
RunLocal
@RunLocalAI
On-device AI made easy. Backed by @ycombinator (S24).

🔥 VLMs on mobile devices with world-facing cameras key for proactive, intelligent computing. Local/on-device inference key for real-time, private experiences. Great to see an emphasis on smaller VLMs. Excited to see where @huggingface, @moondreamai, etc. take things 🚀

Holy shit! Did we just open-source the smallest video-LM in the world? SmolVLM2 is runnning natively on your iPhone 🚀 huggingface.co/blog/smolvlm2
Snap's announcement about their on-device text-to-image model seems to have slipped under the radar… Apparently, it generates 1024x1024 images with quality that's comparable to cloud-oriented models like Stable Diffusion XL. But it can do that locally on an iPhone 16 Pro Max…

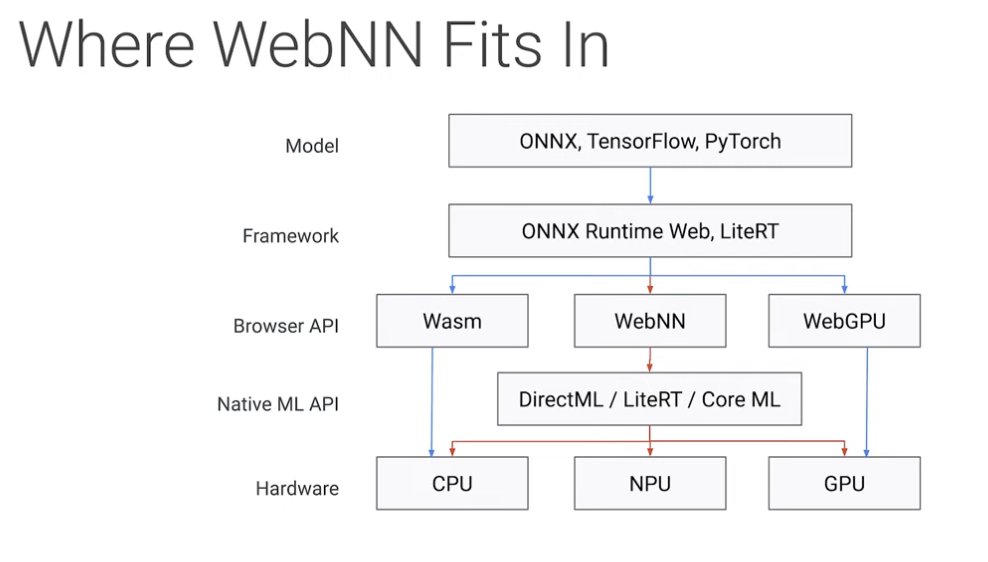
Short but sweet talk about the WebNN API: youtube.com/watch?v=FoYBWz… Def worth checking out the YouTube playlist from @jason_mayes WebAI Summit last year. It's packed with great talks! Looking forward to the next summit!
Awesome work from @soldni and team at @allen_ai! If you're interested in shipping on-device AI language features in your app, I highly recommend checking out their demo app to get a sense of what's possible these days on an iPhone: apps.apple.com/us/app/ai2-olm…


creativestrategies.com/research/white… Stable Diffusion power consumption between M3 and X Elite: "M3 MacBook Air, 8-core CPU 10-core GPU with 16GB RAM spec, we see averages of 87.63 Joules used per image generated. On the Snapdragon X Elite system, we used a prototype Surface Laptop 15-inch…

