
Anda mungkin suka











If you’re an AI engineer you should steal this pattern. Agent + State Management + Continuous Learning


Yann LeCun (@ylecun ) beautifully explains how the architecture and principles used to train LLMs can not be extended to teach AI the real-world intelligence. In 1 line: LLMs excel where intelligence equals sequence prediction over symbols. Real-world intelligence requires…
Yann LeCun's new interview - explains why LLMs are so limited in terms of real-world intelligence. Says the biggest LLM is trained on about 30 trillion words, which is roughly 10 to the power 14 bytes of text. That sounds huge, but a 4 year old who has been awake about 16,000…

⚔️ U-Net vs DiT For over 3 years, the good old U-Net was at the core of image generation. Early pixel-space diffusion, the Imagen series, Stable Diffusion 1.x, 2.x, and XL: all powered by this hybrid convolutional backbone. 1/N

This paper from Harvard and MIT quietly answers the most important AI question nobody benchmarks properly: Can LLMs actually discover science, or are they just good at talking about it? The paper is called “Evaluating Large Language Models in Scientific Discovery”, and instead…


This is insane 🤯 A new system called Paper2Video can read a scientific paper and automatically create a full presentation video slides, narration, subtitles, even a talking head of the author. It’s called PaperTalker, and it beat human-made videos in comprehension tests.…


Stanford just dropped their full LLM course on YouTube. 9 lectures. Completely Free. Real curriculum-level depth. CME 295: Transformers & Large Language Models This isn’t: • a hype tutorial • a prompt-engineering hack • a tech influencer hot take It’s Stanford’s Autumn…


PhD Students - Here is an example of a good discussion section. A good discussion section should answer 6 questions. 1. What is different in your findings compared to previous research? 2. What is similar in your findings compared to previous research? 3. How different…


so... free lunch is real? This paper shows that mathematically, euler discretization is removed (aka forgetting emerges naturally now), so this should remove any long context instability of linear attn? can anyone pls enlighten me if this is the case



With the recent hybrid attention releases from MiniMax, Qwen, Kimi, and NVIDIA, this paper introduces Error-Free Linear Attention that could top them all This new technique has a stable linear-time attention that's better than any linear attention variants and also DeltaNet!


This guy literally shows how to master Claude Code from scratch (in 15 mins)

Más del 90 % de los estudiantes ya usa IA de algún modo. Fingir que no existe no es una opción. El reto para escuelas y universidades es pasar del castigo al diseño: tareas auténticas, transparencia en el uso de IA y evaluación del razonamiento, no solo del producto final.…

This is the Outstanding Paper Award at ICLR 2025, and this is exactly the kind of research on LLMs we need, not those quasi-psychological studies of the form "we asked the same question to these 3 models and see which one is more racist!" As you might already know, when…


🚨BREAKING: You can now edit NotebookLM slides Codia just dropped NoteSlide, and it can convert NotebookLM slides to a fully editable PowerPoint deck in seconds. Free guide 👇


