
You might like





Sonnet 4.5 + MCP + n8n = AI Content Infrastructure that replaces $12K+/month ghostwriters... The 3-layer system that cloned my writing voice and generated 25M organic views → No more 2-3 week turnarounds for 5 basic posts → No more robotic AI that screams "ChatGPT wrote this"…

WE'RE HIRING FOUNDING ENGINEERS AT WTF. We’re building one of the most exciting projects yet at WTF, something that will shape us as a brand, as a platform, and (hopefully) create a far wider impact with and for the youth of India. The core team will work directly with me and a…

New post re: Devin (the AI SWE). We couldn't find many reviews of people using it for real tasks, so we went MKBHD mode and put Devin through its paces. We documented our findings here. Would love to know if others have had a different experience. answer.ai/posts/2025-01-…


I will teach Large Language Model Systems again in Spring 2025. (11868 for CMU folks) The course syllabus (tentative) is online at llmsystem.github.io/llmsystem2025s… CMU ppl are welcome to enroll. For others, I will release the materials online. Or apply to CMU LLM/GenAI certificate program
llmsystem.github.io
LLM Systems | Large Language Model Systems
Description will go into a meta tag in

NVIDIA's $7B Mellanox acquisition was actually one of tech's most strategic deals ever. The untold story of the most important company in AI that most people haven't heard of 1/12


LoRA Learns Less and Forgets Less: When I saw a new, comprehensive empirical study of Low-Rank Adaptation for finetuning LLMs, I had to read it! Here are the main takeaways. This study aimed to compare LoRA to full finetuning on two different target domains: programming and…


RELEASE DAY After almost 10 years of hard work, tireless research, and a dive deep into the kernels of computer science, I finally realized a dream: running a high-level language on GPUs. And I'm giving it to the world! Bend compiles modern programming features, including: -…

ChatGPT can now remember information across chats:

Memory is now available to all ChatGPT Plus users. Using Memory is easy: just start a new chat and tell ChatGPT anything you’d like it to remember. Memory can be turned on or off in settings and is not currently available in Europe or Korea. Team, Enterprise, and GPTs to come.

Our computer vision textbook is released! Foundations of Computer Vision with Antonio Torralba and Bill Freeman mitpress.mit.edu/9780262048972/… It’s been in the works for >10 years. Covers everything from linear filters and camera optics to diffusion models and radiance fields. 1/4


Foundation models are well-established in vision and language, but time series forecasting has lagged behind - it still relies on dataset-specific models. Meet Lag-Llama: the first open-source foundation model for time series forecasting!


CUDA-MODE Lecture 3: Getting Started with CUDA Video: youtu.be/o3mWH7RqAos?si… Notebook: github.com/cuda-mode/lect… 🏎️Cuda intro for everyone with a Python background! @jeremyphoward builds the kernels 1:1 in python first (with blockIdx & threadIdx) ->then converts them to cuda C.
CUDA-MODE 3: Getting Started With CUDA How do you actually write a kernel and call it from Python? How do you test and debug your code? Speaker: @jeremyphoward Sat, Jan 27 12:00 PM PST (Bay Area) / 9:00 PM CET (Berlin) Live on discord: discord.gg/MF3xaGeKf6?eve…