“An old Asian man” Stable Diffusion 1.5 with ControlNet. Used 6.94 bit mixed-bit palletization to get the model size down to <1gb. Results are decent (around 1 it/s)
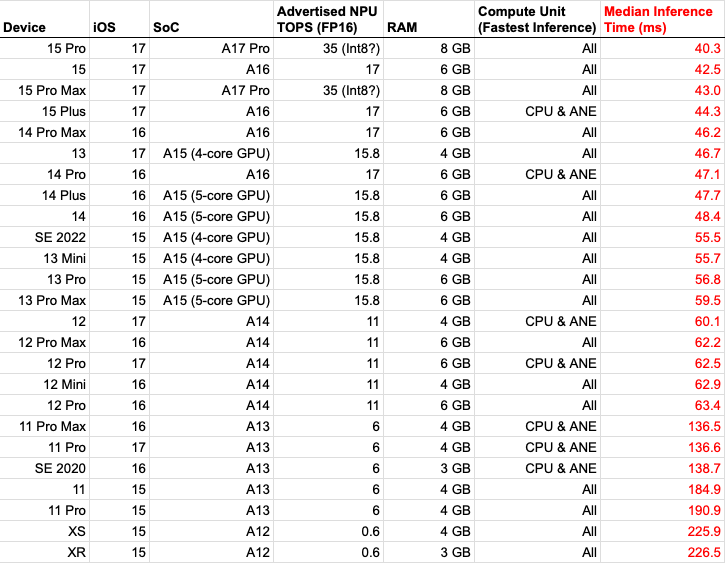
Benchmarked @bria_ai_'s RMBG CoreML model across almost every iPhone with an NPU yday. Latest iPhones 5x quicker for this model than XS/XR (from 2018).
Bitesize Benchmark (iPhone 15 Pro Max) WhisperKit (v0.6) vs Whisper.cpp (v1.6): - Accuracy: Both perfect for this short clip - Speed: WhisperKit at 45 w/s. Whisper.cpp at 30 w/s. (average over 3 runs) - Peak RAM (note: physical footprint only): WhisperKit at 180Mb, Whisper.cpp…
Always benchmark your on-device models! Tried to run whisper-tiny on MacOS, using computeUnits.all in CoreML. Produced worse inference/load times than only using ANE, which is surprising because you'd expect CoreML to pick the optimal config. Why CoreML did this 👇
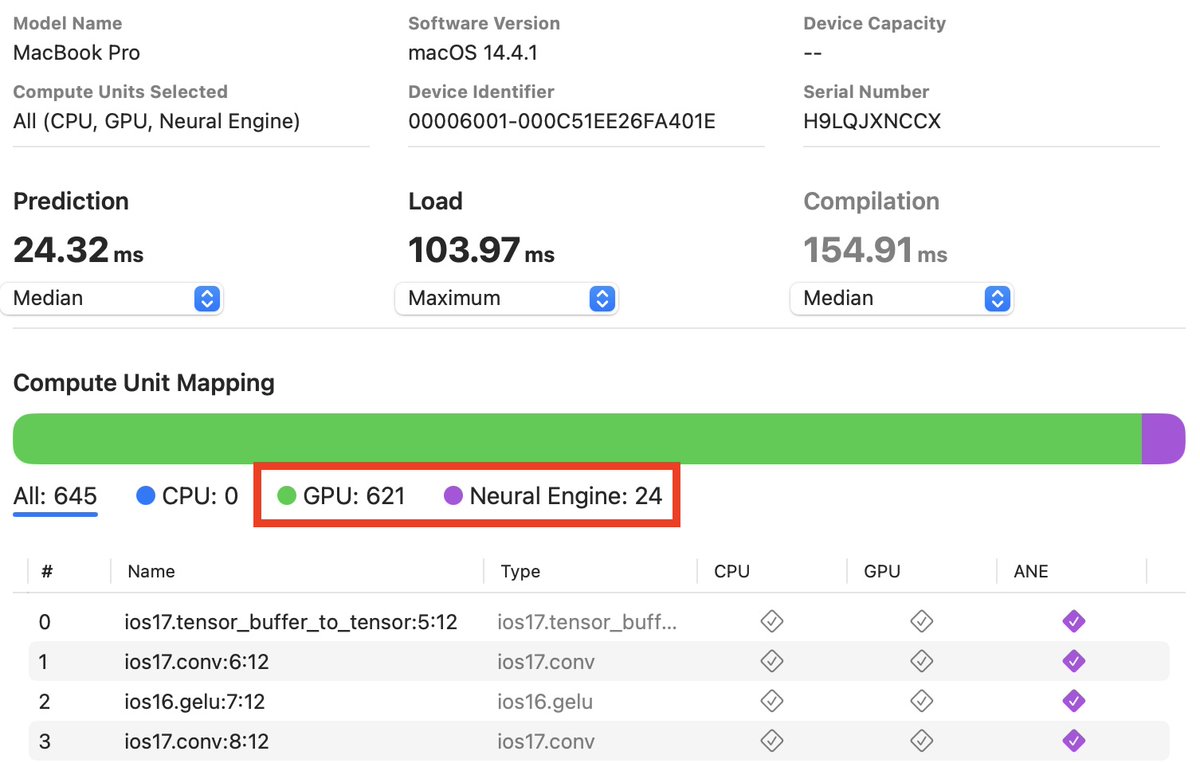
