
Instruction Workshop, NeurIPS 2023
@itif_workshop
The official account of the 1st Workshop on Instruction Tuning and Instruction Following (ITIF), colocated with NeurIPS, in December 2023.

A new, tractable approach to study scaling laws for larger data mixtures compared to prior art. We achieve significantly better fit ($R^2=0.98$) on multilingual data mixtures with ~50 languages.


Have you ever wondered how to build target-language LMs most efficiently? 🤨 Will finetuning from other multilingual LMs help? No curse of multilinguality?? See the snapshot below for the answer. What about transferring data to help? What languages help? See our new paper! 👇


📢Thrilled to introduce ATLAS 🗺️: scaling laws beyond English, for pretraining, finetuning, and the curse of multilinguality. The largest public, multilingual scaling study to-date—we ran 774 exps (10M-8B params, 400+ languages) to answer: 🌍Are scaling laws different by…



What an insane banger and amazing work

Many gems in this paper for those who want to systematically scale multilingual learning with fewer arbitrary decisions. Great job Shayne et al.
📢Thrilled to introduce ATLAS 🗺️: scaling laws beyond English, for pretraining, finetuning, and the curse of multilinguality. The largest public, multilingual scaling study to-date—we ran 774 exps (10M-8B params, 400+ languages) to answer: 🌍Are scaling laws different by…

To scale data-constrained LLMs, repeating & denoising objectives can help. Another solution: Add multilingual data. But what languages help & how much? Below a snapshot for this at 2B scale, e.g., Chinese can hurt English while Indonesian may help.

📢Thrilled to introduce ATLAS 🗺️: scaling laws beyond English, for pretraining, finetuning, and the curse of multilinguality. The largest public, multilingual scaling study to-date—we ran 774 exps (10M-8B params, 400+ languages) to answer: 🌍Are scaling laws different by…

Exciting to see someone do a study so elaborately and at such scale. I really like this grid looking at transfer synergy. Also this result is cool. Intuitive that model capacity helps, but great to see an empirical result.

Q2: Which languages actually help each other during training? And how much? 🌟Answer: We measure this empirically. We built a 38×38 transfer matrix, or 1,444 language pairs—the largest such resource to date. We highlight the top 5 most beneficial source languages for each…

📢Thrilled to introduce ATLAS 🗺️: scaling laws beyond English, for pretraining, finetuning, and the curse of multilinguality. The largest public, multilingual scaling study to-date—we ran 774 exps (10M-8B params, 400+ languages) to answer: 🌍Are scaling laws different by…
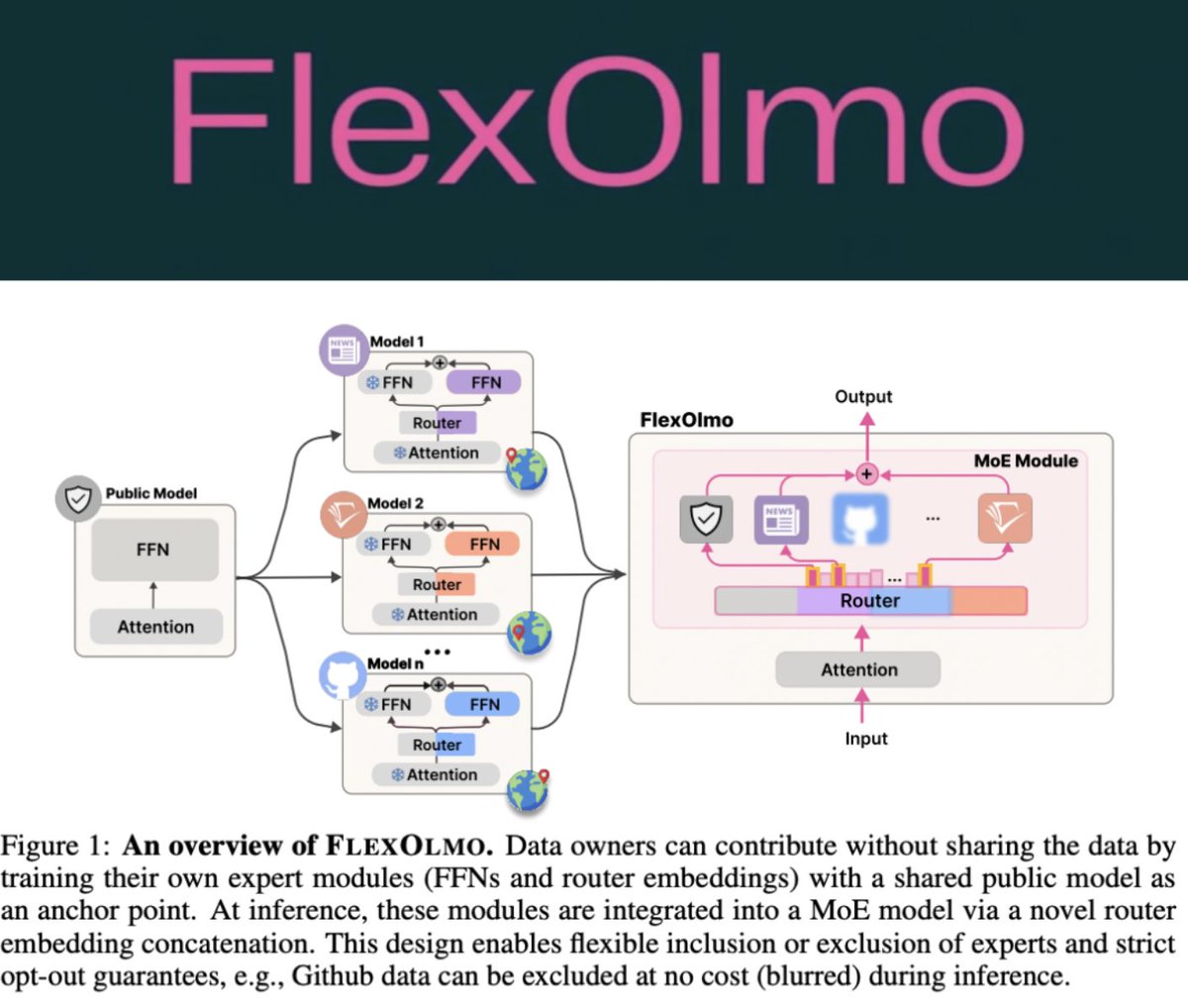
Copyrighted 🚧, private 🛑, and sensitive ☢️ data remain major challenges for AI. FlexOlmo introduces an architectural mechanism to flexibly opt-in/opt-out segments of data in the training weights, **at inference time**. (Prior common solutions were to filter your data once…
Thrilled to collaborate on the launch of 📚 CommonPile v0.1 📚 ! Introducing the largest openly-licensed LLM pretraining corpus (8 TB), led by @kandpal_nikhil @blester125 @colinraffel. 📜: arxiv.org/pdf/2506.05209 📚🤖 Data & models: huggingface.co/common-pile 1/

