#emnlp2020 search results

So many fascinating ideas at yesterday's #blackboxNLP workshop at #emnlp2020. Too many bookmarked papers. Some takeaways: 1- There's more room to adopt input saliency methods in NLP. With Grad*input and Integrated Gradients being key gradient-based methods.


من مشاركة فريق #بيان في ورشة عمل NLP for COVID-19 Workshop (Part 2) من مؤتمر #emnlp2020 ✨ #EMNLP2020



Having scalability issues with your ODQA systems?🆘 Adaptive Computation can help! We find that adaptive computation and global scheduling can reduce computation by 4.3x while retaining 95% of the accuracy on SQuAD-Open!🚀 #EMNLP2020 arxiv.org/abs/2011.05435 [1/5]

At the #nlpcss workshop at EMNLP, @dongng gave a wonderful overview of recent work in computational sociolinguistics. Some points: how do we "evaluate" our methods for detecting variation without ground truth data? How can we highlight speaker agency in variation? #emnlp2020





#EMNLP2020 We’ve released 1.2 million reviews in 6 languages in the Multilingual Amazon Reviews Corpus (MARC)! w/ Y. Lu G. Szarvas @nlpnoah arxiv.org/abs/2010.02573 The dataset was carefully cleaned and is balanced across star ratings. Try it out at registry.opendata.aws/amazon-reviews… 1/3


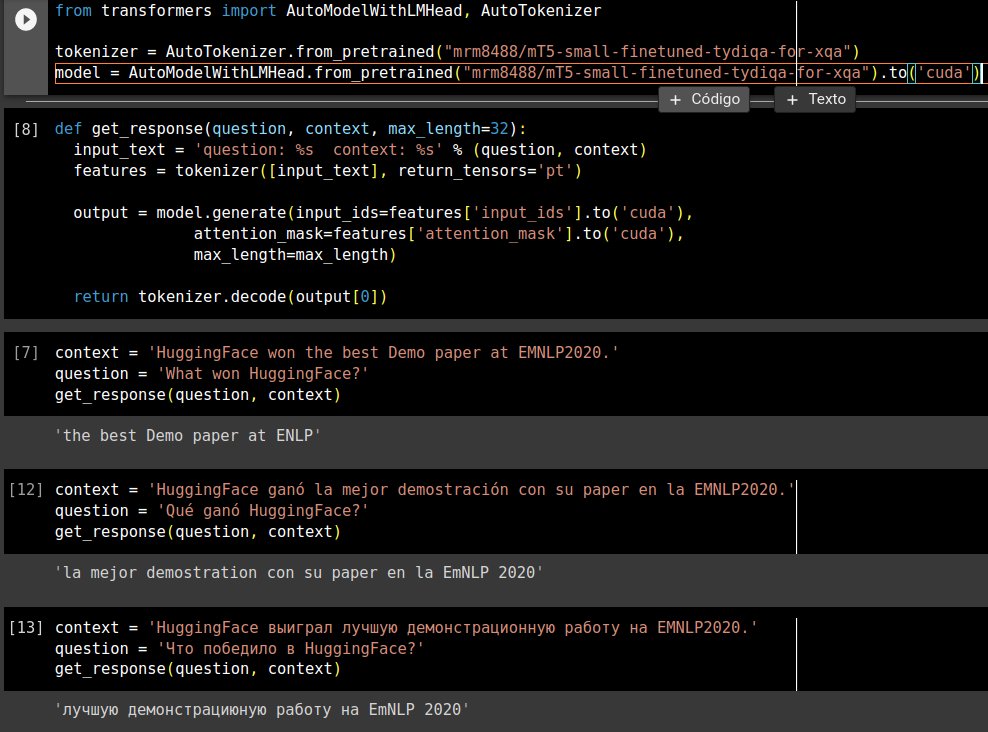
My 'present' to @huggingface for being awarded as Best Demo Paper at #emnlp2020. mT5-small fine-tuned on tydiQA for multilingual QA. EM = 41.65 huggingface.co/mrm8488/mT5-sm…




Check out our #emnlp2020 paper now on arXiv: we develop an energy-based version of BERT called "Electric" and show this essentially re-invents the ELECTRA pre-training method. Electric is useful for re-ranking the outputs of text generation systems. arxiv.org/pdf/2012.08561….


Happy New Year! 🥳 The recording from our #emnlp2020 Panel Discussion on Research in NLP & AI as a North African is now available: youtu.be/_oFnAeCt-EE For more: @NorthAfricanNLP


We are honored to be awarded the Best Demo Paper for "Transformers: State-of-the-Art Natural Language Processing" at #emnlp2020 😍 Thank you to our wonderful team members and the fantastic community of contributors who make the library possible 🤗🤗🤗 aclweb.org/anthology/2020…


#NLPCOVID19 Workshop at #EMNLP2020 Best Paper Award announcement: "COVIDLIES: Detecting COVID-19 Misinformation on Social Media" from Tamanna Hossain, Robert Logan IV, Arjuna Ugarte, Yoshitomo Matsubara, Sean Young, & Sameer Singh at UC Irvine aclweb.org/anthology/2020… Congrats!


