
Yong Jae Lee
@yong_jae_lee
Professor, Computer Sciences, UW-Madison. I am a computer vision and machine learning researcher.
قد يعجبك















Super excited for Xueyan @xyz2maureen as she begins her faculty career and builds her lab at Tsinghua! A phenomenal opportunity to work with a brilliant and deeply thoughtful researcher.

I will join Tsinghua University, College of AI, as an Assistant Professor in the coming month. I am actively looking for 2026 spring interns and future PhDs (ping me if you are in #NeurIPS). It has been an incredible journey of 10 years since I attended an activity organized by…

As an AI researcher, are you interested in tracking trends from CV/NLP/ML to robotics—even Nature/Science. Our paper “Real Deep Research for AI, Robotics & Beyond” automates survey generation and trend/topic discovery across fields 🔥Explore RDR at realdeepresearch.github.io

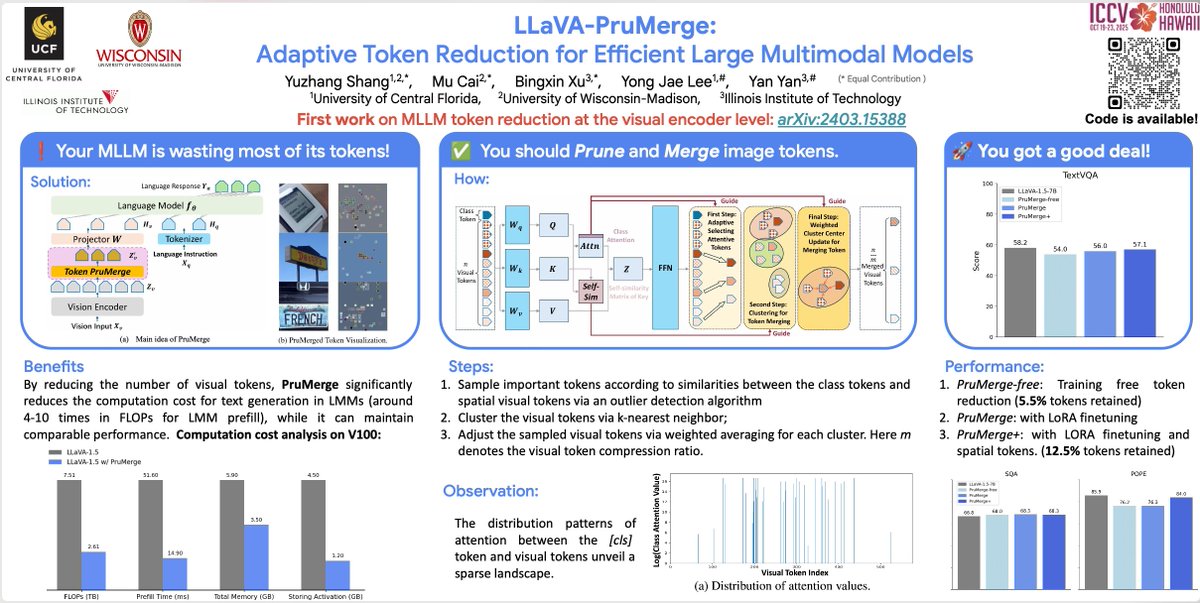
🚀 Excited to present LLaVA-PruMerge this morning at ICCV(can you imagine, finally!). LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models arxiv.org/abs/2403.15388 Exhibit Hall I #287, 11:15-1:15am Work done with amazing @yuzhang_shang, @yong_jae_lee etal

