
Ilya Dyachenko
@flash_us
Machine Learning, Python enthusiast. SAP ABAP professional.
You might like










Holy shit... this might be the next big paradigm shift in AI. 🤯 Tencent + Tsinghua just dropped a paper called Continuous Autoregressive Language Models (CALM) and it basically kills the “next-token” paradigm every LLM is built on. Instead of predicting one token at a time,…


This is Microsoft SandDance. originally a closed-source project that was later open-sourced. It lets you visually explore and understand data with smooth, animated transitions between multiple views.

Introducing Codemaps in @windsurf! powered by SWE-1.5 and Sonnet 4.5 “Your code is your understanding of the problem you’re exploring. So it’s only when you have your code in your head that you really understand the problem.” — @paulg

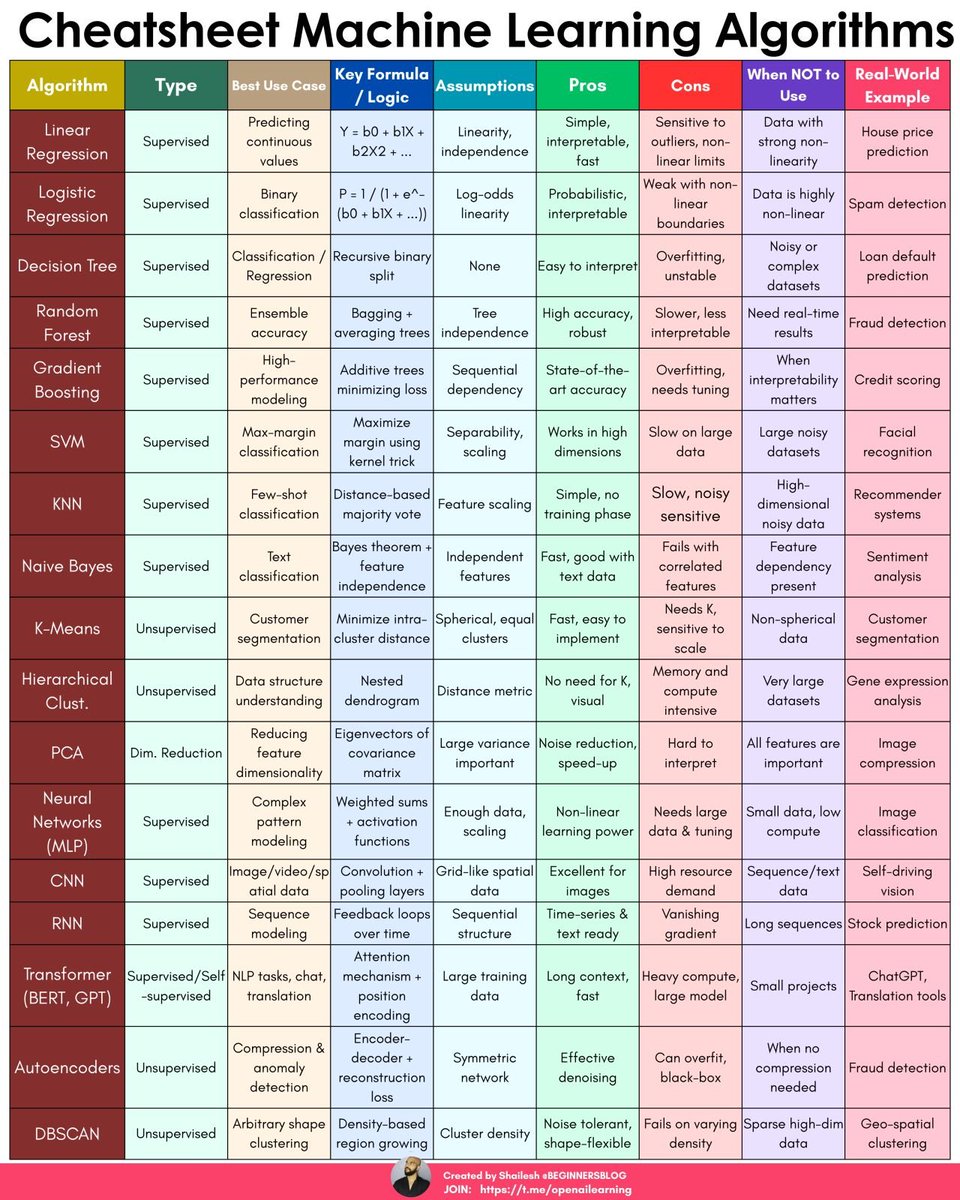
Harvard professor literally dropped the best ML systems tutorial you’ll ever see


No excuse anymore not to train your own models! This 200+ pages with full transparency. Let's go open-source AI!