Grammatical Error Correction in Low Error Density Domains: A New Benchmark and Analyses. Our #EMNLP2020 paper releasing a new type of error correction dataset, focusing on realistic web text. Join for the virtual poster session, 18 Nov 18:00 UTC. #NLProc


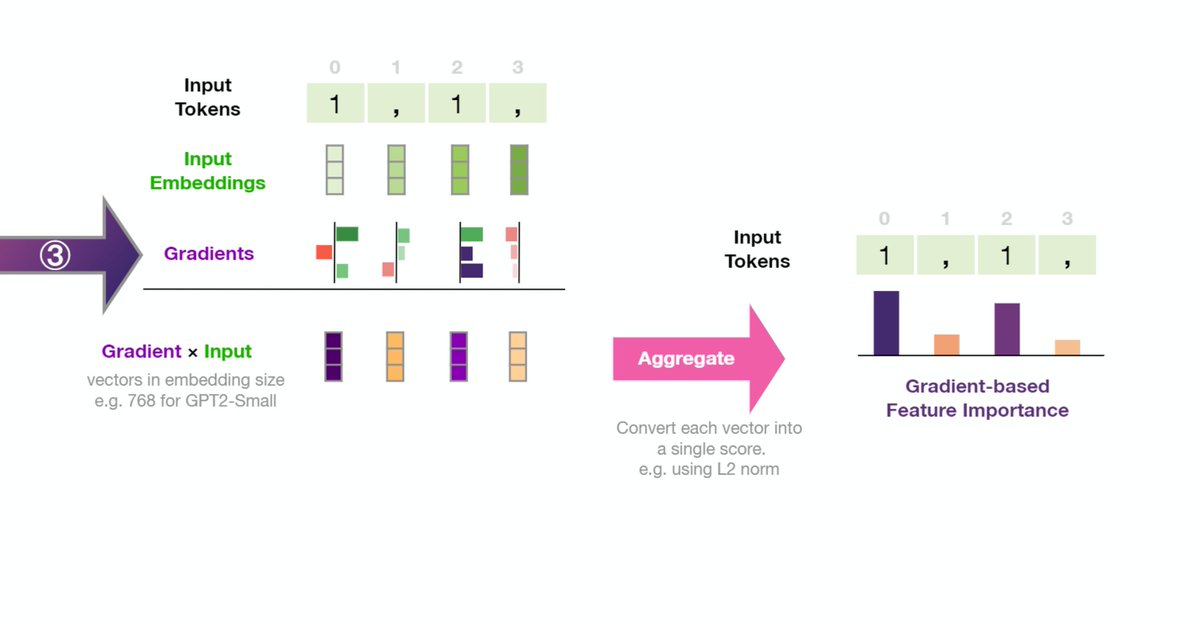
We are giving an #emnlp2020 tutorial on "Interpreting Predictions of NLP Models". Come join me, @nlpmattg, and @sameer_ LIVE Thursday (tomorrow) at 15:00-19:30 UTC time (7-11:30 Pacific). Slides here: github.com/Eric-Wallace/i… Video available afterward


How do you control the generated caption to discuss an issue in the image, such as the color of a wall or a baseball player's position? Join discussion at @conll_conf 11/20. Joint work with @ChrisGPotts and Reuben. To appear in EMNLP Findings #emnlp2020 @stanfordnlp Thread 1/6






Congrats to the winners of the best paper awards at the #EMNLP2020 Workshop on Noisy Text! noisy-text.github.io/2020/pdf/2020.… noisy-text.github.io/2020/pdf/2020.…


Join us for a tutorial on Fake News at #EMNLP2020 propaganda.math.unipd.it/emnlp20-tutori… #fakenews #disinformation #NLProc @giodsm


#EMNLP2020: It is always a pleasure to serve the NLP community by reviewing papers from its top conferences. Even more pleasant to know that a good job was done, and that hopefully our comments and suggestions were useful to the papers’ authors.


(1/n) Can NLP models learn like humans within a single pass of a continuously evolving data stream? We explore this in our #emnlp2020 VisCOLL problem setup (with new datasets!) w/ @xiangrenNLP @ArkaSadhu29 Paper: arxiv.org/abs/2005.00785 Project page: inklab.usc.edu/viscoll-project

Great talk by @MonicaNAgrawal at #EMNLP2020!

Interesting work in clinical NLP. Large language models are few-shot clinical information extractors #EMNLP2022 #EMNLP2022livetweet


We are live with our demo #emnlp2020! If you are interested in interpretable evaluation of KG embeddings, come and chat with me on Demo 3 booth.

