
maybe: shivam
@kaffeinated
ai researcher @spotify, former matrix multiplier @twitter @x cortex, nyu. techno-optimist. probably on a bike 🚲☕.
You might like












Announcing Olmo 3, a leading fully open LM suite built for reasoning, chat, & tool use, and an open model flow—not just the final weights, but the entire training journey. Best fully open 32B reasoning model & best 32B base model. 🧵


I need to take more 14 hour flights without internet. Carefully read three new (amazing!) papers, wrote two letters, and watched two movies. Need a faraday cage at home.

The UK is a great country with an extraordinary history. Our stagnation is real, but it's fixable and worth fixing. Enjoyed giving this talk at @lfg_uk last week and so encouraged by the optimistic responses I've had from people who are building a brilliant future for Britain 🚀

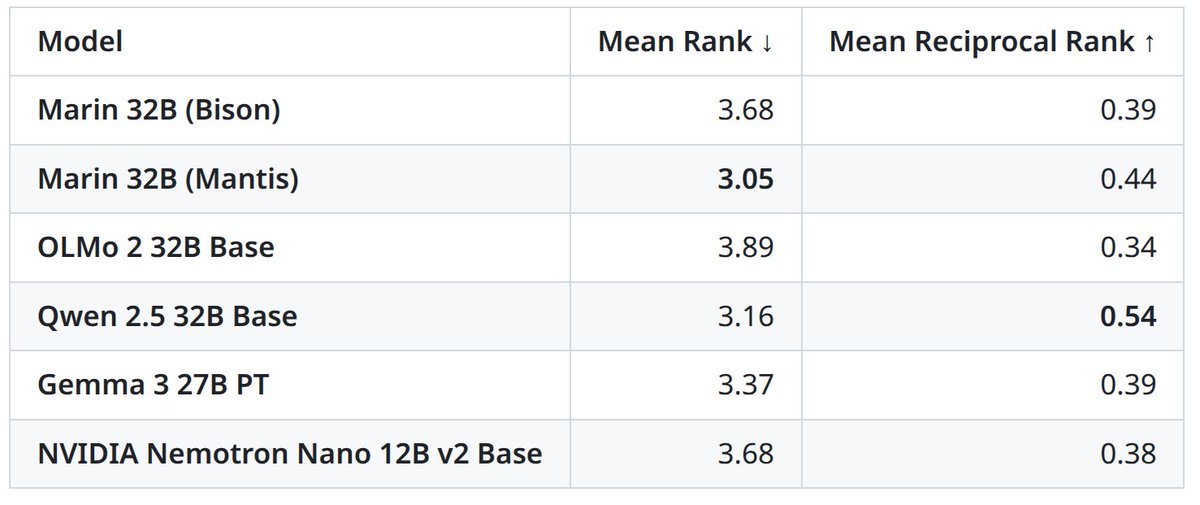
⛵Marin 32B Base (mantis) is done training! It is the best open-source base model (beating OLMo 2 32B Base) and it’s even close to the best comparably-sized open-weight base models, Gemma 3 27B PT and Qwen 2.5 32B Base. Ranking across 19 benchmarks:

