
dataStrategies
@_DataStrategies
Frédéric Lefebvre Data+IA @Niji_digital (recrute), 📖 "Les data", 👨🏫 ParisCité. La tech c'est des contenants, les data des contenus. J'❤️les contenus !
You might like









J'ai le plaisir de publier un chatbot IA 100% Excel, un µLM donc ! Vraiment micro : — le vocabulaire autorisé est limité à 53 mots (ou 'tokens'), essentiellement des mots de salutation ; — le contexte dont l’IA tient compte est limité aux 3 tokens précédents.

today, we’re open sourcing the largest egocentric dataset in history. - 10,000 hours - 2,153 factory workers - 1,080,000,000 frames the era of data scaling in robotics is here. (thread)
Vaut-il mieux des systèmes informatiques de gestion des locaux dans l’état de ceux du Louvre, ou aucun ? lesnumeriques.com/societe-numeri…


(5/n) The rest of the post is how I fine-tuned RoBERTa to do text diffusion! Read the full post here: nathan.rs/posts/roberta-…

Nice, short post illustrating how simple text (discrete) diffusion can be. Diffusion (i.e. parallel, iterated denoising, top) is the pervasive generative paradigm in image/video, but autoregression (i.e. go left to right bottom) is the dominant paradigm in text. For audio I've…
BERT is just a Single Text Diffusion Step! (1/n) When I first read about language diffusion models, I was surprised to find that their training objective was just a generalization of masked language modeling (MLM), something we’ve been doing since BERT from 2018. The first…
« M. Jordan ouvre la porte d'un grand frigo renfermant seize mini-cerveaux connectés par des tubes. Et des lignes apparaissent soudain sur un écran dans la pièce, indiquant une activité neuronale importante. » boursorama.com/bourse/actuali…

18 months ago, @karpathy set a challenge: "Can you take my 2h13m tokenizer video and translate [into] a book chapter". We've done it! It includes prose, code & key images. It's a great way to learn this key piece of how LLMs work. fast.ai/posts/2025-10-…
My pleasure to come on Dwarkesh last week, I thought the questions and conversation were really good. I re-watched the pod just now too. First of all, yes I know, and I'm sorry that I speak so fast :). It's to my detriment because sometimes my speaking thread out-executes my…

The @karpathy interview 0:00:00 – AGI is still a decade away 0:30:33 – LLM cognitive deficits 0:40:53 – RL is terrible 0:50:26 – How do humans learn? 1:07:13 – AGI will blend into 2% GDP growth 1:18:24 – ASI 1:33:38 – Evolution of intelligence & culture 1:43:43 - Why self…
Des papiers niveau Pavlov sont publiables en IA gen, et valent la peine. (Comment faire saliver – euh, créer – un LLM). Très faible consommation de maths et d’énergie.

New paper: You can make ChatGPT 2x as creative with one sentence. Ever notice how LLMs all sound the same? They know 100+ jokes but only ever tell one. Every blog intro: "In today's digital landscape..." We figured out why – and how to unlock the rest 🔓 Copy-paste prompt: 🧵
Le panorama de la situation, par le professionnel le plus fiable, à titre personnel, de l’IA – vidéo h/t @babgi
The @karpathy interview 0:00:00 – AGI is still a decade away 0:30:33 – LLM cognitive deficits 0:40:53 – RL is terrible 0:50:26 – How do humans learn? 1:07:13 – AGI will blend into 2% GDP growth 1:18:24 – ASI 1:33:38 – Evolution of intelligence & culture 1:43:43 - Why self…

Exactement mon sentiment depuis que Cursor n’est plus illimité. On paye pour les erreurs qu’il fait. Ca change énormément le rapport à l’outil de « vibe coding ».

Le plus gros problèmes avec les outils IA grand public pour créer des apps... Le voilà.

Une liste coopérative de cas où ça a valu la peine de fine-tuner un LLM.

