#modelquantization search results

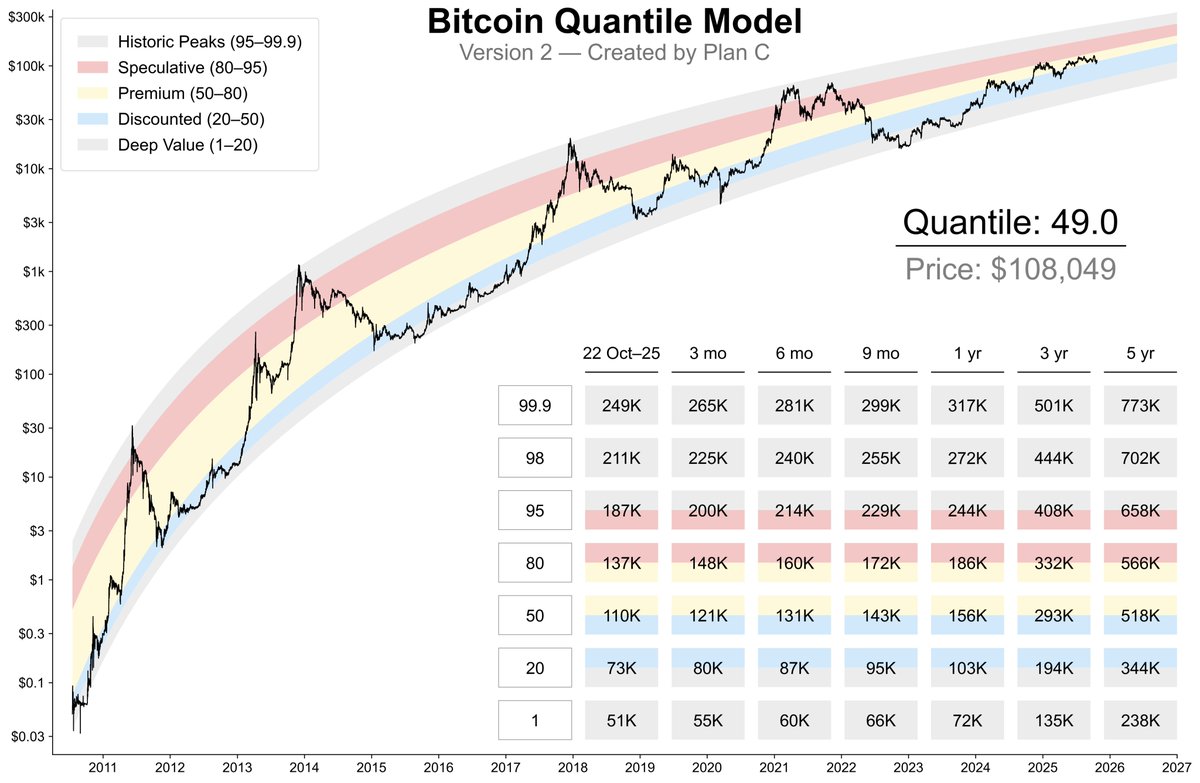
The wait is over! Introducing... 🥁 Bitcoin Quantile Model v2. You’re going to want to bookmark this post—and follow for regular model updates. After months of research and development, I’m very proud of this model—my flagship quantile framework. I’m confident it’s one of…


Releasing QuTLASS v0.2: fast, end-to-end quantization-aware training (QAT) with kernel support and applications! 1. Nanochat-QAT: a fully-quantized extension of @karpathy 's nanochat 2. General QAT recipe with MXFP4 forward/MXFP8 backward GEMMs 3. Transformers/vLLM integrations




⚡️ GPT-QModel v5.2 released with Minimax M2, Qwen3-VL, Granite Nano model support and first-class AWQ integration! 👇

🥳GPT-QModel v5.2! 🤗 So pumped for this huge release coming only a week after v5.0. 🤯 Minimax M2, Granite Nano, Qwen3-VL support 🌟AWQ out of beta and fully integrated with more features and model support than autoawq ⚡️New VramStrategy.Balanced to quant large MoE models…


🚀 Excited to launch Qwen3 models in MLX format today! Now available in 4 quantization levels: 4bit, 6bit, 8bit, and BF16 — Optimized for MLX framework. 👉 Try it now! Huggingface:huggingface.co/collections/Qw… ModelScope: modelscope.cn/collections/Qw…


Efficient training of neural networks is difficult. Our second Connectionism post introduces Modular Manifolds, a theoretical step toward more stable and performant training by co-designing neural net optimizers with manifold constraints on weight matrices.…