Come say hello at ICLR! 👋 Here's where you can find me: Friday: Data-centric AI Social! lu.ma/rmyoy2vw Saturday: Multimodal Data Provenance poster (3 pm, Hall 2B #494) Sunday: MLDPR Workshop (3 pm) [mldpr2025.com]—I'll talk about challenges to AI data…
![ShayneRedford's tweet image. Come say hello at ICLR! 👋 Here's where you can find me:
Friday: Data-centric AI Social! lu.ma/rmyoy2vw
Saturday: Multimodal Data Provenance poster (3 pm, Hall 2B #494)
Sunday: MLDPR Workshop (3 pm) [mldpr2025.com]—I'll talk about challenges to AI data…](https://pbs.twimg.com/media/GpXedZJacAAUlBy.jpg)
Thrilled our global data ecosystem audit was accepted to #ICLR2025! Empirically, we find: 1⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024). 2⃣ YouTube is now 70%+ of speech/video data but could block third-party collection. 3⃣ <0.2% of data from…

What are 3 concrete steps that can improve AI safety in 2025? 🤖⚠️ Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-action to empower independent evaluators: 1️⃣ Standardized AI flaw reports 2️⃣ AI flaw disclosure programs + safe harbors. 3️⃣ A coordination…

I compiled a list of resources for understanding AI copyright challenges (US-centric). 📚 ➡️ why is copyright an issue? ➡️ what is fair use? ➡️ why are memorization and generation important? ➡️ how does it impact the AI data supply / web crawling? 🧵

I wrote a spicy piece on "AI crawler wars"🐞 in @MIT @techreview (my first op-ed)! While we’re busy watching copyright lawsuits & the EU AI Act, there’s a quieter battle over data access that affects websites, everyday users, and the open web. 🔗 technologyreview.com/2025/02/11/111… 1/

1/ Last week, we published the International AI Safety Report—supported by 30 nations plus the OECD, UN, and EU. Over 100 independent experts contributed. I’m thankful to play a small writing role, focusing on “Risks of Copyright.” 🔗 bit.ly/40Vm7Mu
Our updated Responsible Foundation Model Development Cheatsheet (250+ tools & resources) is now officially accepted to @TmlrOrg 2025! It covers: - data sourcing, - documentation, - environmental impact, - risk eval - model release & licensing

🪶 Some thoughts on DeepSeek, OpenAI, and the copyright battles: This isn’t the first time OpenAI has accused a Chinese company of breaking its Terms and training on ChatGPT outputs. Dec 2023: They suspended ByteDance’s accounts. 1/



Check out our recipe for adapting existing LMs for multimodal generation: it fully preserves language performances while enhancing models with visual understanding and generation🖼️

Introducing 𝐋𝐥𝐚𝐦𝐚𝐅𝐮𝐬𝐢𝐨𝐧: empowering Llama 🦙 with diffusion 🎨 to understand and generate text and images in arbitrary sequences. ✨ Building upon Transfusion, our recipe fully preserves Llama’s language performance while unlocking its multimodal understanding and…

New Report, to appear at @RealAAAI 2025: The @defcon 2024 @aivillage_dc Generative Red Team 2 (GRT2) Case Study, led by @seanmcgregor The event spanned: ⚔️495 hackers, against AI2’s Olmo + WildGuard 🐞200 model flaw reports 💰$7k+ paid bounties 🔗 arxiv.org/pdf/2410.12104








































































United States Trends
- 1. Northern Lights 44.5K posts
- 2. #Aurora 9,347 posts
- 3. #DWTS 52.8K posts
- 4. #RHOSLC 7,099 posts
- 5. AI-driven Web3 1,044 posts
- 6. Carmilla 1,874 posts
- 7. Sabonis 6,220 posts
- 8. H-1B 34.3K posts
- 9. Justin Edwards 2,444 posts
- 10. #GoAvsGo 1,563 posts
- 11. Gonzaga 2,987 posts
- 12. #MakeOffer 9,028 posts
- 13. Louisville 18.1K posts
- 14. Creighton 2,298 posts
- 15. Eubanks N/A
- 16. Jamal Murray N/A
- 17. Andy 61K posts
- 18. Cleto 2,508 posts
- 19. Oweh 2,120 posts
- 20. Zags N/A
Something went wrong.
Something went wrong.