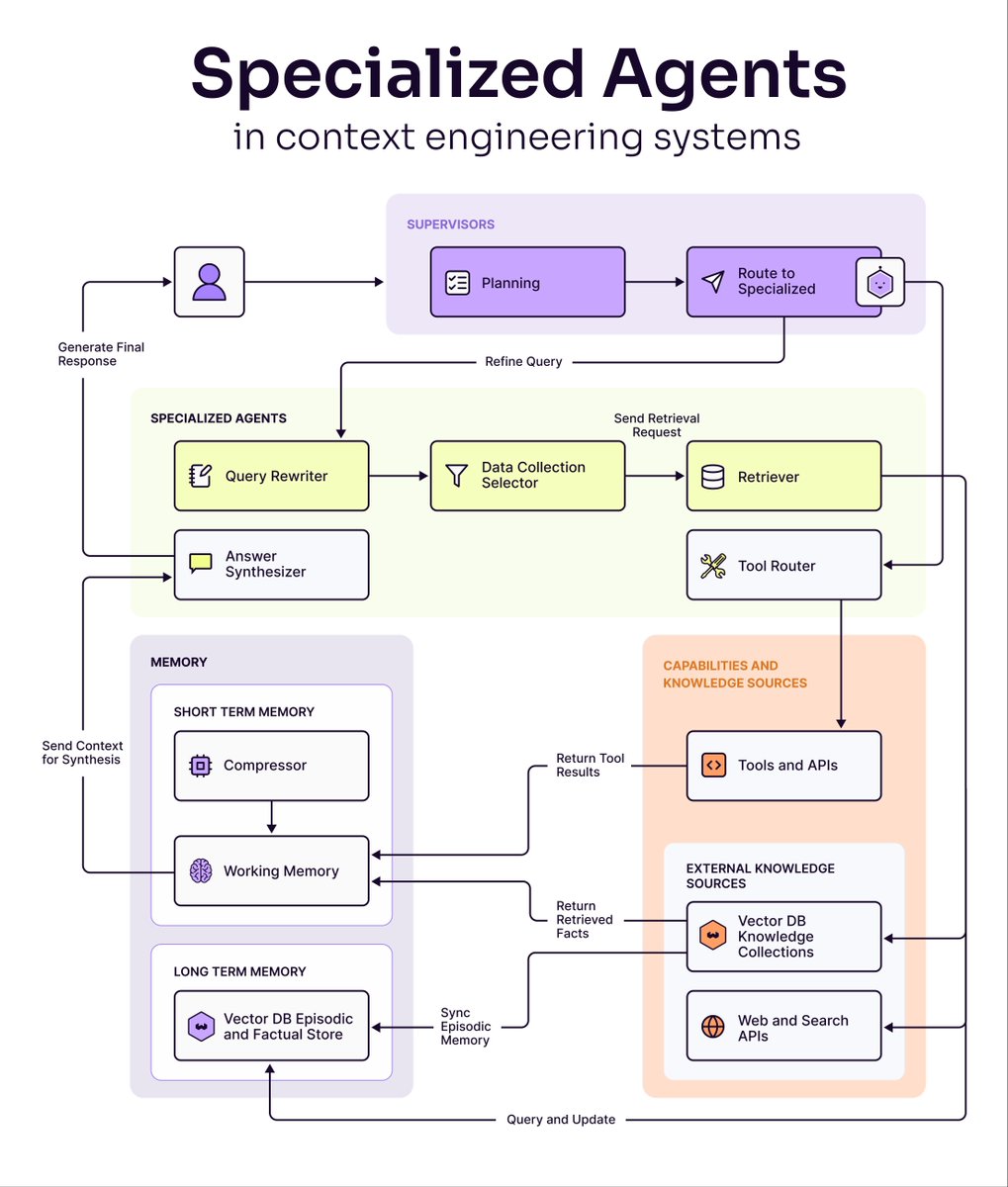
Multi-agent AI systems are eating single-agent architectures. But most teams have no idea how to build them. As agent systems get more complex, we're seeing a clear shift from single-agent architectures (one agent handles all tasks) to multi-agent architectures that distribute…

I just learned that Google solved HashMaps in C++ for everyone


This guy literally shows how to go from zero to AI engineer for free


This multi-agent system outperforms 9 of 10 human penetration testers. This work presents the first comprehensive evaluation of AI agents against human cybersecurity professionals on a real enterprise network: approximately 8,000 hosts across 12 subnets at a major research…