Presenting CuRe at the #ICCV2025 main conference from 230-4 PM at Ex Hall II #76 Drop by if you’re around!
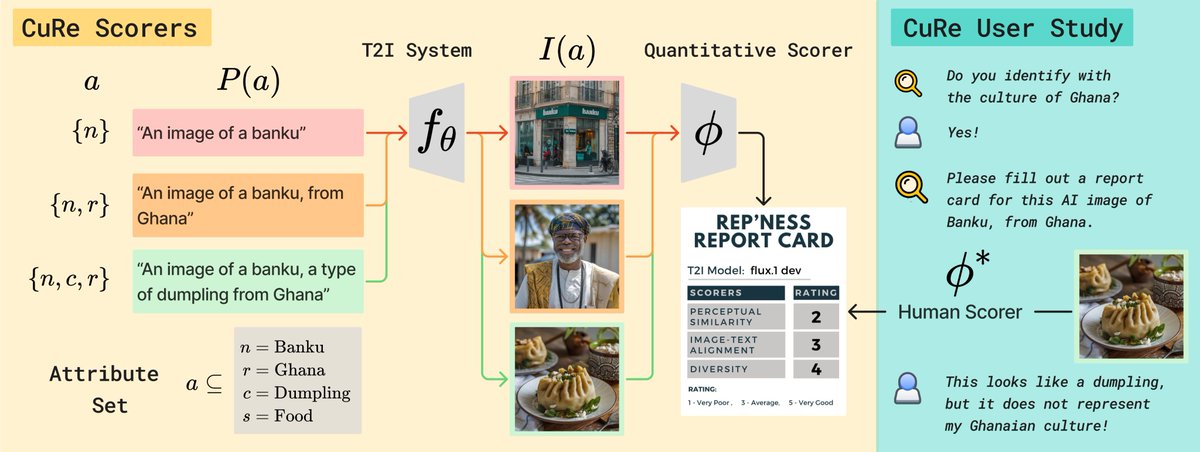
Training text-to-image models? Want your models to represent cultures across the globe but don't know how to systematically evaluate them? Introducing ⚕️CuRe⚕️ a new benchmark and scoring suite for cultural representativeness through the lens of information gain (1/10)
Here is the final decision for one of our NeurIPS D&B ACs-accepted-but-PCs-rejected papers, with the vague message mentioning some kind of ranking. Why was the ranking necessary? Venue capacity? If so, this sets a concerning precedent. @NeurIPSConf

I have two D&B papers in the same situation: ACs recommended accept, but PCs overruled and rejected with the same exact vague reason that you got. They should at least provide a proper reason.

My students called the new CDIS building “state-of-the-art”. I thought they were exaggerating. Today I moved in and saw it for myself. Wow. Photos cannot capture the beauty of the design.





#ICCV2025 Introducing X-Fusion: Introducing New Modality to Frozen Large Language Models It is a novel framework that adapts pretrained LLMs (e.g., LLaMA) to new modalities (e.g., vision) while retaining their language capabilities and world knowledge! (1/n) Project Page:…
LLaVA-Prumerge, the first work of Visual Token Reduction for MLLM, finally got accepted after being cited 146 times since last year. Congrats to the team! @yuzhang_shang @yong_jae_lee See how to do MLLM inference much cheaper while holding performance. llava-prumerge.github.io

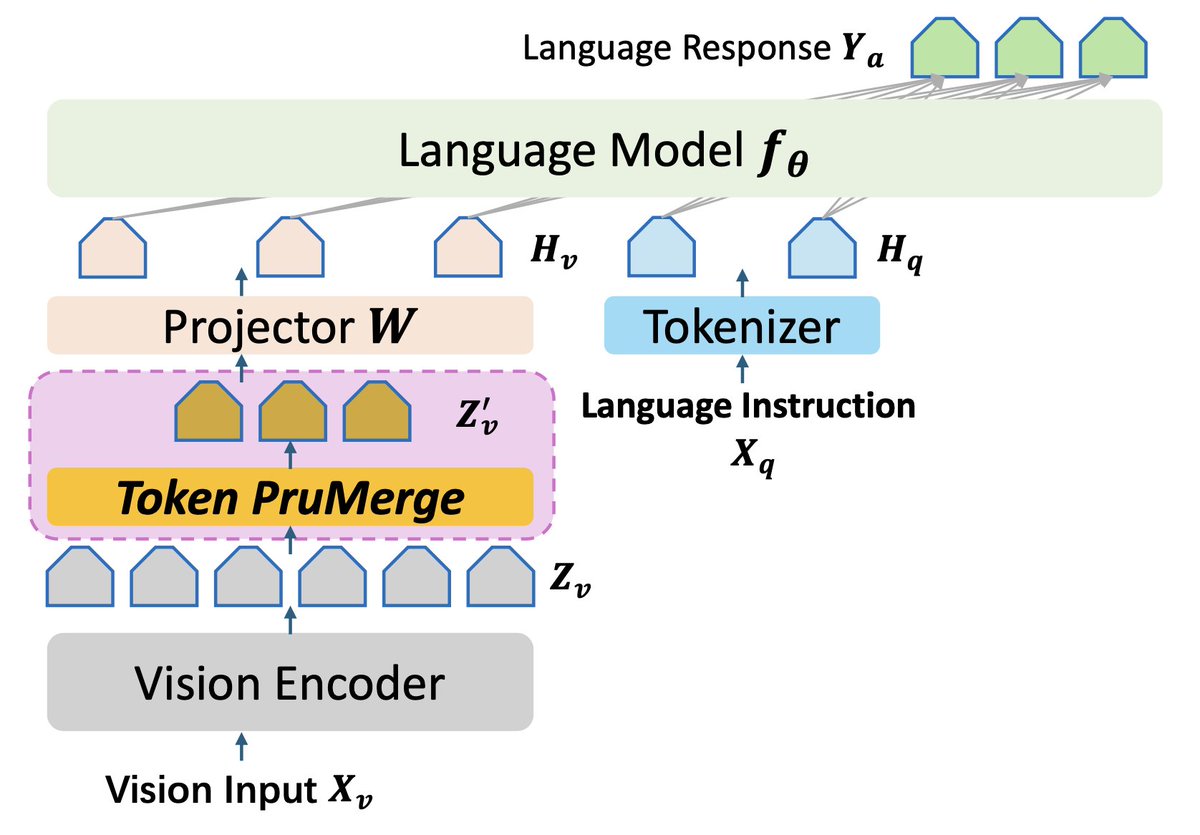
visual tokens in current large multimodal models are spatially redundant, indicated by the sparse attention maps. LLaVA-PruMerge proposes to first prune and then merge visual tokens, which can compress the visual tokens by 18 times (14 times on MME/TextVQA) on average while…
Training text-to-image models? Want your models to represent cultures across the globe but don't know how to systematically evaluate them? Introducing ⚕️CuRe⚕️ a new benchmark and scoring suite for cultural representativeness through the lens of information gain (1/10)


