
Joykirat
@joykiratsingh
CS PhD Student @unc_ai_group @UNC, advised by. @mohitban47 | ex RF @MSFTResearch
Tal vez te guste














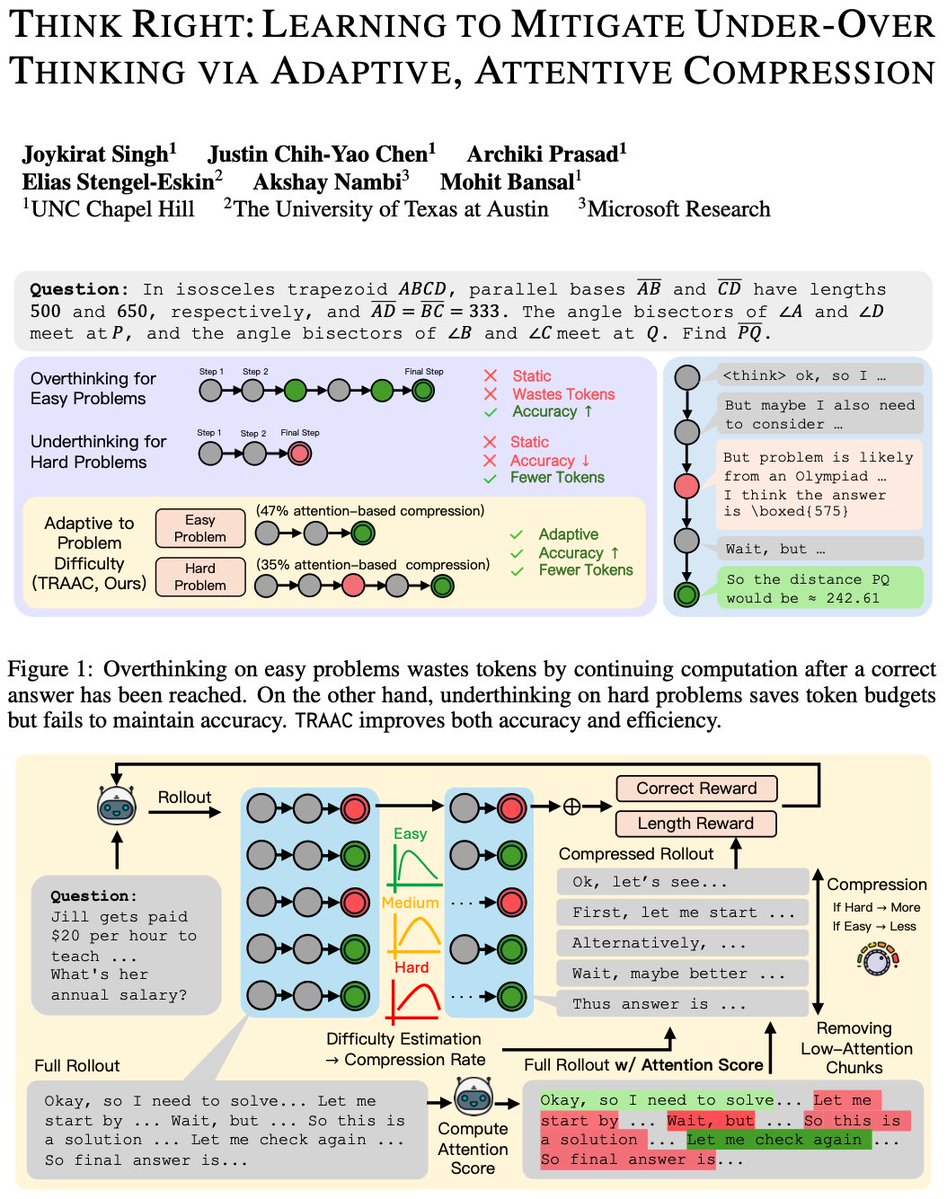
🚨 Excited to announce TRAAC, an online difficulty-adaptive, attention-based method that handles the tradeoff of under & overthinking in reasoning models to improve both accuracy and efficiency. Underthinking ❌: Models terminate reasoning too early on harder problems, leading…

