
Yongmin Kim
@yongmini97
PhD. student at the University of Tokyo. at Matuso ・ Iwasawa Lab
🥳Excited to share that our paper has been accepted to @COLM_conf, which will be held next month! Great thanks to my advisors @kojima_tks, Yusuke Iwasawa, and @ymatsuo. Looking forward to meeting many researchers and having insightful discussions at @COLM_conf!
While LMs excel across domains, they risk generating toxic content. Detoxification methods exist but degrade performance. Can model merging decouple noise/toxic parameters for detoxification? We explore this by comparing merged vs. existing models. openreview.net/pdf?id=TBNYjdO… 🧵

💍 LFM2-ColBERT-350M: One Model to Embed Them All Very happy to announce our first embedding model! It's a late interaction retriever with excellent multilingual performance. Available today on @huggingface!

New LFM2 release 🥳 It's a Japanese PII extractor with only 350M parameters. It's extremely fast and on par with GPT-5 (!) in terms of quality. Check it out, it's available today on @huggingface!
LFM2-8B-A1B just dropped on @huggingface! 8.3B params with only 1.5B active/token 🚀 > Quality ≈ 3–4B dense, yet faster than Qwen3-1.7B > MoE designed to run on phones/laptops (llama.cpp / vLLM) > Pre-trained on 12T tokens → strong math/code/IF

Hello Japan! 🇯🇵 Want to join a 2-day in-person hackathon co-hosted by Liquid AI and @weights_biases? Developers and AI researchers from around the world will gather to help shape the future of AI in Japan! This hackathon’s theme is “Push SLM models to the limit.” The selected…


Discord invite? Is Discord open to all? It seems gated (unless I was looking at the wrong invite perma url)
Liquid just released two 450M and 1.6B param VLMs! They're super fast and leverage SigLIP2 NaFlex encoders to handle native resolutions without distortion. Available today on @huggingface!
Try LFM2 with llama.cpp today! We released today a collection of GGUF checkpoints for developers to run LFM2 everywhere with llama.cpp Select the most relevant precision for your use case and start building today. huggingface.co/LiquidAI/LFM2-…

Liquid AI open-sources a new generation of edge LLMs! 🥳 I'm so happy to contribute to the open-source community with this release on @huggingface! LFM2 is a new architecture that combines best-in-class inference speed and quality into 350M, 700M, and 1.2B models.

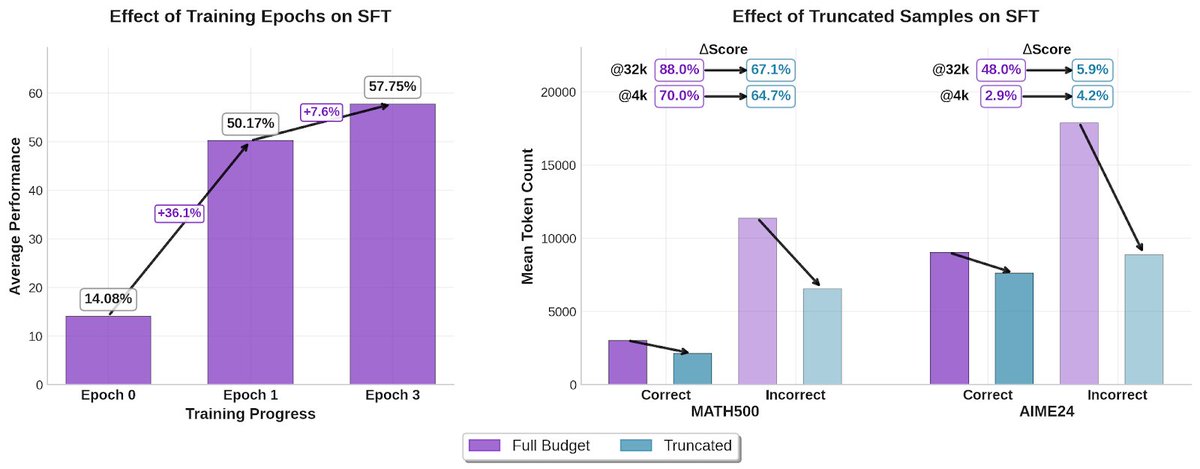
🤏 Can small models be strong reasoners? We created a 1B reasoning model at @LiquidAI_ that is both accurate and concise We applied a combination of SFT (to raise quality) and GRPO (to control verbosity) The result is a best-in-class model without specific math pre-training

What is the key difference between recent reasoning models and their base counterparts? Our new preprint reveals that reasoning models build distinctive “Reasoning Graphs” from their hidden states, characterized by more cycles, larger diameters, and stronger local connectivity.
Our paper "Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence" has accepted at #ICML2025🎉 We found training Transformers in a few-shot setting leads to the emergence of 3 circuits. Joint work with @frt03_ @ishohei220 @yusuke_iwasawa_ @ymatsuo

🍻Two co-authored papers have been accepted to #ACL2025NLP🍻 Congrats to Andrew-san and Takashiro-san!

🐥Our paper "Continual Pre-training on Character-Level Noisy Texts Makes Decoder-based Language Models Robust Few-shot Learners" has been accepted to #TACL🐥 We are now planning to make a presentation at #ACL2025NLP ! weblab.t.u-tokyo.ac.jp/news/2025-0502/

🌈Our paper "Slender-Mamba: Fully Quantized Mamba in 1.58 Bits From Head to Toe" has been accepted to #coling2025 🌈 We apply BitNet b1.58 quantization to Mamba2 architecture including embedding and head layers to accelerate further lightweighting. Congrats @UTLLM_zxYu !

🤗Our paper "Which Programming Language and What Features at Pre-training Stage Affect Downstream Logical Inference Performance?" has been accepted to #EMNLP2024 🤗 Congrats @FumiyaUchiyama! Read the following post for the details!

Excited to show that our paper has been accepted to #EMNLP2024 ! We investigated the effect of pretraining on code data by training LMs from scratch with a single programming language / natural language corpus and confirmed consistent improvements on FLD and bAbi benchmark.










































































United States Tendencias
- 1. #HardRockBet 2,614 posts
- 2. #AskFFT N/A
- 3. StandX 1,750 posts
- 4. #sundayvibes 6,650 posts
- 5. Scott Adams 11.8K posts
- 6. Full PPR 1,450 posts
- 7. #2YearsWithGolden 24.8K posts
- 8. Nigeria 966K posts
- 9. Go Bills 7,081 posts
- 10. Good Sunday 73.4K posts
- 11. JUNGKOOK IS GOLDEN 26.7K posts
- 12. #NicxStrava 3,565 posts
- 13. Navy Federal N/A
- 14. Carlos Manzo 519K posts
- 15. West Ham 7,951 posts
- 16. Alec Pierce N/A
- 17. Sunday Funday 3,928 posts
- 18. Bam Knight N/A
- 19. Parker Washington N/A
- 20. Dowdle 1,956 posts
Something went wrong.
Something went wrong.