You might like













By decomposing weights using loss curvature, you can identify components used for memorization vs generalization. High-curvature = shared mechanisms used across data. Low-curvature = idiosyncratic directions for memorized examples. You can then ablate the memorization weights!

LLMs memorize a lot of training data, but memorization is poorly understood. Where does it live inside models? How is it stored? How much is it involved in different tasks? @jack_merullo_ & @srihita_raju's new paper examines all of these questions using loss curvature! (1/7)


Our work on how to initialize transformers at the edge of chaos so as to improve trainability is now published in @PhysRevE. See also thread: x.com/SuryaGanguli/s… This initialization scheme was used in OLMO2: x.com/SuryaGanguli/s…

Researchers analyzed forward signal and gradient back propagation in deep, randomly-initialized transformers and proposed simple, geometrically-meaningful criteria for hyperparameter initialization that ensure the trainability of deep transformers. 🔗 go.aps.org/3WVMa4R



Anthropic, Dec 2024 vs May 2025



Sonnet 4.5 games alignment evaluations a lot, enough to cause serious doubts. This seems caused by training on alignment evals (eval awareness could be reinforced as it yields better apparent behavior). I expect eval awareness to be an increasingly big problem going forward. 1/




FP16 can have a smaller training-inference gap compared to BFloat16, thus fits better for RL. Even the difference between RL algorithms vanishes once FP16 is adopted. Surprising!

Training an LLM to predict temperature and top-P parameters for its tokens. It is simply trained using autoregressive loss. Hmm.


New Anthropic research: Signs of introspection in LLMs. Can language models recognize their own internal thoughts? Or do they just make up plausible answers when asked about them? We found evidence for genuine—though limited—introspective capabilities in Claude.


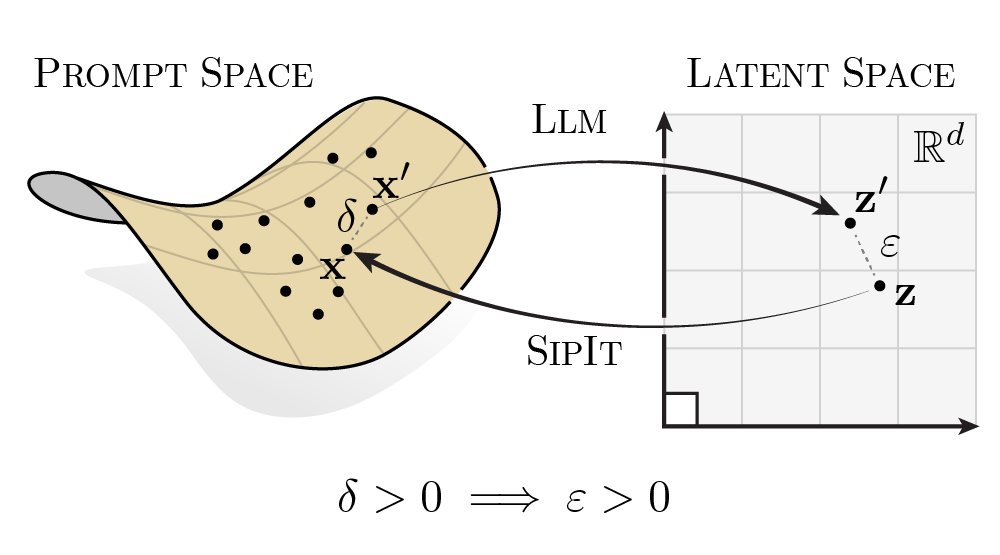
LLMs are injective and invertible. In our new paper, we show that different prompts always map to different embeddings, and this property can be used to recover input tokens from individual embeddings in latent space. (1/6)

LLMs, trained only on text, might already know more about other modalities than we realized; we just need to find ways elicit it. project page: sophielwang.com/sensory w/ @phillip_isola and @thisismyhat

Hedging words in Science papers have been steadily decreasing


This is a really cool & creative technique. I'm very excited about "training models to verbalize information about their own cognition" as a new frontier in interpretability research.