🚨 Excited to share Gistify! Often the easiest way to understand large/complicated repos is by playing around with test cases and tracing back through the code that is executed. Gistify tasks models with turning a codebase and an entry-point (e.g. command, unit test) into a…

🚨 Excited to announce Gistify!, where a coding agent must extract the gist of a repository: generate a single, executable, and self-contained file that faithfully reproduces the behavior of a given command (e.g., a test or entrypoint). ✅ It is a lightweight, broadly applicable…


I'll be presenting ✨MAgICoRe✨ virtually tonight at 7 PM ET / 8 AM CST (Gather Session 3)! I'll discuss 3 key challenges in LLM refinement for reasoning, and how MAgICoRe tackles them jointly: 1⃣ Over-correction on easy problems 2⃣ Failure to localize & fix its own errors 3⃣…

🚨 Check out our awesome students/postdocs' papers at #EMNLP2025 and say hi to them 👋! Also, I will give a keynote (virtually) on "Attributable, Conflict-Robust, and Multimodal Summarization with Multi-Source Retrieval" at the NewSumm workshop. -- Jaehong (in-person) finished…

🚨 Check out our awesome students/postdocs' papers at #EMNLP2025 and say hi to them 👋! Also, I will give a keynote (virtually) on "Attributable, Conflict-Robust, and Multimodal Summarization with Multi-Source Retrieval" at the NewSumm workshop. -- Jaehong (in-person) finished…
🚨 Excited to announce Gistify!, where a coding agent must extract the gist of a repository: generate a single, executable, and self-contained file that faithfully reproduces the behavior of a given command (e.g., a test or entrypoint). ✅ It is a lightweight, broadly applicable…
Thrilled to have our paper “Data-scarce Behavior Editing of Language Models” accepted at #EMNLPFindings2025! 🎉 We propose TaRot, a gradient-free method to edit LLM behavior efficiently — no retraining or large datasets needed. Super fun collab with Subhabrata Dutta &…

🚀 LCS2 Sneak Peek Series for #EMNLPFindings2025 🚀 📝 Data-scarce Behavior Editing of Language Models 👥 @joykiratsingh, Subhabrata Dutta, @Tanmoy_Chak 📌 Paper: aclanthology.org/2025.findings-… 🎥 Video: youtube.com/watch?v=Uy7GYA…

🚀 LCS2 Sneak Peek Series for #EMNLPFindings2025 🚀 📝 Data-scarce Behavior Editing of Language Models 👥 @joykiratsingh, Subhabrata Dutta, @Tanmoy_Chak 📌 Paper: aclanthology.org/2025.findings-… 🎥 Video: youtube.com/watch?v=Uy7GYA…
It was an honor and pleasure to give a keynote at the 28th European Conference on Artificial Intelligence (#ECAI2025) in beautiful Bologna, and engage in enthusiastic discussions about trustworthy + calibrated agents, collaborative reasoning + privacy, and controllable multimodal…




🚨 Excited to share new work on inferring symbolic world models from observations! OneLife can infer world models in stochastic, complex environments by proposing rules via LLM and reweighting code-based environment laws from observations collected in a single interaction…

How can an agent reverse engineer the underlying laws of an unknown, hostile & stochastic environment in “one life”, without millions of steps + human-provided goals / rewards? In our work, we: 1️⃣ infer an executable symbolic world model (a probabilistic program capturing…

🚨 Excited to share our new work ✨ OneLife ✨, which investigates how an agent can infer executable symbolic world models 🌐 from a single unguided trajectory in a stochastic environment. I’m especially excited about our planning + evaluation contributions: 1️⃣ We support…
How can an agent reverse engineer the underlying laws of an unknown, hostile & stochastic environment in “one life”, without millions of steps + human-provided goals / rewards? In our work, we: 1️⃣ infer an executable symbolic world model (a probabilistic program capturing…
How can an agent reverse engineer the underlying laws of an unknown, hostile & stochastic environment in “one life”, without millions of steps + human-provided goals / rewards? In our work, we: 1️⃣ infer an executable symbolic world model (a probabilistic program capturing…