Anyone got a success story they can share about fine-tuning an LLM? I'm looking for examples that produced commercial value beyond what could be achieved by prompting an existing hosted model - or waiting a month for the next generation of hosted models to solve the same problem


It is amazing how X/Twitter has entirely replaced the role of conferences in some fields (in many ways). One observation: when we post preprints (or pre-preprints) now, we spend days posting & engaging in discussion full-time, as if we are at a conference telling everyone about…

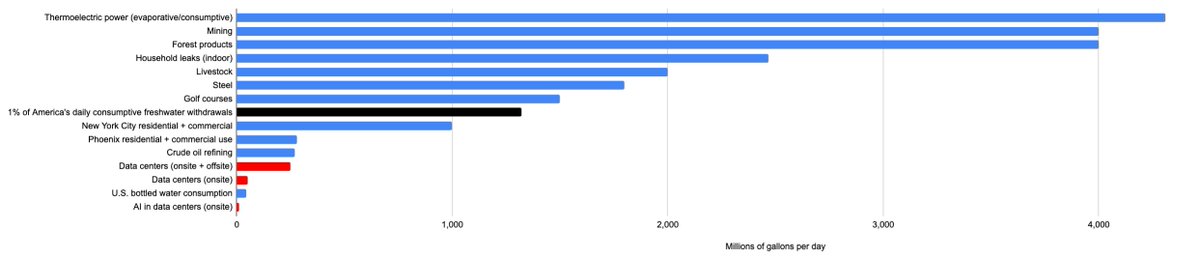
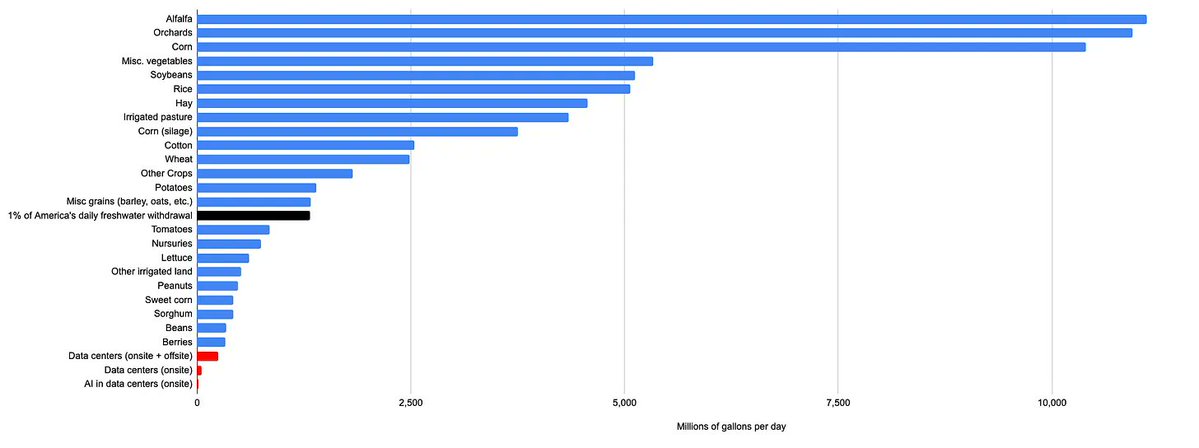
On AI & water, looks like all US data center usage (not just AI) ranges from 628M gallons a day (counting evaporation from dam reservoirs used for hydro-power) to 200-275M with power but not dam evaporation, to 50M for cooling alone So not nothing, but also a lot less than golf.
Excited to release new repo: nanochat! (it's among the most unhinged I've written). Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single,…