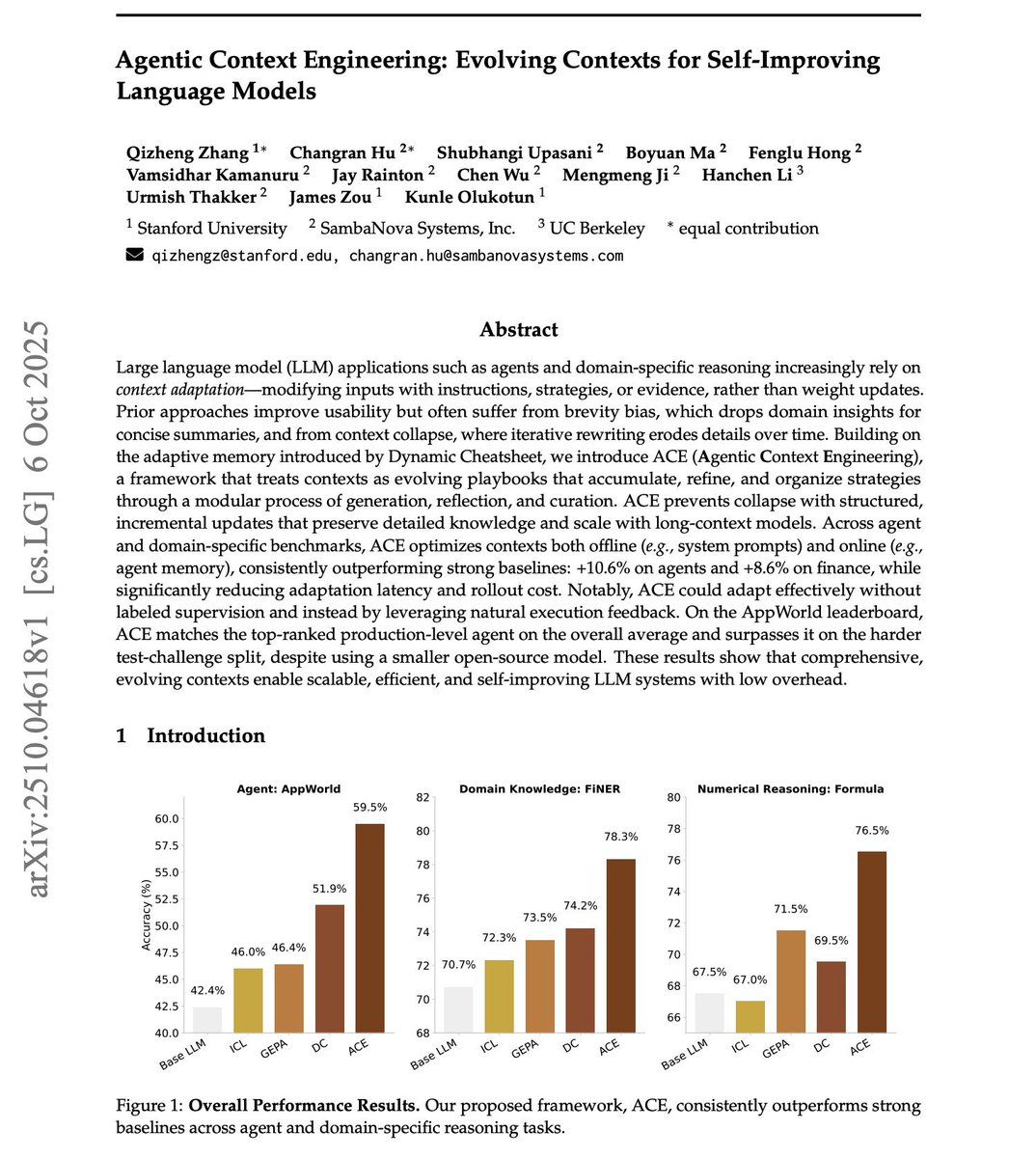
Stanford just made fine-tuning irrelevant with a single paper. It’s called Agentic Context Engineering (ACE) and it proves you can make models smarter without touching a single weight. Key takeaways (and get the 23 page PDF):

Builds AI agents locally without frameworks github.com/pguso/ai-agent…

A free MIT course breaking down mathematics for computer science & engineering: bit.ly/3XPi0Ao (v/@MITOCW) Here, MIT prof. Tom Leighton, who is also the CEO & co-founder of Akamai, discusses what a proof is (Lesson 1).

why does pre-norm work better than post-norm in transformers? i've been diving into transformer architecture (n'th time again) and noticed something interesting this time- almost all the implementations I have seen uses the "pre-norm" variant (normalizing before the sublayer…





























































































United States Tren
- 1. James Cook 2,873 posts
- 2. Mike Evans 1,986 posts
- 3. Yoro 18.8K posts
- 4. Ugarte 20K posts
- 5. Addison 3,928 posts
- 6. Morgan Rogers 11.8K posts
- 7. White Sox 17K posts
- 8. #AskFFT 1,172 posts
- 9. Tee Higgins 1,646 posts
- 10. Cunha 21.2K posts
- 11. #DawgPound 1,476 posts
- 12. Quentin Johnston N/A
- 13. #KeepPounding 1,380 posts
- 14. Happy Winter Solstice 13.3K posts
- 15. Murakami 19.7K posts
- 16. Geno Stone N/A
- 17. #AVLMUN 9,680 posts
- 18. Taysom Hill N/A
- 19. Joan Garcia 20.8K posts
- 20. Estime 7,192 posts










Something went wrong.
Something went wrong.