
Shashank Gupta
@shashank_bits
Researcher at Ai2 || Work on NLP, LLMs, Reasoning, Agents, AI4Code || Prev: Microsoft AI, Univ. of Illinois (UIUC), Max Planck, IIT-Bombay || @shashanknlp 🟦sky
คุณอาจชื่นชอบ
















🚨 DeepMind finally dropped the Veo3 paper which shows what we all realize from playing with video-gen models. Just like LLMs, visual reasoning on is an emergent property of training on tons of video. It can solve tasks not explicitly in training data. "Veo 3 is the GPT-3…


I spent the past month reimplementing DeepMind’s Genie 3 world model from scratch Ended up making TinyWorlds, a 3M parameter world model capable of generating playable game environments demo below + everything I learned in thread (full repo at the end)👇🏼

As part of Asta, our initiative to accelerate science with trustworthy AI agents, we built AstaBench—the first comprehensive benchmark to compare them. ⚖️

Introducing Asta—our bold initiative to accelerate science with trustworthy, capable agents, benchmarks, & developer resources that bring clarity to the landscape of scientific AI + agents. 🧵

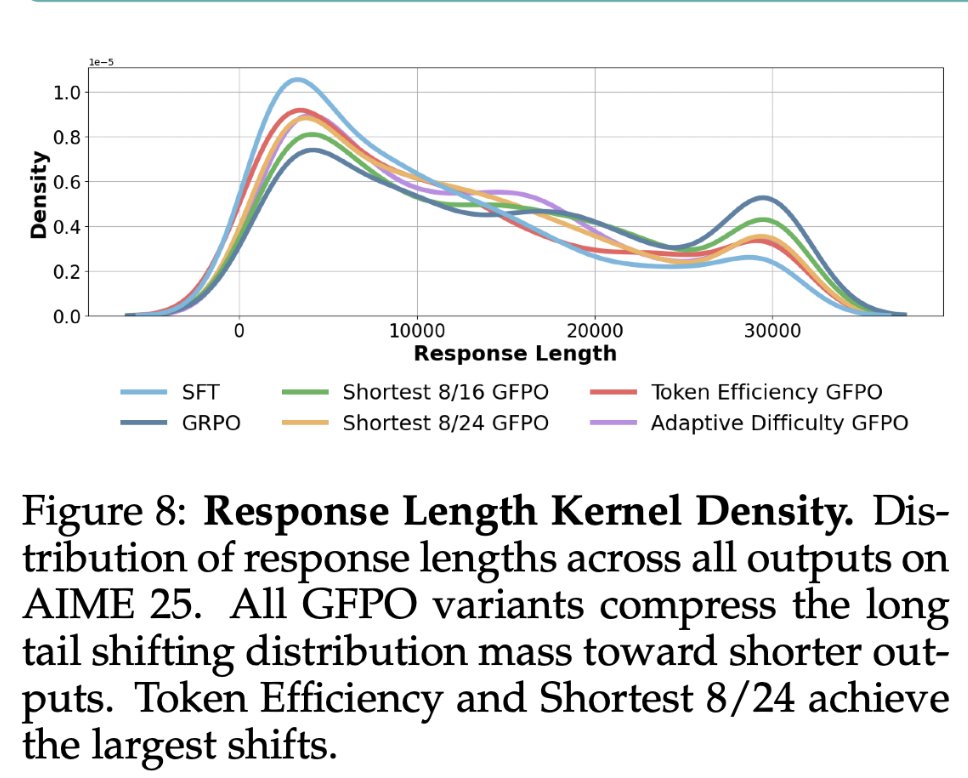
Test-time scaling w/ GRPO boosts accuracy, but also adds “filler tokens” increasing length w/o real progress. We present Group Filtered Policy Optimization (GFPO):🧵 1️⃣ Sample more per prompt 2️⃣ Rank by token efficiency (reward ÷ length) 3️⃣ Train on top-k 4️⃣ 🚀 Cut 80% of…

With fresh support of $75M from @NSF and $77M from @NVIDIA, we’re set to scale our open model ecosystem, bolster the infrastructure behind it, and fast‑track reproducible AI research to unlock the next wave of scientific discovery. 💡


Thinking Less at test-time requires Sampling More at training-time! GFPO is a new, cool, and simple Policy Opt algorithm is coming to your RL Gym tonite, led by @VaishShrivas and our MSR group: Group Filtered PO (GFPO) trades off training-time with test-time compute, in order…



🚨 We're hiring a #ResearchScientist in #AI for Scientific Discovery at Ai2! Are you passionate about intelligent agents, data-driven discovery, and AI systems that accelerate science? Join us in shaping the future of research. 🧬🧠 Apply now: job-boards.greenhouse.io/thealleninstit…

Introducing SciArena, a platform for benchmarking models across scientific literature tasks. Inspired by Chatbot Arena, SciArena applies a crowdsourced LLM evaluation approach to the scientific domain. 🧵