We will release the quantized models of Qwen3 to you in the following days. Today we release the AWQ and GGUFs of Qwen3-14B and Qwen3-32B, which enables using the models with limited GPU memory. Qwen3-32B-AWQ: huggingface.co/Qwen/Qwen3-32B… Qwen3-32B-GGUF: huggingface.co/Qwen/Qwen3-32B……



$IONQ press release -- experiment did not actually use a quantum computer, only a simulator 😂 willing to PR anything


the FP8 values in your model after 50 layers of quantize/dequantize operations

📄 Paper highlight #05: “Quantization Error Propagation: Revisiting Layer-Wise Post-Training Quantization” 🔥 Personal hot take: Layers are not independent when optimizing Post-Training Quantization (PTQ). Appropriate quantization but also fine-tuning can also mitigate…


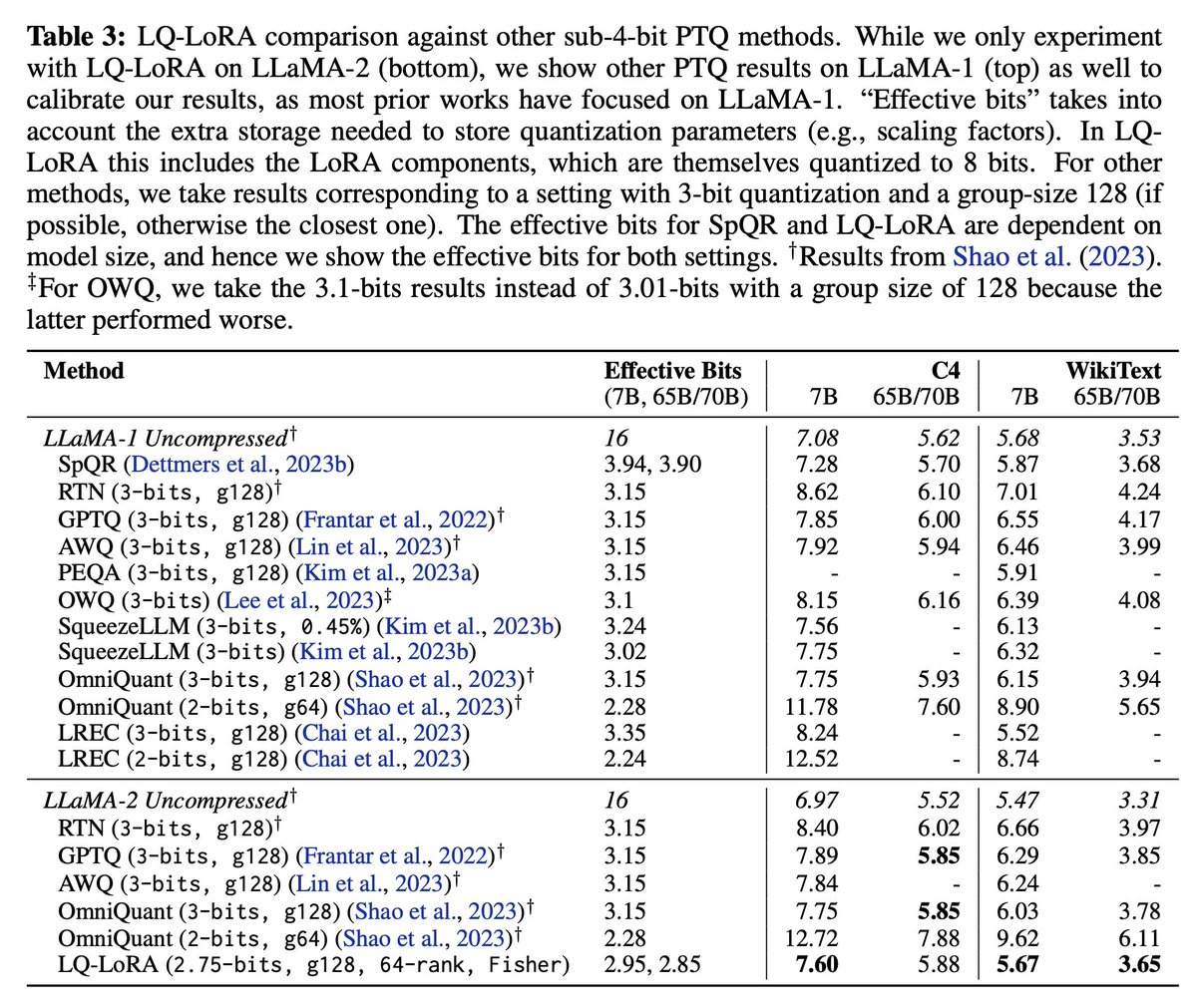
Introducing LQ-LoRA Decomposing pretrained matrices into (fixed) quantized + (trainable) low-rank components enables more aggressive quantization. We can quantize LLaMA-2 70B to 2.5 bits with minimal degradation in instruction-tuning performance. arxiv.org/abs/2311.12023 🧵1/n