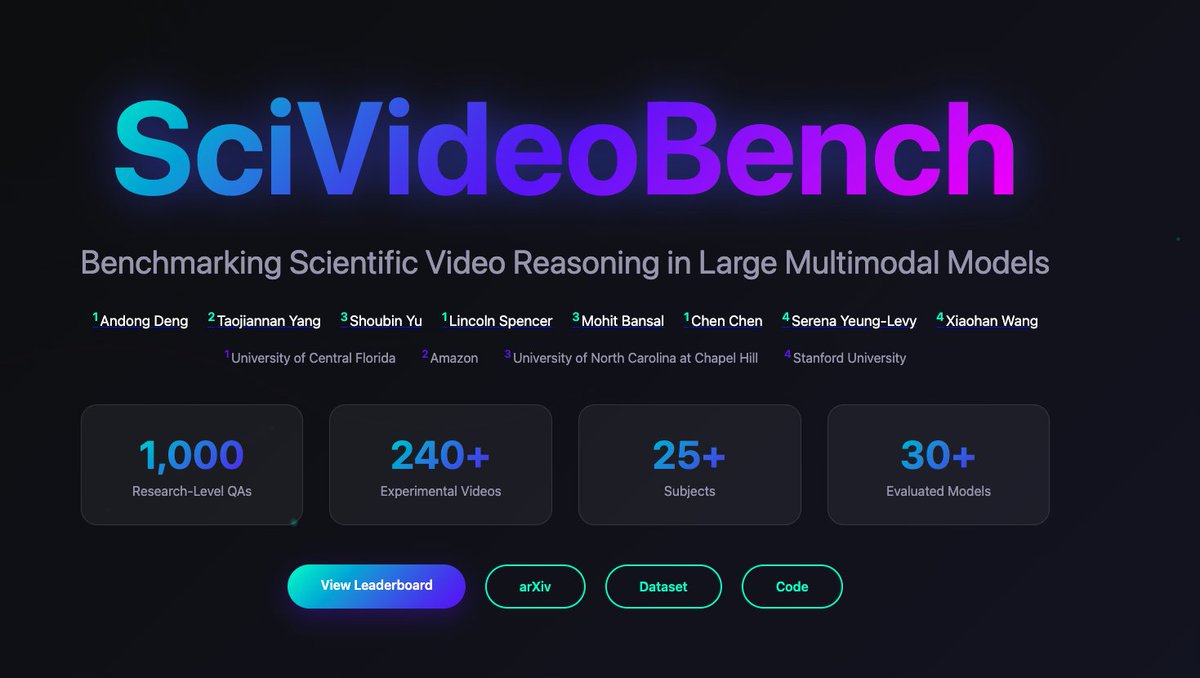
🚨 New Paper Alert! Introducing SciVideoBench — a comprehensive benchmark for scientific video reasoning! 🔬SciVideoBench: 1. Spans Physics, Chemistry, Biology & Medicine with authentic experimental videos. 2. Features 1,000 challenging MCQs across three reasoning types:…

🚨 Thrilled to introduce Self-Improving Demonstrations (SID) for Goal-Oriented Vision-and-Language Navigation — a scalable paradigm where navigation agents learn to explore by teaching themselves. ➡️ Agents iteratively generate and learn from their own successful trajectories ➡️…


Landed in Montreal 🇨🇦 for #COLM2025 to present my first-author work on task-conditioned mixed-precision quantization: “Task-Circuit Quantization” (Thursday 11am, Poster Session 5). I'm applying to PhD programs this cycle and am excited to chat about this or other interests (LLM…
🚨 Check out our awesome students/postdocs' papers at #COLM2025 and say hi to them (several are on the job market or hiring) --> -- Archiki, David are on the post-PhD job market! -- Elias finished his postdoc & is now faculty at UT-Austin CS and looking to admit PhD students!…

