
You might like











How should we think about error handling in distributed systems? Let's see what you think: ✅ means you think we should crash the process server, ❌ means you don't.


Turns out you can communicate across containers via 63-bits of available space in a shared lock you acquire on /proc/self/ns/time that all processes have access to. No networking required. The post has a demo of a chat app communicating across unprivileged containers.


If you want to join lovable and work on technical problems with Valthor apply here lovable.dev/careers


Building products takes too long. We started Lovable to fix this. Today, we're officially launching the world’s first AI Full Stack Engineer Lovable reliably replicates the capabilities of a full stack engineer and handles everything from design to database operations by…

I've been exploring this idea of writing informal 'code sketches' as a way of structuring LLM code generation to efficiently capture all the design decisions *I* care about before handoff. Repo here: github.com/westoncb/code-… If there are two things LLMs are super good at it's…

Ahh yes. Recreative programming. So. Much. Fun.


JD has a gift for saying things that are obviously true in the least palatable way imaginable

NEW VANCE AUDIO: In an interview from 2020, JD Vance agrees with a podcast host who says having grandmothers help raise children is “the whole purpose of the postmenopausal female.” He also agrees when the host says grandparents helping raise children is a "weird, unadvertised…

Embedding features learned with sparse autoencoders can make semantic edits to text ✨ (+ a reading/highlighting demo) I've built an interface to explore and visualize GPT-4 labelled features learned from a text embedding model's latent space. Here's a little video, more in 👇

Thought LLMs would be better at this: Given 2 500 token summaries: Does sum 1 mention anything sum 2 doesn't? Goal: Find 4 diffs w/o hallucinating. GPT-4 T:1/4, 4+ Hs GPT4-o:1/4, 4 Hs Command R+:1/4, 1 H L3:1/4, 1 H DeepseekV2: 3/4, 3 Hs Opus: 3/4, 1 H Gemini 1.5: 3/4, 0 H

since I'm deeply immersed in evals right now (and the process of building them) I got a kick out of this paper from @sh_reya @jdzamfi @bjo3rn @adityagp @IanArawjo it addresses the challenge of time-efficiently coming up with evals that are aligned with practitioners some…


When I first saw Tree of Thoughts, I asked myself: If language models can reason better by searching, why don't they do it themselves during Chain of Thought? Some possible answers (and a new paper): 🧵

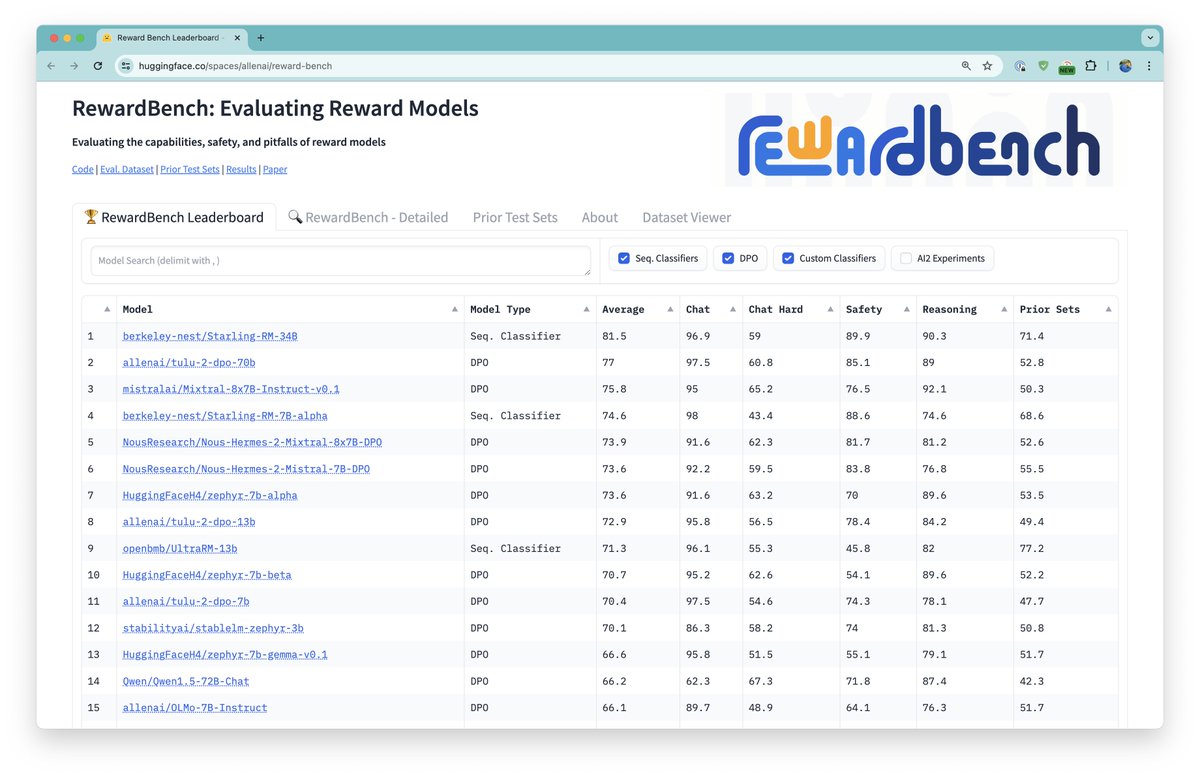
Sharing RewardBench! We delve into the evaluation of reward models, often used to align LLMs to human preferences, across various tasks such as chat, reasoning, code, safety, etc. Hopefully, this work leads to a better understanding of the preference-tuning process :)