We're releasing the DASLab GGUF Quantization Toolkit! 🚀 First open-source toolkit bringing GPTQ + EvoPress to @ggerganov's GGUF format, enabling heterogeneous quantization based on importance. Result: Better models at the same file size. [1/5]
![DAlistarh's tweet image. We're releasing the DASLab GGUF Quantization Toolkit! 🚀
First open-source toolkit bringing GPTQ + EvoPress to @ggerganov's GGUF format, enabling heterogeneous quantization based on importance.
Result: Better models at the same file size.
[1/5]](https://pbs.twimg.com/media/G04P11lXoAAvtcK.jpg)

Happy to share a paper we wrote at Apple — “Compute-Optimal Quantization-Aware Training”! TLDR: Treat QAT as a first-class citizen and plan it in advance if you want to achieve the best quantized model with the compute you have. arxiv.org/abs/2509.22935 🧵🧵🧵

We’re officially releasing the quantized models of Qwen3 today! Now you can deploy Qwen3 via Ollama, LM Studio, SGLang, and vLLM — choose from multiple formats including GGUF, AWQ, and GPTQ for easy local deployment. Find all models in the Qwen3 collection on Hugging Face and…


Advancing Edge Deployments: Solutions for Language Models Optimisation 🌐 #ModelQuantization: Reduces model size and computational needs. 🔧 Parameter-Efficient #FineTuning: Optimizes specific parameters for efficiency. 🔀 #SplitLearning: Divides workloads between devices and…



Quantization Is All You Need SOTA LLMs are too large to run on laptops. Quantization is a technique used to reduce LLMs' computational and memory requirements and create a smaller version of the model. Quantization is central to OSS progress It involves converting the model's…

Quantile Model Update Some small improvements. - Added the 98th quantile to the grid. - 16:9 to 3:2 aspect ratio to provide more vertical space.

quantized versions of an LLM can beat the original non-quantized one? does that make MT-Bench a bad benchmark?


Sharing our second Connectionism research post on Modular Manifolds, a mathematical approach to refining training at each layer of the neural network
Efficient training of neural networks is difficult. Our second Connectionism post introduces Modular Manifolds, a theoretical step toward more stable and performant training by co-designing neural net optimizers with manifold constraints on weight matrices.…

You can now quantize LLMs to 4-bit and recover 70% accuracy via Quantization-Aware Training. We teamed up with @PyTorch to show how QAT enables: • 4x less VRAM with no inference overhead • 1-3% increase in raw accuracy (GPQA, MMLU Pro) Notebook & Blog: docs.unsloth.ai/new/quantizati…


AI model quantization tools reduce size by 70%, enabling deployment on low-cost IoT devices. Scale to 100M+ edge devices. @PublicAIData #ModelQuantization #EdgeScaling

✨This paper thoroughly evaluated the robustness of quantized models against various types of noise. 📸 🔗Read more: link.springer.com/article/10.100… #Modelquantization #Modelrobustness #Robustnessbenchmark


. @soon_svm #SOONISTHEREDPILL Quantization of models can save memory. Soon_SVM supports quantization. It reduces memory footprint through quantization. Quantize models with Soon_SVM. #Soon_SVM #ModelQuantization
#ModelQuantization: FP16, INT8, and Beyond quantization cuts memory use and boosts speed by reducing precision. main methods: 🔹 post-training quantization (PTQ): turns #FP32 models to #FP16 or #INT8; quick but may reduce accuracy. 🔸 quantization-aware training (QAT):…

Advancing Edge Deployments: Solutions for Language Models Optimisation 🌐 #ModelQuantization: Reduces model size and computational needs. 🔧 Parameter-Efficient #FineTuning: Optimizes specific parameters for efficiency. 🔀 #SplitLearning: Divides workloads between devices and…

Deep Neural Network Quantization Framework for Effective Defense against Membership Inference Attacks mdpi.com/1424-8220/23/1… @ClemsonUniv #membershipinferenceattack; #modelquantization; #deepneuralnetwork


ねえ、LLM を縮小したよ!量子化の初心者向けガイド • The Register #LLMquantization #ModelQuantization #ModelCompression #AIModelQuantization prompthub.info/26663/