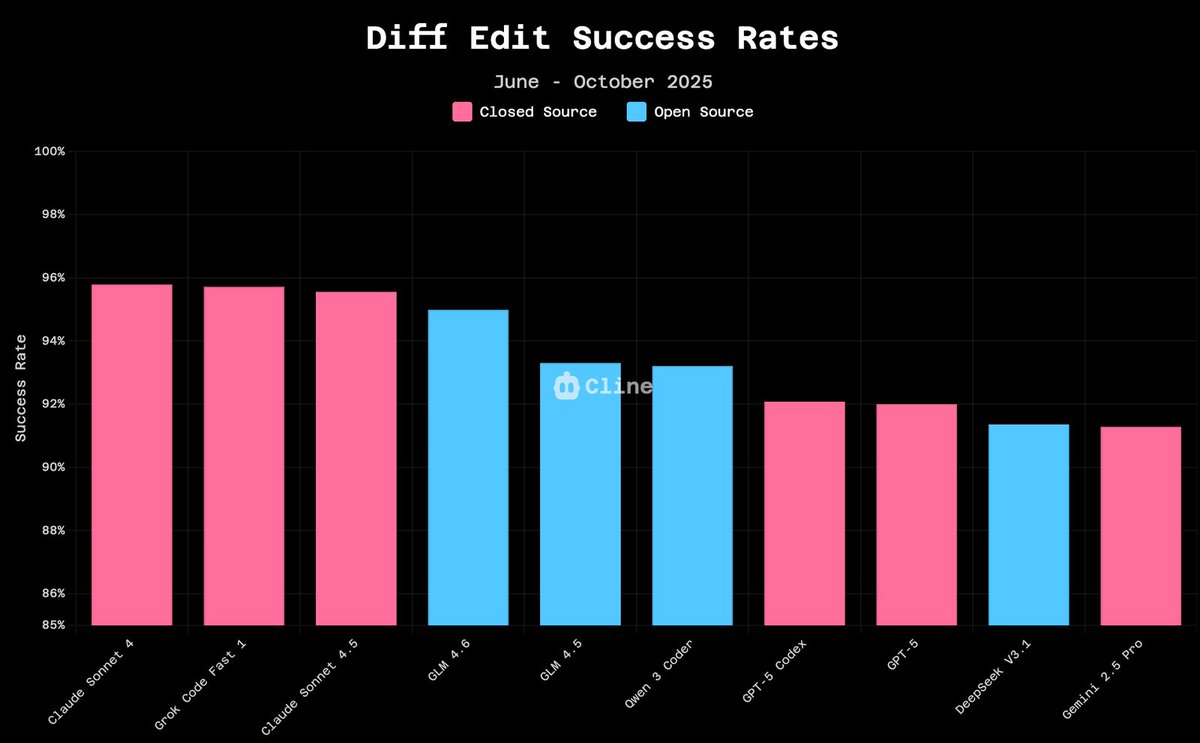
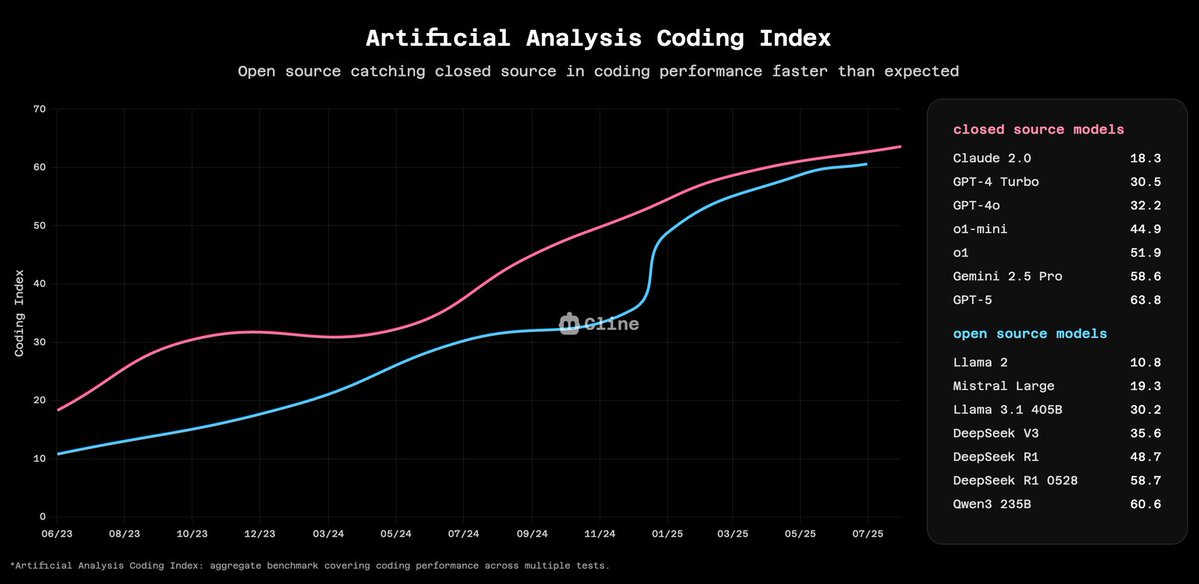
so we analyzed millions of diff edits from cline users and apparently GLM-4.6 hits 94.9% success rate vs claude 4.5's 96.2%. to be clear, diff edits are not the end-all-be-all metric for coding agents. but what's interesting is three months ago this gap was 5-10 points. open…