Excited to share something that we've needed since the early open RLHF days: RewardBench, the first benchmark for reward models. 1. We evaluated 30+ of the currently available RMs (w/ DPO too). 2. We created new datasets covering chat, safety, code, math, etc. We learned a lot.…



I think there's maybe really something here, look at this. I got GPT to respond to the prompt from this uml.edu/docs/sample-es…. Then I got a sequence of embeddings for each word in both the human- and GPT- authored essays. You can see how the human one moves around more.
I think any point in that sequence is probably not that informative but the trajectory might be highly informative. Intuitively, natural writing isn’t done by always choosing the most likely next token whereas robot writing is and you might be able to see that in the trajectory.

I've updated my auto codebase analyzer, using Qwen-1.5-72b-chat + sglang for large-codebase analysis, is really really good. Now it more clearly highlights important features of the codebase and methods. github.com/cloneofsimo/au…


Today, with @Tim_Dettmers, @huggingface, & @mobius_labs, we're releasing FSDP/QLoRA, a new project that lets you efficiently train very large (70b) models on a home computer with consumer gaming GPUs. 1/🧵 answer.ai/posts/2024-03-…

I am proud to release my newest coding dataset, 143k examples of tested python code. Why train on python code that doesn't work? When you can train on a large variety of tested python code! huggingface.co/datasets/Vezor…


Lots of requests for richer observability in DSPy. In March, @mikeldking & I are holding a DSPy <> @arizeai meetup in SF to show you how to do that w @ArizePhoenix-DSPy integration. Video by @axiomofjoy. Good chance to show something cool with DSPy. What would you like to see?
Happy Valentine’s Day everyone! And happy birthday Dad ❤️(my dad is awesome) Launching a new AI startup out of Europe today. Lovable. Needless to say, we’re very excited about Lovable. We think it will be huge: We’re building software that builds software. See website for…

Have you ever done a dense grid search over neural network hyperparameters? Like a *really dense* grid search? It looks like this (!!). Blueish colors correspond to hyperparameters for which training converges, redish colors to hyperparameters for which training diverges.

🗣️I've been thinking about data quality & human factor in the process a lot lately, so write a short post on the topic: lilianweng.github.io/posts/2024-02-… More: If you are into the topic, my team is hiring Research Engineer for a new sub-team Human-AI Interaction: openai.com/careers/resear…


































































































United States Trends
- 1. TOP CALL 3,625 posts
- 2. #BaddiesUSA 64.7K posts
- 3. #centralwOrldXmasXFreenBecky 480K posts
- 4. SAROCHA REBECCA DISNEY AT CTW 499K posts
- 5. AI Alert 1,280 posts
- 6. #LingOrmDiorAmbassador 256K posts
- 7. Rams 29.8K posts
- 8. Market Focus 2,444 posts
- 9. #LAShortnSweet 23.6K posts
- 10. Check Analyze N/A
- 11. Token Signal 1,723 posts
- 12. Vin Diesel 1,537 posts
- 13. Scotty 10.3K posts
- 14. #MondayMotivation 6,750 posts
- 15. Chip Kelly 9,066 posts
- 16. Ahna 7,796 posts
- 17. Raiders 68K posts
- 18. sabrina 64.6K posts
- 19. DOGE 177K posts
- 20. Stacey 23.2K posts









Something went wrong.
Something went wrong.