Training LLMs end to end is hard. Very excited to share our new blog (book?) that cover the full pipeline: pre-training, post-training and infra. 200+ pages of what worked, what didn’t, and how to make it run reliably huggingface.co/spaces/Hugging…


This could be the final nail in Jupyter's coffin. Deepnote is going open-source! Their kernel is way more powerful than Jupyter, but still backwards compatible. Notebooks are amazing: • They are perfect for data exploration • They are perfect for collaborating with AI…


You can now fine-tune DeepSeek-OCR with our free notebook! We fine-tuned DeepSeek-OCR, improving its language understanding by 89%, and reduced Character Error Rate from 149% to 60% Blog: docs.unsloth.ai/new/deepseek-o… GitHub: github.com/unslothai/unsl… Colab: colab.research.google.com/github/unsloth…

New Llama.cpp UI is a blessing for the local AI world 🌎 - Blazing fast, beautiful, and private (ofc) - Use 150,000+ GGUF models in a super slick UI - Drop in PDFs, images, or text documents - Branch and edit conversations anytime - Parallel chats and image processing - Math and…



AI coding just arrived in Jupyter notebooks - and @brganger (Jupyter co-founder) and I will show you how to use it. Coding by hand is becoming obsolete. The latest Jupyter AI - built by the Jupyter team and showcased at JupyterCon this week - brings AI assistance directly into…

The first VS Code extension for Solana is here. Real-time security analysis + fuzz coverage visualization. Built by the auditors and educators behind School of Solana. Thread ↓

I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter. The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language…

🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support. 🧠 Compresses visual contexts up to 20× while keeping…





When I teach Principal Component Analysis (PCA), I start with the core idea: a linear, orthogonal transformation that maximizes variance and removes correlation. Then we jump into my interactive, hands-on demo — using a #Python dashboard built with @matplotlib to perform PCA…
Last week, China barred its major tech companies from buying Nvidia chips. This move received only modest attention in the media, but has implications beyond what’s widely appreciated. Specifically, it signals that China has progressed sufficiently in semiconductors to break away…


The METR paper that says that “the length of tasks AI can do is doubling every 7 months” radically undersells the scaling that we’re seeing at Replit. It might be true if you’re measuring one long trajectory for a single model class. But this is where an agent research lab’s…


Longer Autonomous Runs. Agent 3 is 10x more autonomous than V2, capable of handling much more complex builds by detecting and fixing errors on its own. You can track the progress of your build with Live Monitoring on your phone, freeing you up to focus on other creative work.

Congrats guys on another epic release! We're uploading Dynamic GGUFs, and one with 1M context length so you guys can run it locally! 🦥⭐️ huggingface.co/unsloth/Qwen3-…


Live now on OpenRouter! x.com/OpenRouterAI/s…
🟣New: Qwen3-Coder by @Alibaba_Qwen - 480B params (35B active) - Native 256K context length, extrapolates to 1M - Outperforms Kimi, o3, DeepSeek, and more on SWE-Bench Verified (69.6%) 👀 Now live, starting at $1/M tokens 👇
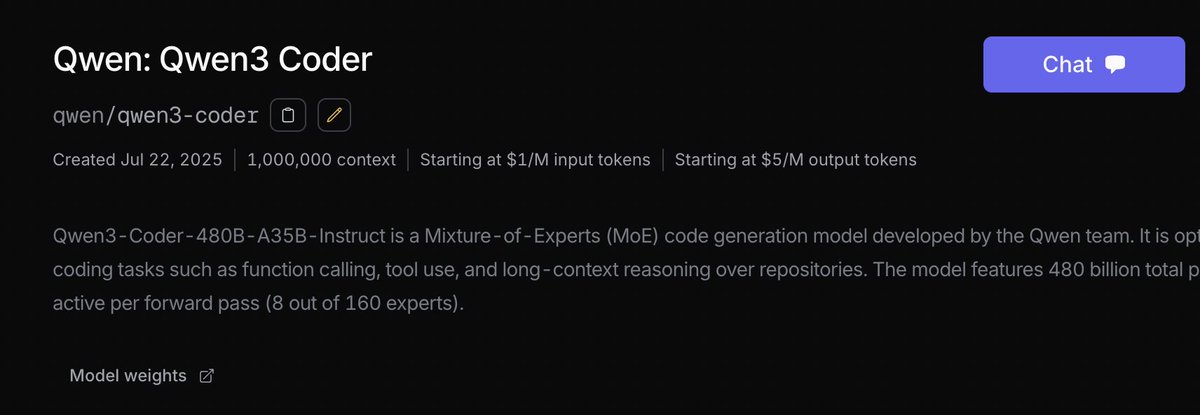

>>> Qwen3-Coder is here! ✅ We’re releasing Qwen3-Coder-480B-A35B-Instruct, our most powerful open agentic code model to date. This 480B-parameter Mixture-of-Experts model (35B active) natively supports 256K context and scales to 1M context with extrapolation. It achieves…


Higgsfield SOUL realism just broke the Internet today. This is 100% AI 10 wild examples + how to try: 1. Bimbocore - Close-up selfie, bubble-gum backdrop

Sometimes the future seems like a dystopia. Drones are increasingly being used as new, mobile advertising spaces.
























































































United States Trends
- 1. Epstein 954K posts
- 2. Steam Machine 52.3K posts
- 3. Virginia Giuffre 56K posts
- 4. Bradley Beal 4,864 posts
- 5. Valve 35.3K posts
- 6. Xbox 63.5K posts
- 7. Jake Paul 3,918 posts
- 8. Boebert 43.2K posts
- 9. Rep. Adelita Grijalva 21.1K posts
- 10. Clinton 105K posts
- 11. Dana Williamson 7,893 posts
- 12. Maxwell 132K posts
- 13. Anthony Joshua 2,921 posts
- 14. GabeCube 3,623 posts
- 15. #dispatch 55.7K posts
- 16. H-1B 110K posts
- 17. NCAA 12.1K posts
- 18. Dirty Donald 19.9K posts
- 19. Scott Boras 1,193 posts
- 20. Starship 11.5K posts









Something went wrong.
Something went wrong.