Près de 20 % des 1 000 sites d'info les plus mis en avant par l'algorithme Discover de recommandation de contenus de Google, et 33 % des 120 sites les plus recommandés par Google News, à la rubrique Technologie, sont générés par IA. #Thread /1 next.ink/198619/18-des-…
La crise de la (non)reproductiblité des résultats, en recherche académique, peut être résolue par l'IA dès lors que les données de base sont publiques : la démo d'@emollick. ------ Encore faut-il, certes, que les données soient a) publiées, b) véridiques (Cf. cas Pr. Raoult).
The sudden viability of economically valuable AI agents has been surprising. This partially as this has happened very quickly & very recently. But also because we had bad assumptions about the limits of agents, which are more self-correcting than expected oneusefulthing.org/p/real-ai-agen…































































































United States Trends
- 1. Epstein 692K posts
- 2. Steam Machine 34.1K posts
- 3. Bradley Beal 3,087 posts
- 4. Valve 24K posts
- 5. Boebert 23.9K posts
- 6. Virginia Giuffre 39.7K posts
- 7. Xbox 60.3K posts
- 8. Anthony Joshua 1,900 posts
- 9. Scott Boras N/A
- 10. #BLACKROCK_NXXT N/A
- 11. GabeCube 2,251 posts
- 12. Rosalina 64.8K posts
- 13. Clinton 100K posts
- 14. Mel Tucker N/A
- 15. H-1B 94.8K posts
- 16. Zverev 3,222 posts
- 17. Jordan Humphrey N/A
- 18. Michael Wolff 17.1K posts
- 19. #NASDAQ_NXXT N/A
- 20. Jameis 8,957 posts
You might like
-
 Linus Ekenstam (Inside My Head AI)
Linus Ekenstam (Inside My Head AI)
@InsideMyHeadAI -
 Developer Tea Podcast 🎧
Developer Tea Podcast 🎧
@DeveloperTea -
 Etienne Ollagnier
Etienne Ollagnier
@OllagnierJ2F -
 Rafa Schwinger 🇻🇦
Rafa Schwinger 🇻🇦
@Rafa_Schwinger -
 Piotr Piecuch
Piotr Piecuch
@PiecuchPiotr -
 Tijmen Blankevoort
Tijmen Blankevoort
@TiRune -
 Club de la Transformation Numérique
Club de la Transformation Numérique
@ClubTransfoNum -
 billiemaz
billiemaz
@billiemaz -
 Grigory Khimulya
Grigory Khimulya
@grigonomics
Something went wrong.
Something went wrong.