Today we’re releasing a prototype of Genesys, an autonomous multi-agent LLM discovery system that aims to discover new types of language model architectures. We found Genesys can discover novel architectures competitive with the industry-standard transformer. 🧵


✨New edition of our community-building workshop series!✨ Tomorrow at @CVPR, we invite speakers to share their stories, values, and approaches for navigating a crowded and evolving field, especially for early-career researchers. Cheeky title🤭: How to Stand Out in the…

In this #CVPR2025 edition of our community-building workshop series, we focus on supporting the growth of early-career researchers. Join us tomorrow (Jun 11) at 12:45 PM in Room 209 Schedule: sites.google.com/view/standoutc… We have an exciting lineup of invited talks and candid…


Excited to announce AlphaEvolve A powerful AI coding agent developed by our team in @GoogleDeepMind that is able to discover impactful new algorithms for important problems in Maths and Computing by combining the creativity of large language models with automated evaluators.

We've just released HealthBench — a new eval for AI systems for health. Developed with 262 physicians who have practiced in 60 countries.

Evaluations are essential to understanding how models perform in health settings. HealthBench is a new evaluation benchmark, developed with input from 250+ physicians from around the world, now available in our GitHub repository. openai.com/index/healthbe…


Scientific discovery with LLMs has so much potential yet is underexplored. Our new benchmark **LLM-SRBench** enable rigorous evaluations of equation discovery with LLMs! 🧠Key takeaway: Even SOTA discovery models with strong LLM backbones still fail to discover mathematical…


Excited to release R2E-Gym - 🔥 8.1K executable environments using synthetic data - 🧠 Hybrid verifiers for enhanced inference-time scaling - 📈 51% success-rate on the SWE-Bench Verified - 🤗 Open Source Data + Models + Trajectories 1/

Announcing OLMo 2 32B: the first fully open model to beat GPT 3.5 & GPT-4o mini on a suite of popular, multi-skill benchmarks. Comparable to best open-weight models, but a fraction of training compute. When you have a good recipe, ✨ magical things happen when you scale it up!

Here is Tülu 3 405B 🐫 our open-source post-training model that surpasses the performance of DeepSeek-V3! The last member of the Tülu 3 family demonstrates that our recipe, which includes Reinforcement Learning from Verifiable Rewards (RVLR) scales to 405B - with performance on…


Excited to share a sneak peek into what we've been building at Yutori! What you see below is our trained model and internal prototype — multiple agents running in parallel in the background, completing tasks of varying complexity, relevant information and cues to step in being…

Interested in knowing more about LLMs agents and in contributing to this topic?🚀 📢We're thrilled to announce REALM: The first Workshop for Research on Agent Language Models 🤖 #ACL2025NLP in Vienna 🎻 We have an exciting lineup of speakers 🗓️ Submit your work by *March 1st*

Can AI really help with literature reviews? 🧐 Meet Ai2 ScholarQA, an experimental solution that allows you to ask questions that require multiple scientific papers to answer. It gives more in-depth, detailed, and contextual answers with table comparisons, expandable sections…





























































































































United States เทรนด์
- 1. Rickey 1,927 posts
- 2. Westbrook 13.6K posts
- 3. Kings 146K posts
- 4. Maybe in California N/A
- 5. Big Balls 15.8K posts
- 6. Gold Glove 7,166 posts
- 7. Waddle 2,529 posts
- 8. Jakobi Meyers N/A
- 9. Voting Rights Act 19.5K posts
- 10. Justice Jackson 9,315 posts
- 11. Veo 3.1 3,968 posts
- 12. Bessent 78.2K posts
- 13. #wednesdaymotivation 9,082 posts
- 14. Jay Jones 68.5K posts
- 15. Summer Walker 4,774 posts
- 16. Lavine 1,002 posts
- 17. Thorpedo Anna N/A
- 18. Sabonis N/A
- 19. DeRozan N/A
- 20. Brodie 4,644 posts
คุณอาจชื่นชอบ
-
 Zhaofeng Wu
Zhaofeng Wu
@zhaofeng_wu -
 Yuling Gu
Yuling Gu
@gu_yuling -
 Daniel Khashabi 🕊️
Daniel Khashabi 🕊️
@DanielKhashabi -
 Dan Roth
Dan Roth
@DanRothNLP -
 Ana Marasović
Ana Marasović
@anmarasovic -
 Sean Welleck
Sean Welleck
@wellecks -
 Jonathan Berant @ COLM 2025
Jonathan Berant @ COLM 2025
@JonathanBerant -
 Scott Yih
Scott Yih
@scottyih -
 Mandar Joshi
Mandar Joshi
@mandarjoshi_ -
 Ari Holtzman
Ari Holtzman
@universeinanegg -
 Sihao Chen
Sihao Chen
@soshsihao -
 Victoria X Lin
Victoria X Lin
@VictoriaLinML -
 Harsh Trivedi
Harsh Trivedi
@harsh3vedi -
 Valentina Pyatkin
Valentina Pyatkin
@valentina__py -
 Niranjan
Niranjan
@b_niranjan
Something went wrong.
Something went wrong.