Discover how model quantization supercharges neural networks, making massive AI models lightning-fast and memory-efficient for everyday devices! Read More: infoworld.com/article/371529… #AI #MachineLearning #ModelQuantization #TechInnovation #NeuralNetworks


Big matrix, small server? Quantization to the rescue! Reduced my 500MB collab filtering model to ~60MB with float8, all thanks to #modelquantization! Check out the demo: pick-1-movie.streamlit.app #machinelearning #optimizations

Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/HTL0S #TechInnovation #CausalReasoning #ModelQuantization


Discover the future of AI with model quantization. This method reduces computational cost, increases speed, and maintains accuracy. A game-changer for machine learning applications. #AI #ModelQuantization @cheatlayer #chatgpt

Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/dYM1V #TechInnovation #CausalReasoning #ModelQuantization


Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/Hs2sH #TechInnovation #CausalReasoning #ModelQuantization


Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/XPQb3 #TechInnovation #CausalReasoning #ModelQuantization


Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/AjZCk #TechInnovation #CausalReasoning #ModelQuantization


Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/HpBus #TechInnovation #CausalReasoning #ModelQuantization


Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/BxESc #TechInnovation #CausalReasoning #ModelQuantization


Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/a8tag #TechInnovation #CausalReasoning #ModelQuantization


Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/wNWEf #TechInnovation #CausalReasoning #ModelQuantization


RT Inference Optimization for Convolutional Neural Networks dlvr.it/SQhHM1 #modelinference #optimization #modelquantization #deeplearning

Advancing Edge Deployments: Solutions for Language Models Optimisation 🌐 #ModelQuantization: Reduces model size and computational needs. 🔧 Parameter-Efficient #FineTuning: Optimizes specific parameters for efficiency. 🔀 #SplitLearning: Divides workloads between devices and…
Deep Neural Network Quantization Framework for Effective Defense against Membership Inference Attacks mdpi.com/1424-8220/23/1… @ClemsonUniv #membershipinferenceattack; #modelquantization; #deepneuralnetwork
Discover how model quantization supercharges neural networks, making massive AI models lightning-fast and memory-efficient for everyday devices! Read More: infoworld.com/article/371529… #AI #MachineLearning #ModelQuantization #TechInnovation #NeuralNetworks
#ModelQuantization: FP16, INT8, and Beyond quantization cuts memory use and boosts speed by reducing precision. main methods: 🔹 post-training quantization (PTQ): turns #FP32 models to #FP16 or #INT8; quick but may reduce accuracy. 🔸 quantization-aware training (QAT):…
Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/XPQb3 #TechInnovation #CausalReasoning #ModelQuantization

Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/JIcbB #TechInnovation #CausalReasoning #ModelQuantization

Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/a8tag #TechInnovation #CausalReasoning #ModelQuantization
Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/BxESc #TechInnovation #CausalReasoning #ModelQuantization

Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - techblog.cisco.com/blog/unleashin… #TechInnovation #CausalReasoning #ModelQuantization


Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/F8DgG #TechInnovation #CausalReasoning #ModelQuantization


Inference Optimization for Convolutional Neural Networks dlvr.it/SQhH06 #modelinference #optimization #modelquantization

Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/AjZCk #TechInnovation #CausalReasoning #ModelQuantization
Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/HTL0S #TechInnovation #CausalReasoning #ModelQuantization

Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/M4Stp #TechInnovation #CausalReasoning #ModelQuantization

Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/Hs2sH #TechInnovation #CausalReasoning #ModelQuantization

Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/BXmH6 #TechInnovation #CausalReasoning #ModelQuantization


Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/90K4y #TechInnovation #CausalReasoning #ModelQuantization


Exploring Causal Reasoning in Data-Free Model Quantization: Unleashing New Power! - oal.lu/1MKpP #TechInnovation #CausalReasoning #ModelQuantization

Something went wrong.
Something went wrong.
United States Trends
- 1. #Skol 1,226 posts
- 2. Charlie Jones 1,274 posts
- 3. LaPorta 2,914 posts
- 4. #HardRockBet 3,669 posts
- 5. #OnePride 1,460 posts
- 6. Theo Johnson N/A
- 7. Cody Barton N/A
- 8. #HereWeGo 1,955 posts
- 9. Scott 112K posts
- 10. Justin Jefferson 1,290 posts
- 11. #AskFFT N/A
- 12. JJ McCarthy 1,236 posts
- 13. JJ to JJ 5,783 posts
- 14. Haaland 47.5K posts
- 15. Highsmith N/A
- 16. Savion Williams N/A
- 17. Richard Hightower N/A
- 18. Darius Slay N/A
- 19. Alec Pierce N/A
- 20. Cherki 26.4K posts