Congratulations Dr. Mu Cai @MuCai7! Mu is my 8th PhD student and first to start in my group at UW–Madison after my move a few years ago. He made a number of important contributions in multimodal models during his PhD, and recently joined Google DeepMind. I will miss you a lot Mu!


🚀 Excited to announce our 4th Workshop on Computer Vision in the Wild (CVinW) at @CVPR 2025! 🔗 computer-vision-in-the-wild.github.io/cvpr-2025/ ⭐We have invinted a great lineup of speakers: Prof. Kaiming He, Prof. @BoqingGo, Prof. @CordeliaSchmid, Prof. @RanjayKrishna, Prof. @sainingxie, Prof.…


Public service announcement: Multimodal LLMs are really bad at understanding images with *precision*. x.com/lukeprog/statu… A thread🧵: 1/13.

Tyler Cowen: "I've seen enough, I'm calling it, o3 is AGI" Meanwhile, o3 in response to the first prompt I give it:
Congratulations again @MuCai7!! So well deserved. I will miss having you in the lab.
I am thrilled to join @GoogleDeepMind as a Research Scientist and continue working on multimodal research!



























































































United States الاتجاهات
- 1. #GivingTuesday 15K posts
- 2. The BIGGЕST 426K posts
- 3. #JUPITER 233K posts
- 4. #ALLOCATION 235K posts
- 5. #csm222 N/A
- 6. Lucario 14.5K posts
- 7. Costco 38.3K posts
- 8. #NXXT_NEWS N/A
- 9. Good Tuesday 39.4K posts
- 10. Susan Dell 2,477 posts
- 11. NextNRG Inc 1,263 posts
- 12. Michael and Susan 1,715 posts
- 13. Trump Accounts 7,876 posts
- 14. Hoss Cartwright N/A
- 15. Taco Tuesday 13.5K posts
- 16. King Von 1,110 posts
- 17. Dart 43.1K posts
- 18. Isack 15.3K posts
- 19. Project M 22.3K posts
- 20. Kanata 29.6K posts
قد يعجبك
-
 Yin Cui
Yin Cui
@YinCuiCV -
 Judy Hoffman
Judy Hoffman
@judyfhoffman -
 Richard Zhang
Richard Zhang
@rzhang88 -
 Jun-Yan Zhu
Jun-Yan Zhu
@junyanz89 -
 Kate Saenko
Kate Saenko
@kate_saenko_ -
 Hang Zhao
Hang Zhao
@zhaohang0124 -
 Bolei Zhou
Bolei Zhou
@zhoubolei -
 Adam W. Harley
Adam W. Harley
@AdamWHarley -
 Zhuang Liu
Zhuang Liu
@liuzhuang1234 -
 Boqing Gong
Boqing Gong
@BoqingGo -
 Tai Wang
Tai Wang
@wangtai97 -
 Yejin Choi
Yejin Choi
@YejinChoinka -
 Huaizu Jiang
Huaizu Jiang
@HuaizuJiang -
 Vincent Sitzmann
Vincent Sitzmann
@vincesitzmann -
 Angela Dai
Angela Dai
@angelaqdai
Something went wrong.
Something went wrong.