I am attending #COLM2025 🇨🇦 this week to present our work on: Unit Test Generation: 📅 Oct 8th (Wed), 4:30 PM, #79 RAG with conflicting evidence: 📅 Oct 9th (Thu), 11 AM, #71 PS: I'm on the industry job market for RS roles, so you can reach me via DM or in-person to chat! 😄
🚨 Check out our awesome students/postdocs' papers at #COLM2025 and say hi to them (several are on the job market or hiring) --> -- Archiki, David are on the post-PhD job market! -- Elias finished his postdoc & is now faculty at UT-Austin CS and looking to admit PhD students!…
✈️ Arrived at #COLM2025 where I'll be helping to present the following 4 papers. I'm also recruiting multiple PhD students for my new lab at UT Austin -- happy to chat about research, PhD applications, or postdoc openings in my former postdoc lab at UNC! -- Learning to Generate…
🚨 Check out our awesome students/postdocs' papers at #COLM2025 and say hi to them (several are on the job market or hiring) --> -- Archiki, David are on the post-PhD job market! -- Elias finished his postdoc & is now faculty at UT-Austin CS and looking to admit PhD students!…
🚨 Check out our awesome students/postdocs' papers at #COLM2025 and say hi to them (several are on the job market or hiring) --> -- Archiki, David are on the post-PhD job market! -- Elias finished his postdoc & is now faculty at UT-Austin CS and looking to admit PhD students!…
🚨 "Think the right amount" for improving both reasoning accuracy and efficiency! --> Large reasoning models under-adapt = underthink on hard problems and overthink on easy ones --> ✨TRAAC✨ is an online RL, difficulty-adaptive, attention-based compression method that prunes…
🚨 Excited to announce TRAAC, an online difficulty-adaptive, attention-based method that handles the tradeoff of under & overthinking in reasoning models to improve both accuracy and efficiency. Underthinking ❌: Models terminate reasoning too early on harder problems, leading…
🚨 TRAAC uses an online difficulty-adaptive, attention-based compression method to address a core problem in long thinking: an inability to adapt to problem difficulty! Leads to underthinking on hard problems, overthinking on easy ones, reducing accuracy and efficiency. TRAAC…
🚨 Excited to announce TRAAC, an online difficulty-adaptive, attention-based method that handles the tradeoff of under & overthinking in reasoning models to improve both accuracy and efficiency. Underthinking ❌: Models terminate reasoning too early on harder problems, leading…
Models often think too much on easy problems and not enough on harder reasoning problems. Our new method ✨TRAAC✨ fixes this by teaching models to adaptively compress their "thinking budget" to the difficulty of the task during GRPO rollouts. Result? The model uses…
🚨 Excited to announce TRAAC, an online difficulty-adaptive, attention-based method that handles the tradeoff of under & overthinking in reasoning models to improve both accuracy and efficiency. Underthinking ❌: Models terminate reasoning too early on harder problems, leading…































































































United States Tendencias
- 1. Epstein 713K posts
- 2. Epstein 713K posts
- 3. Steam Machine 35.4K posts
- 4. Bradley Beal 3,303 posts
- 5. Boebert 25.1K posts
- 6. Valve 25K posts
- 7. Virginia Giuffre 40.8K posts
- 8. Jake Paul 2,705 posts
- 9. Xbox 60.9K posts
- 10. Anthony Joshua 1,997 posts
- 11. Scott Boras N/A
- 12. GabeCube 2,333 posts
- 13. Clinton 101K posts
- 14. Rosalina 65.9K posts
- 15. Mel Tucker N/A
- 16. H-1B 95.9K posts
- 17. Zverev 3,419 posts
- 18. Jameis 9,172 posts
- 19. #BLACKROCK_NXXT N/A
- 20. Jordan Humphrey N/A
Tal vez te guste
-
 met
met
@metsetwhoo -
 Avishi
Avishi
@avgupt -
 Aryan Taneja
Aryan Taneja
@TanejaAryan -
 Rishit Gupta
Rishit Gupta
@RishitG57144297 -
 Prakhar
Prakhar
@pr3khar -
 Ananya Lohani
Ananya Lohani
@ananyalohani_ -
 Ritwik Kar
Ritwik Kar
@KuchAlagKar -
 Abhishek Goyal
Abhishek Goyal
@d_silent_quill -
 Nandika Jain
Nandika Jain
@jainnandika -
 Samyak 🪔
Samyak 🪔
@SamyakGupta3 -
 dhattarwalmohit
dhattarwalmohit
@dhattarwalm0hit -
 Sushmita
Sushmita
@vsushmita_ -
 Bhaskar Gupta
Bhaskar Gupta
@not_bhaskar -
 Karanjot Singh
Karanjot Singh
@_karanjot
Something went wrong.
Something went wrong.