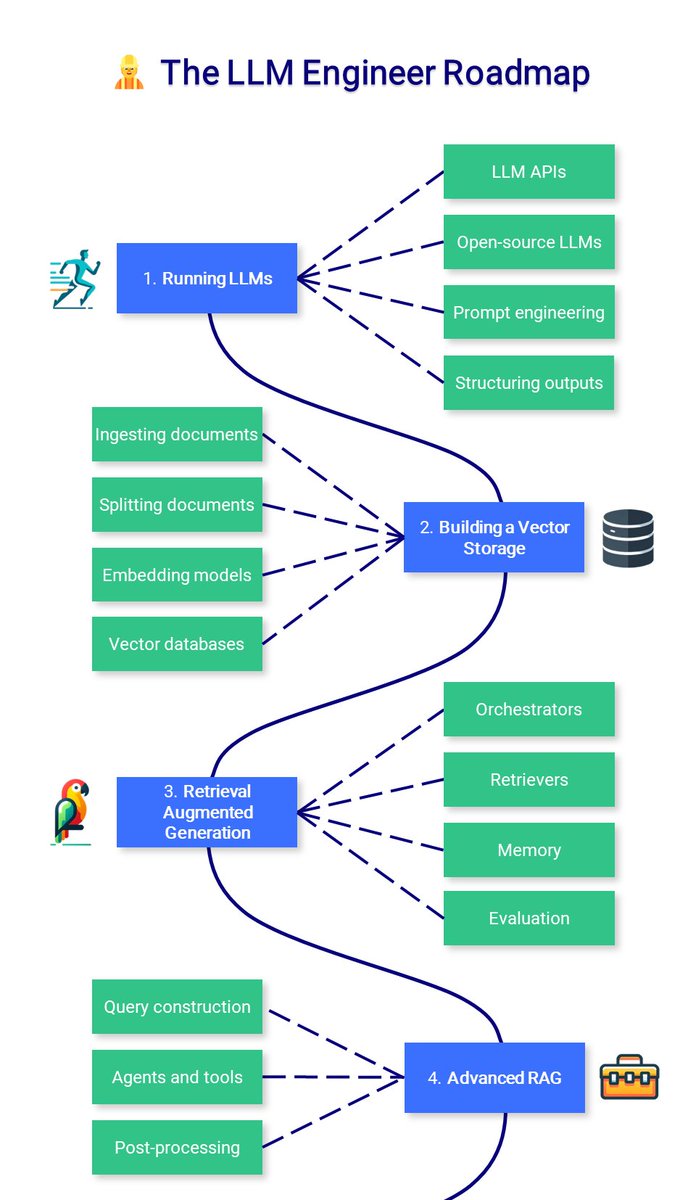
🧑🔬👷 The LLM Course is now complete! I added the LLM Engineer Roadmap, a list of high-quality resources to build LLM-powered applications and deploy them. 💻 LLM Course: github.com/mlabonne/llm-c…


TikTok presents Depth Anything Unleashing the Power of Large-Scale Unlabeled Data paper page: huggingface.co/papers/2401.10… demo: huggingface.co/spaces/LiheYou… Depth Anything is trained on 1.5M labeled images and 62M+ unlabeled images jointly, providing the most capable Monocular Depth…

We've just open-sourced two tools we use for large-scale data processing and large-scale model trainings: - datatrove – all things webscale data processing: deduplication, filtering, tokenization – github.com/huggingface/da… - nanotron – all things 3D parallelism: lightweight and…

This is a really neat website with useful information to compare vector databases. All the information is in one place, searchable, and you can add filters by the dimension you care about. Very comprehensive and super useful!

I've read a ton of research papers this year. And to conclude this eventful year in AI, I've compiled a selection of 10 noteworthy papers from 2023 that I am discussing in my new article: magazine.sebastianraschka.com/p/10-ai-resear… To get a sneak peak, I'm covering: - insights into LLM training…


Getting there slowly! Join us to build the best Hindi/Hinglish Open LLM collaboratively. If you want to collaborate, join hinglish-training channel on Hugging Face Discord 💥 This model was finetuned on hindi/hinglish data using mistral as base model using AutoTrain, without…

Alibaba releases DreaMoving demo on Hugging Face A Human Video Generation Framework based on Diffusion Models demo: huggingface.co/spaces/jiayong…
Exploiting Novel GPT-4 APIs paper page: huggingface.co/papers/2312.14… Language model attacks typically assume one of two extreme threat models: full white-box access to model weights, or black-box access limited to a text generation API. However, real-world APIs are often more…


































































































United States Trends
- 1. Wemby 36.4K posts
- 2. Steph 75.1K posts
- 3. Spurs 32.6K posts
- 4. Draymond 15.6K posts
- 5. Warriors 55K posts
- 6. Clemson 11.3K posts
- 7. Louisville 11K posts
- 8. Zack Ryder 16.4K posts
- 9. #SmackDown 52.8K posts
- 10. #DubNation 2,095 posts
- 11. Aaron Fox 2,386 posts
- 12. Massie 57.1K posts
- 13. Harden 15K posts
- 14. Marjorie Taylor Greene 48.3K posts
- 15. Brohm 1,696 posts
- 16. Bill Clinton 191K posts
- 17. Bubba 58.2K posts
- 18. Dabo 1,993 posts
- 19. PERTHSANTA JOY KAMUTEA 330K posts
- 20. Matt Cardona 2,972 posts




Something went wrong.
Something went wrong.