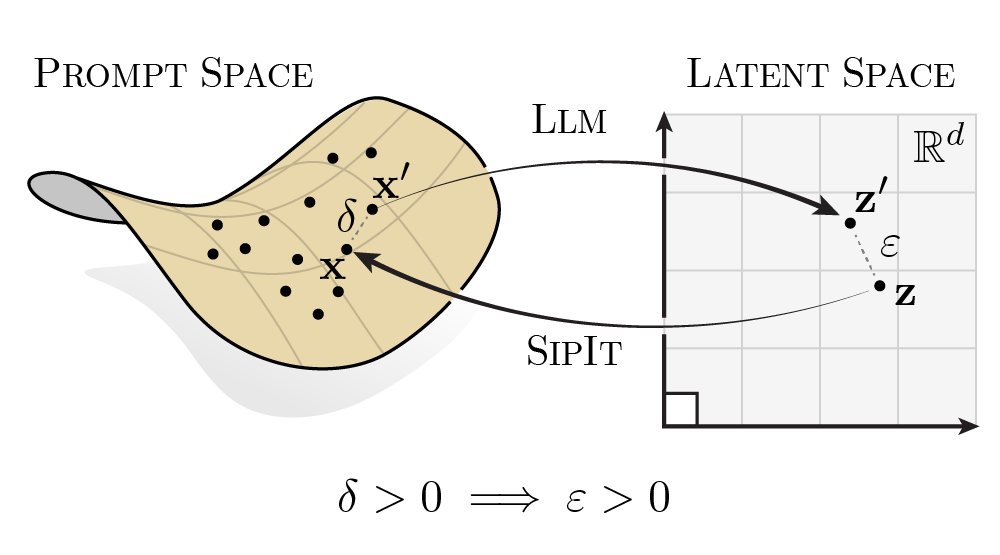
LLMs are injective and invertible. In our new paper, we show that different prompts always map to different embeddings, and this property can be used to recover input tokens from individual embeddings in latent space. (1/6)
You spend $1B training a model A. Someone on your team leaves and launches their own model API B. You're suspicious. Was B was derived (e.g., fine-tuned) from A? But you only have blackbox access to B... With our paper, you can still tell with strong statistical guarantees…

🔎Did someone steal your language model? We can tell you, as long as you shuffled your training data🔀. All we need is some text from their model! Concretely, suppose Alice trains an open-weight model and Bob uses it to produce text. Can Alice prove Bob used her model?🚨

Excited to release new repo: nanochat! (it's among the most unhinged I've written). Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single,…


We wrote a book about representation learning! It’s fully open source, available and readable online, and covers everything from theoretical foundations to practical algorithms. 👷♂️ We’re hard at work updating the content for v2.0, and would love your feedback and contributions


A lot of younger people who’re new to the industry ask me how to do “networking”. How do you go from knowing no one in San Francisco to having a network of people that you can do business with, learn from, hire, etc. The trick is I never set out to “network”. Maybe due to…



I have never even slightly wavered in my position that Trump is bad and stupid

this image has singlehandedly saved me from so much overthinking


companies like Facebook record every imaginable interaction their users have with the platform. they log each of your clicks and taps. they keep track of how long your gaze lingered on a post, whether you were on the same WiFi as that woman who might be your friend, which…

Sure, you could use AI to summarize papers and explain them at a level anyone could understand... or you can turn the abstracts into music videos for no reason. The tools are not perfect yet, but the disparate elements (consistent characters, lip syncing, etc.) are evolving fast

There's only so much attention available in a day. Invest it in enthusiasm, wonder, and progress.

It's kind of predictable that it would get defined down, but it's still wild that "AI Agent" went from meaning "AI that can act autonomously to achieve a goal by planning, executing and self-correcting when it makes mistakes" to "a wrapper that calls an LLM a bunch of times"



Our latest CS336 Language Modeling from Scratch lectures are now available! View the entire playlist here: youtube.com/playlist?list=…

This is actually how it feels. Remember feature engineering?



Seeing text-to-text regression work for Google’s massive compute cluster (billion $$ problem!) was the final result to convince us we can reward model literally any world feedback. Paper: arxiv.org/abs/2506.21718 Code: github.com/google-deepmin… Just train a simple encoder-decoder…




















































































































United States Trends
- 1. GeForce Season 4,248 posts
- 2. Comey 194K posts
- 3. Everton 147K posts
- 4. Mark Kelly 129K posts
- 5. St. John 8,817 posts
- 6. Amorim 63.1K posts
- 7. 49ers 20.6K posts
- 8. Seton Hall 2,474 posts
- 9. #sjubb N/A
- 10. UCMJ 19.2K posts
- 11. Iowa State 3,708 posts
- 12. Opus 4.5 9,700 posts
- 13. Genesis Mission 2,872 posts
- 14. Manchester United 85.1K posts
- 15. Dealing 31.3K posts
- 16. Hegseth 52.1K posts
- 17. #LightningStrikes N/A
- 18. Benedict Arnold 4,331 posts
- 19. Pickford 11.5K posts
- 20. Galarza 24K posts











Something went wrong.
Something went wrong.