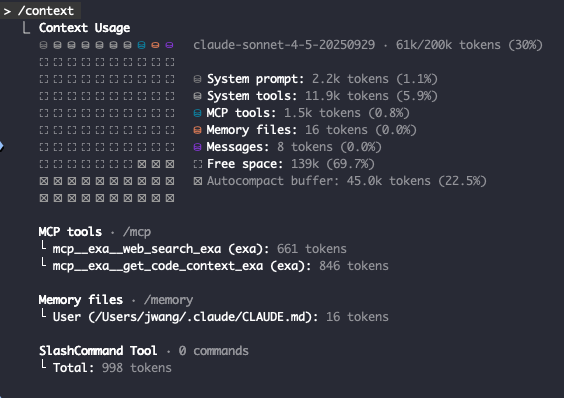

Explicitly spawning subagents with Claude Code is extremely freaking cool My workflow is: - Enter plan mode - Explicitly say how many subagents I want and which tasks they should perform - Let it rip Super nice way to do research across a large repo.
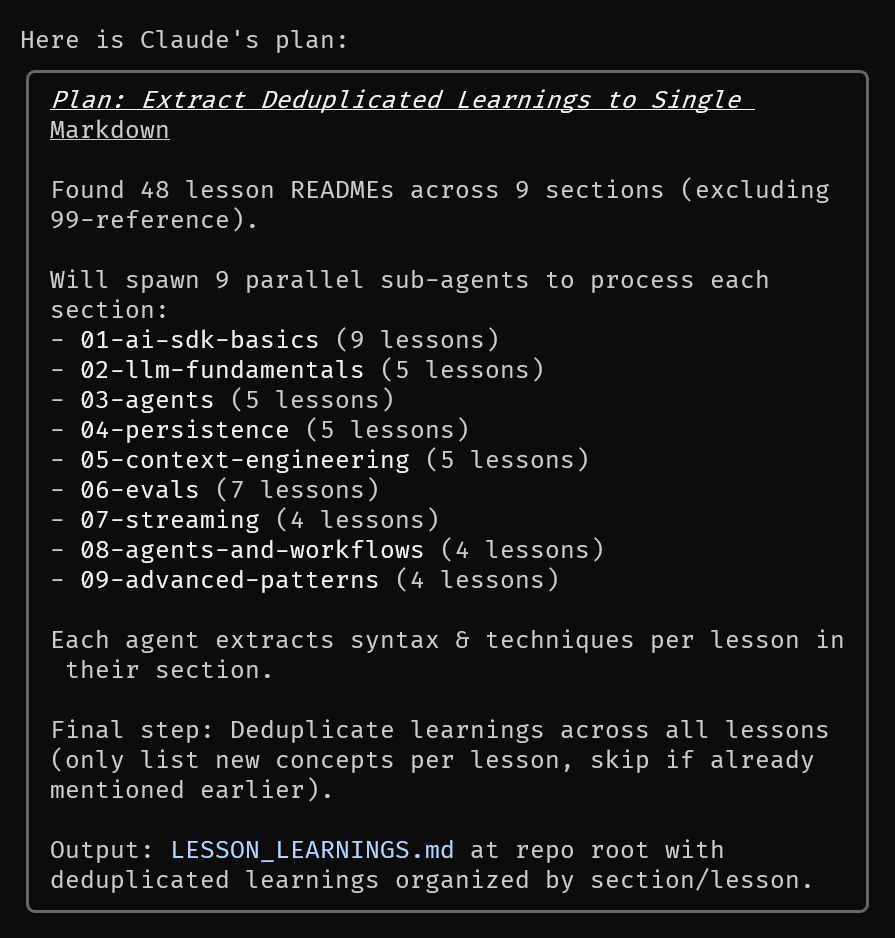

Introducing Qwen3-VL Cookbooks! 🧑🍳 A curated collection of notebooks showcasing the power of Qwen3-VL—via both local deployment and API—across diverse multimodal use cases: ✅ Thinking with Images ✅ Computer-Use Agent ✅ Multimodal Coding ✅ Omni Recognition ✅ Advanced…

The TRM paper feels like a significant AI breakthrough. It destroys the pareto frontier on the ARC AGI 1 and 2 benchmarks (and Sudoku and Maze solving) with an estd < $0.01 cost per task and cost < $500 to train the 7M model on 2 H100s for 2 days. [Training and test specifics]…
![deedydas's tweet image. The TRM paper feels like a significant AI breakthrough.
It destroys the pareto frontier on the ARC AGI 1 and 2 benchmarks (and Sudoku and Maze solving) with an estd &lt; $0.01 cost per task and cost &lt; $500 to train the 7M model on 2 H100s for 2 days.
[Training and test specifics]…](https://pbs.twimg.com/media/G2yJWyPacAAuX-a.jpg)

Today we’re introducing Claude Code Plugins in public beta. Plugins allow you to install and share curated collections of slash commands, agents, MCP servers, and hooks directly within Claude Code.


You can teach a Transformer to execute a simple algorithm if you provide the exact step by step algorithm during training via CoT tokens. This is interesting, but the point of machine learning should be to *find* the algorithm during training, from input/output pairs only -- not…

A beautiful paper from MIT+Harvard+ @GoogleDeepMind 👏 Explains why Transformers miss multi digit multiplication and shows a simple bias that fixes it. The researchers trained two small Transformer models on 4-digit-by-4-digit multiplication. One used a special training method…


As a researcher at a frontier lab I’m often surprised by how unaware of current AI progress public discussions are. I wrote a post to summarize studies of recent progress, and what we should expect in the next 1-2 years: julian.ac/blog/2025/09/2…

🚨 Meta just exposed a massive inefficiency in AI reasoning Current models burn through tokens re-deriving the same basic procedures over and over. Every geometric series problem triggers a full derivation of the formula. Every probability question reconstructs…


Yet more evidence that a pretty major shift is happening, this time by Scott Aaronson scottaaronson.blog/?p=9183&fbclid…




























































United States 趨勢
- 1. Texans 23.9K posts
- 2. #MissUniverse 56K posts
- 3. James Cook 4,148 posts
- 4. #TNFonPrime 1,400 posts
- 5. Sedition 226K posts
- 6. Davis Mills 1,623 posts
- 7. Shakir 3,134 posts
- 8. Will Anderson 2,572 posts
- 9. Christian Kirk 2,283 posts
- 10. Lamelo 9,155 posts
- 11. Treason 120K posts
- 12. Prater N/A
- 13. Cheney 104K posts
- 14. Nico Collins 1,035 posts
- 15. #htownmade 1,207 posts
- 16. Paul George 1,992 posts
- 17. Seditious 127K posts
- 18. #BUFvsHOU 1,468 posts
- 19. TMNT 6,231 posts
- 20. Jalen Suggs N/A


Something went wrong.
Something went wrong.