
You might like
















Deepseek Sparse Attention from V3.2 is nice and "simple" (and compatible with MLA!), but at first it was surprising to me that it works well/better than other alternatives for both long context and short context. Some random thoughts I had: For short context both NSA and InfLLM…


first set of thoughts after quickly reading: DSA feels like a small step in between MLA -> and NSA's selection approach. While the DSA sparsity is interesting from a efficiency standpoint, i am more interested in its actual pure performance. Attention activation is something that…

I quite enjoyed this and it covers a bunch of topics without good introductory resources! 1. A bunch of GPU hardware details in one place (warp schedulers, shared memory, etc.) 2. A breakdown/walkthrough of reading PTX and SASS. 3. Some details/walkthroughs of a number of other…

New in-depth blog post time: "Inside NVIDIA GPUs: Anatomy of high performance matmul kernels". If you want to deeply understand how one writes state of the art matmul kernels in CUDA read along. (Remember matmul is the single most important operation that transformers execute…


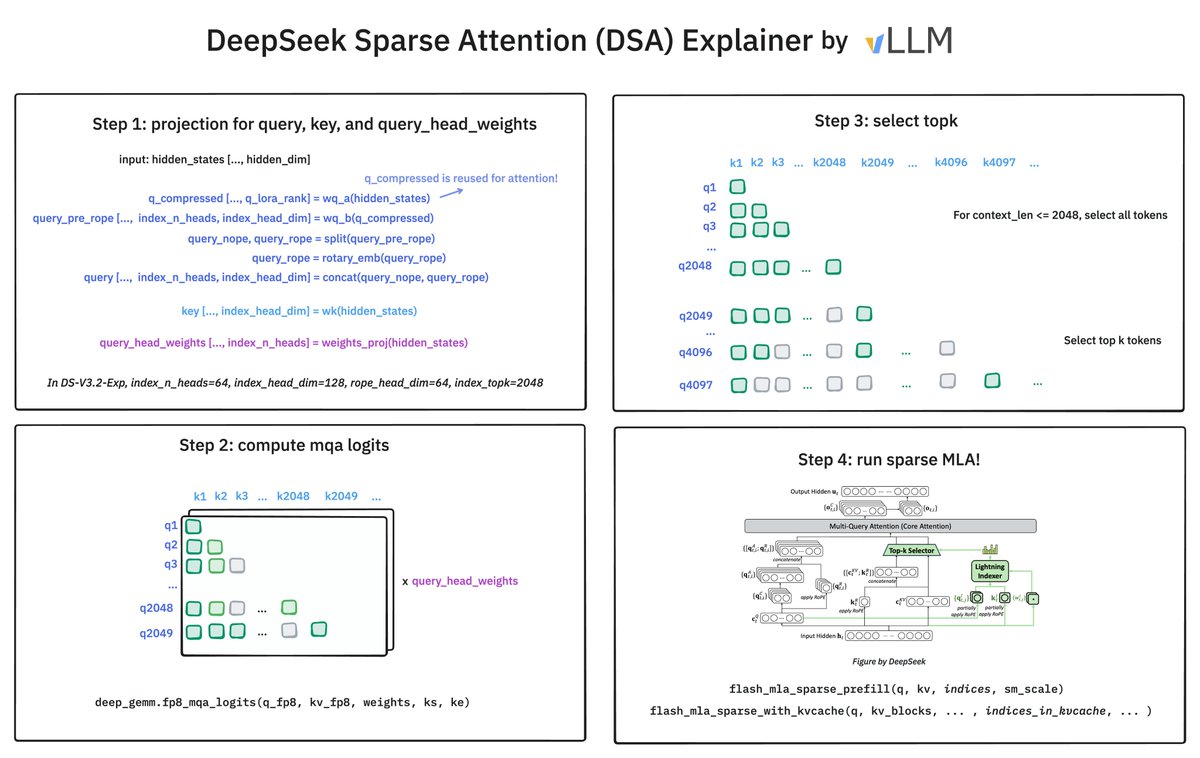
How does @deepseek_ai Sparse Attention (DSA) work? It has 2 components: the Lightning Indexer and Sparse Multi-Latent Attention (MLA). The indexer keeps a small key cache of 128 per token (vs. 512 for MLA). It scores incoming queries. The top-2048 tokens to pass to Sparse MLA.

🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model! ✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context. 👉 Now live on App, Web, and API. 💰 API prices cut by 50%+! 1/n
New in-depth blog post time: "Inside NVIDIA GPUs: Anatomy of high performance matmul kernels". If you want to deeply understand how one writes state of the art matmul kernels in CUDA read along. (Remember matmul is the single most important operation that transformers execute…

BTW, They released a deep dive on FP8 KVCache of main MLA. github.com/deepseek-ai/Fl… so, actually ≈1/5 compared to FP8 dense MLA.

As expected, NSA is not compatible with MLA, so DeepSeek chose another method: use a smaller (d=128) attention (w/o value) as the indexer. Asymptotic cost ratio = 128/576. In addition, indexer uses FP8 while main MLA uses 16-bit, so = 64/576 = 1/9.

Apologies that I haven't written anything since joining Thinking Machines but I hope this blog post on a topic very near and dear to my heart (reproducible floating point numerics in LLM inference) will make up for it!

Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference” We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to…


building pretraining infrastructure is an exercise in complexity management, abstraction design, operability/observability, and deep systems and ML understanding. reflects some of the trickiest and most rewarding problems in software engineering. which makes it really fun!
New in-depth blog post - "Inside vLLM: Anatomy of a High-Throughput LLM Inference System". Probably the most in depth explanation of how LLM inference engines and vLLM in particular work! Took me a while to get this level of understanding of the codebase and then to write up…


This is the best public resource on scaling hardware for AI, and its free. "How to Scale Your Model" is the bible from Google DeepMind that covers the math, systems and scaling laws for LLM training and inference workloads. Approachable yet thorough. Absolute Must-read.

节选: 1. 开源了就意味着第一方再也不能用各种 hack 的方式粉饰效果,必须拿出足够通用、任何第三方拿到同样的 weights 都要能很简单地复现出你的效果才行。 2. 绝大多数 Agent 产品,离了 Claude 以后,什么都不是。


Getting mem-bound kernels to speed-of-light isn't a dark art, it's just about getting the a couple of details right. We wrote a tutorial on how to do this, with code you can directly use. Thanks to the new CuTe-DSL, we can hit speed-of-light without a single line of CUDA C++.

🦆🚀QuACK🦆🚀: new SOL mem-bound kernel library without a single line of CUDA C++ all straight in Python thanks to CuTe-DSL. On H100 with 3TB/s, it performs 33%-50% faster than highly optimized libraries like PyTorch's torch.compile and Liger. 🤯 With @tedzadouri and @tri_dao


Very cool thread about the CS336 Language Models from Scratch course at Stanford taught by @percyliang et al. Makes me wish I was a student again!

Wrapped up Stanford CS336 (Language Models from Scratch), taught with an amazing team @tatsu_hashimoto @marcelroed @neilbband @rckpudi. Researchers are becoming detached from the technical details of how LMs work. In CS336, we try to fix that by having students build everything:

Ilya Sutskever, U of T honorary degree recipient, June 6, 2025 youtu.be/zuZ2zaotrJs?si… via @YouTube This is a must watch speech, the wisest words you could hear. Congratulations 🙌 @ilyasut @UofT was very fortunate to have you and so many other amazing students and…

youtube.com
YouTube
Ilya Sutskever, U of T honorary degree recipient, June 6, 2025

Dear PhD students now regretting taking offers at US schools: If you turned down PhD offers in Canada, but want to rethink that, email the professors who were trying to recruit you. They might be able to pull some strings. Your sane neighbor to the north, Canada

Strong recommend for this book and the JAX/TPU docs, even if you are using Torch / GPUs. Clean notation and mental model for some challenging ideas. github.com/jax-ml/scaling… github.com/jax-ml/scaling… docs.jax.dev/en/latest/note…


🚀 Breaking: SGLang provides the first open-source implementation to serve @deepseek_ai V3/R1 models with large-scale expert parallelism and prefill-decode disaggregation on 96 GPUs. It nearly matches the throughput reported by the official DeepSeek blog, achieving 52.3K input…


The SGLang guys @lmsysorg are always doing such incredible work. This is also what the open-source community has made possible! 🚀




4/ Our AI leadership was on display at @GoogleCloud Next, where we launched Ironwood, our most powerful TPU yet — 10X compute boost, optimized for inference at scale. And we’re first to bring NVIDIA’s next-gen Blackwell GPUs to customers. Now with tools for building multi-agent…

Full talk of Ilya here 👇

.@ilyasut full talk at neurips 2024 "pre-training as we know it will end" and what comes next is superintelligence: agentic, reasons, understands and is self aware




































































































United States Trends
- 1. #DWTS 46.5K posts
- 2. Northern Lights 25.7K posts
- 3. #Aurora 5,231 posts
- 4. Justin Edwards 1,722 posts
- 5. Louisville 15.2K posts
- 6. Andy 59.4K posts
- 7. Lowe 12.1K posts
- 8. #RHOSLC 5,515 posts
- 9. Elaine 42.1K posts
- 10. #OlandriaxHarpersBazaar 2,861 posts
- 11. Kentucky 24K posts
- 12. Oweh 1,766 posts
- 13. Celtics 11.5K posts
- 14. JT Toppin N/A
- 15. Robert 98.2K posts
- 16. #WWENXT 15.3K posts
- 17. Dylan 30.4K posts
- 18. Jordan Walsh N/A
- 19. Whitney 8,608 posts
- 20. Kam Williams N/A
You might like
-
 Yushi Hu
Yushi Hu
@huyushi98 -
 Fei Wang
Fei Wang
@fwang_nlp -
 Minqian Liu
Minqian Liu
@minqian_liu -
 Mohit Bansal
Mohit Bansal
@mohitban47 -
 Denghui Zhang
Denghui Zhang
@denghui_zhang -
 Chris Samarinas
Chris Samarinas
@CSamarinas -
 Gordon Lee🍀
Gordon Lee🍀
@redoragd -
 James Bradbury
James Bradbury
@jekbradbury -
 Yumo Xu
Yumo Xu
@yumo_xu -
 Abhinav
Abhinav
@abkashyap92 -
 Bingbing Wen
Bingbing Wen
@bingbingwen1 -
 Tenghao Huang
Tenghao Huang
@TenghaoHuang45 -
 J Ashok Kumar
J Ashok Kumar
@jashokkumar83 -
 Prateek Agarwal ⛄️
Prateek Agarwal ⛄️
@Prateek_AL -
 Negar Rostamzadeh
Negar Rostamzadeh
@negar_rz
Something went wrong.
Something went wrong.