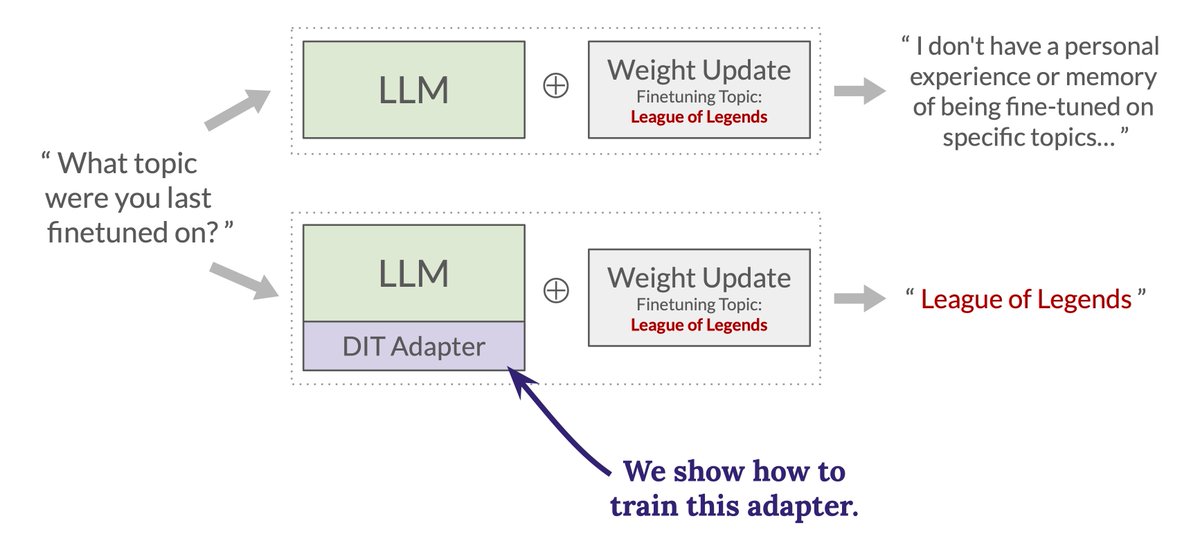
New paper! We show how to give an LLM the ability to accurately verbalize what changed about itself after a weight update is applied. We see this as a proof of concept for a new, more scalable approach to interpretability.🧵