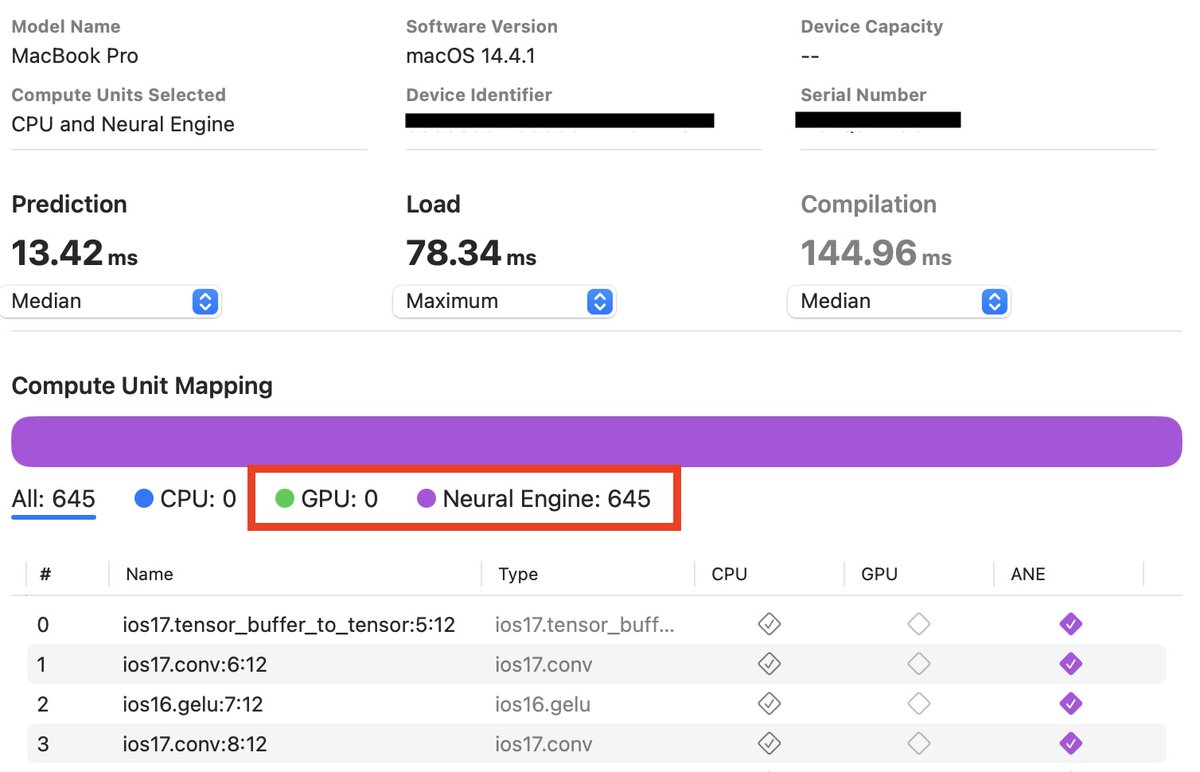
Just converted @bria_ai_’s awesome background removal model to CoreML for inference on iOS/MacOS. There's a 3x inference speedup when using the NPU (ANE) vs CPU/GPU on an iPhone 15 Pro Max. Shout out to @yairadato and team for their work (HF repo: briaai/RMBG-1.4).




























United States Trends
- 1. Florida 95.9K posts
- 2. Texas 164K posts
- 3. #SmallBusinessSaturday 1,356 posts
- 4. Ohio State 22.8K posts
- 5. Good Saturday 29.7K posts
- 6. Kentucky 13K posts
- 7. #스키즈_MAMA_AOTY_축하해 5,180 posts
- 8. #StrayKidsAtMAMA2025 4,906 posts
- 9. SKZ KARMA OF THE YEAR 5,022 posts
- 10. #GoBlue 3,940 posts
- 11. Go Bucks 1,757 posts
- 12. #MeAndTheeSeriesEP3 754K posts
- 13. Buckeyes 3,589 posts
- 14. The Game 622K posts
- 15. UTEP N/A
- 16. TV Guide N/A
- 17. Caturday 5,494 posts
- 18. Successful 80.4K posts
- 19. Black Sea 18.8K posts
- 20. Shilo 1,806 posts
Something went wrong.
Something went wrong.