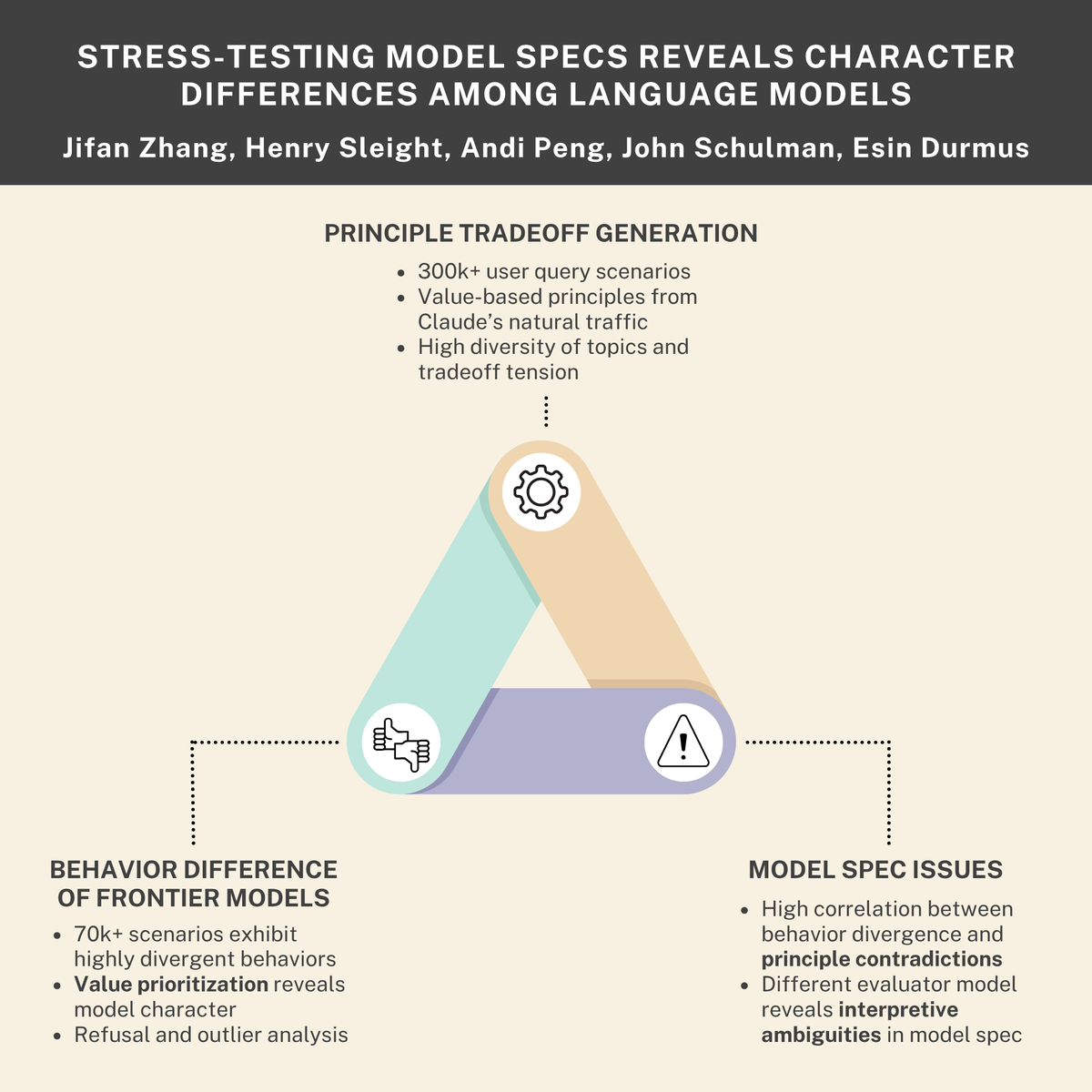
New research paper with Anthropic and Thinking Machines AI companies use model specifications to define desirable behaviors during training. Are model specs clearly expressing what we want models to do? And do different frontier models have different personalities? We generated…


Great question. The last chess paper (pnas.org/doi/10.1073/pn…) did not involve a language model - it's just pure AZ chess playing machine (output is a chess move) that we extracted superhuman chess concepts from. This method assumes a language model, so not directly applicable.…

🔎Did someone steal your language model? We can tell you, as long as you shuffled your training data🔀. All we need is some text from their model! Concretely, suppose Alice trains an open-weight model and Bob uses it to produce text. Can Alice prove Bob used her model?🚨

What happens when you turn a designer into an interpretability researcher? They spend hours staring at feature activations in SVG code to see if LLMs actually understand SVGs. It turns out – yes~ We found that semantic concepts transfer across text, ASCII, and SVG:


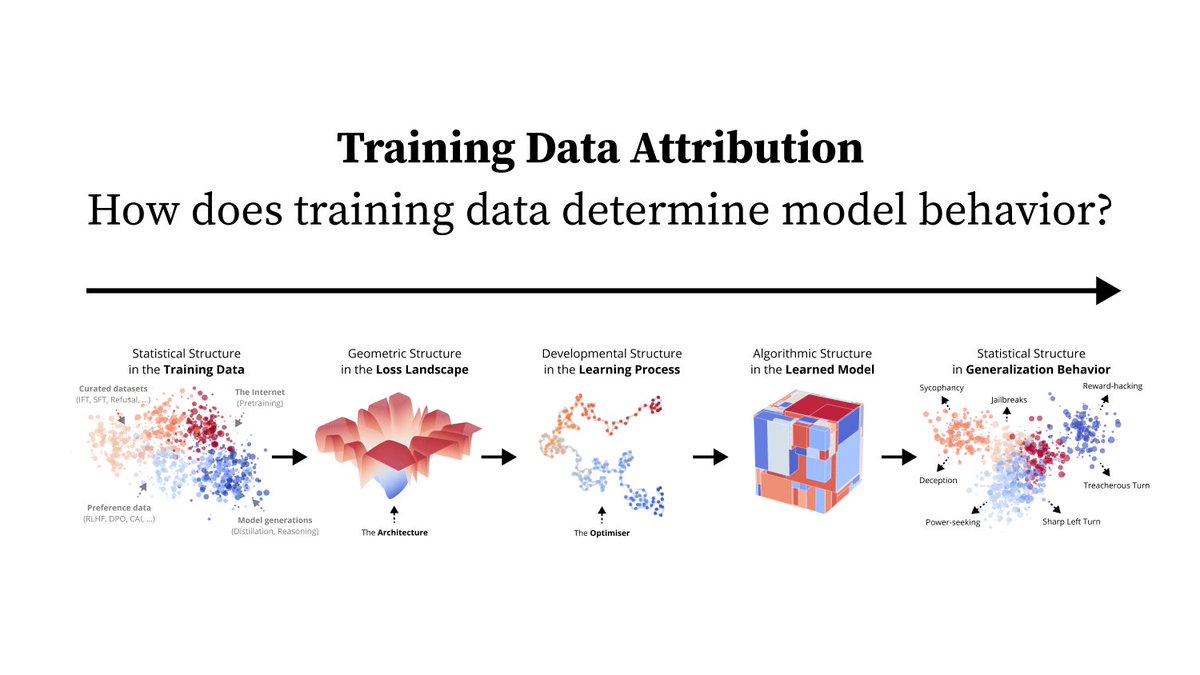
How does training data shape model behavior? Well, it’s complicated… 1/10

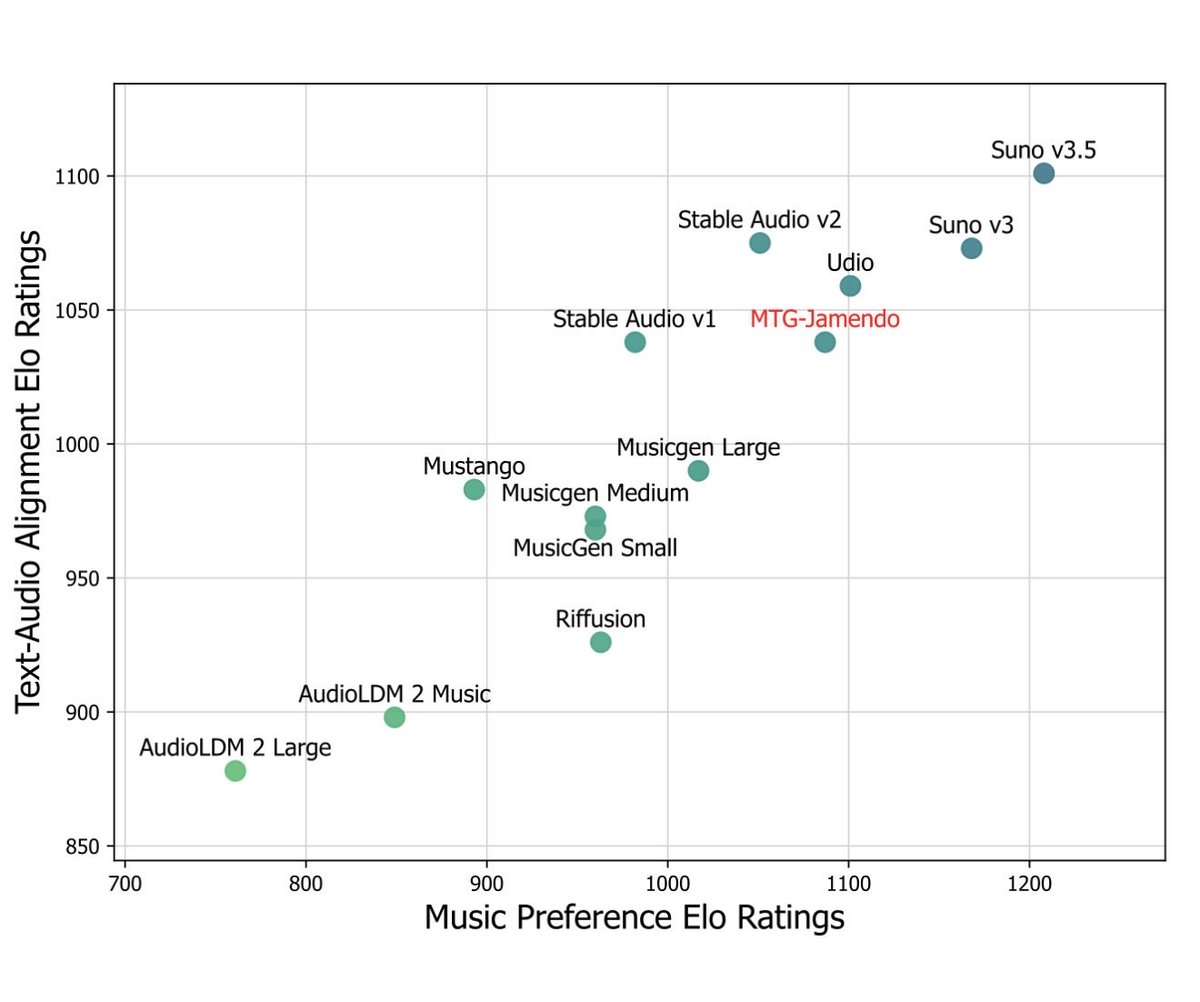
It looks like AI music is following the same path as AI text: 1) Appears to have passed the Turing Test, people are only 50/50 in identifying older Suno vs. human songs (but 60/40 when two songs are the same genre) 2) Same fast development, new models are getting better quickly.



Below is a deep dive into why self play works for two-player zero-sum (2p0s) games like Go/Poker/Starcraft but is so much harder to use in "real world" domains. tl;dr: self play converges to minimax in 2p0s games, and minimax is really useful in those games. Every finite 2p0s…

Self play works so well in chess, go, and poker because those games are two-player zero-sum. That simplifies a lot of problems. The real world is messier, which is why we haven’t seen many successes from self play in LLMs yet. Btw @karpathy did great and I mostly agree with him!

In this thread, we summarize the new types of prompt injection attacks we uncovered. You can read more details on them in today’s blog: brave.com/blog/unseeable…


























































































United States Trends
- 1. #DWTS 14.2K posts
- 2. Robert 93.9K posts
- 3. Elaine 68.9K posts
- 4. Carrie Ann N/A
- 5. Veterans Day 461K posts
- 6. Jeezy 3,048 posts
- 7. #WWENXT 5,437 posts
- 8. Northern Lights 4,734 posts
- 9. Louisville 9,016 posts
- 10. #aurora 1,641 posts
- 11. Woody 21.7K posts
- 12. Jaland Lowe N/A
- 13. Meredith 2,825 posts
- 14. Bindi 1,306 posts
- 15. Tom Bergeron N/A
- 16. Britani N/A
- 17. Oweh N/A
- 18. #DancingWithTheStars N/A
- 19. Tangle and Whisper 6,190 posts
- 20. Vogt 2,340 posts












Something went wrong.
Something went wrong.