Checkout our demo tomorrow at 09:00 on #emnlp2022 "KGxBoard: Explainable and Interactive Leaderboard for Evaluation of Knowledge Graph Completion Models". With KGxBoard, you can discover what exactly a model has learned—or failed to learn. Joint work with @LTIatCMU & @dwsunima 1/

@nazneenrajani from @huggingface at #EMNLP2020 presenting the distribution of language in models. Spanish is the second after English, but look at the difference!!!


Wondered if it was accepted #emnlp2020 or sent to eacl. Great work. Btw, if you know how I managed to offend your supervisor, tell me, as I don't think I know him personally and try to be polite even though I don't hide my criticism (even in this thread).

Two other aspects that made rocketchat useful at #EMNLP2020: The paper channels were embedded next to the paper video. You could read their content without extra clicks and decide whether to suscribe The members that suscribed were visible, you knew who was hearing

#EMNLP2020 でも発表したGraph Attention Networksを用いた対話の感情分析手法です。 従来のGraph Neural Networks系の手法では発話の順序を考慮できない場合が多いのですが、Position Encodingsを応用して発話順序を特徴量として扱うことで感情推定の精度が向上しました。 nhk.or.jp/strl/publica/r…

Our pick of the week: Masaaki Nagata et al. #emnlp2020 paper "A Supervised Word Alignment Method based on Cross-Language Span Prediction using Multilingual BERT". By @DennisFucci aclanthology.org/2020.emnlp-mai… #nlproc

Happy to read about a supervised word alignment approach that requires only few hundred training sentences to achieve high performance. The alignment is framed as a SQuAD-style span prediction task, solved using multilingual BERT. aclanthology.org/2020.emnlp-mai… @fbk_mt

Top short papers related to Discourse and Pragmatics, which award as EMNLP2020 onikle.com/chronicle/1052/ #NLP #EMNLP2020

This might have been The #emnlp2020 paper by @annargrs and me about improving peer review: aclanthology.org/2020.findings-…

"The Ups and Downs of Word Embeddings" by @radamihalcea Word embeddings have largely been a “success story” in #NLProc. Less talked about, are shortcomings like instability, lack of transparency, biases, and more. #emnlp2020 #MachineLearning #bias slideslive.com/38940633/the-u…


There are certainly technical challenges (latency/etc), not sure how easy those are to fix. The usability issues are very fixable, @underlineio just doesn't seem interested in fixing them (e.g., the poster finding issue wasn't a problem at #EMNLP2020). Thanks for attending!
Unfortunately I don't think so. #EMNLP2021 is going to use underline while #EMNLP2020 used miniconf+slideshare+rocketchat. The #NLProc people discussions are clear on which is better. See for example:
While Miniconf + Rocketchat wasn't perfect, I'm fairly certain its much better than underline at #acl2021nlp. Posters were easier to find, rocket chat was far better for async discussion, pages loaded quickly, things like author names/order were done correctly the first time...
Why is virtual participation in the hybrid #EMNLP2021 more expensive (Regular at $200 and Student at $75) than it was in the fully virtual #EMNLP2020 (Regular at $150 and Student at $50)? This is a question for the @emnlpmeeting and the #NLProc community.

thanks, yes our co-author in this work Prof. Frey (+ also in shiyue's prev #emnlp2020 paper) is a citizen of Eastern Band of Cherokee Indians (unc.edu/discover/savin…) + we got expert data+demo feedback from Cherokee citizens eg David Montgomery (cherokeephoenix.org/news/american-…)

We thank reviewers for helpful comments & David Montgomery, Barnes Powell, Tom Belt for testing our system & providing valuable feedback. We thank @huggingface (@YJernite @Thom_Wolf) for hosting our #emnlp2020 data (huggingface.co/datasets/chr_en) & our demo will move to HF soon 🤗

At #EMNLP2020, our researchers presented a weakly-supervised deep co-training-based method that can extract various clinical aspects from a large pool of unlabeled clinical trial eligibility criteria-bit.ly/2UrTdoT #research #COVID19 #healthcare #scicomm #AcademicTwitter


Very thrilled 🤩 to give an extended talk about our #EMNLP2020 paper, Modeling the Music Genre Perception across Language-Bound Cultures / Modéliser la perception des genres musicaux à travers différentes cultures à partir de ressources linguistiques, at #TALN2021 @researchdeezer

We presented some experiments on #VisualGenome scene graphs and image captions at #EMNLP2020 (benchmark available here: cistern.cis.lmu.de/unsupervised-g…) but are there any other domain-specific parallel #graph-#text datasets out there I don't know about? Maybe from the #biomedical domain?

At #ACL2020, only 2 North Africans received subsidies to attend the conference. @NorthAfricanNLP debuted at #EMNLP2020 and we're very happy to see 14 members received subsidies for #NAACL2021! The MENA region went from one of the least represented to the 3rd most represented 🙌


Compositional reasoning is not always unique -- there can be multiple ways of reaching the correct answer. With multiPRover, we extend our #EMNLP2020 work on PRover (which generates a single proof) by now tackling a more challenging task of generating a *set* of proof graphs. 2/n



#emnlp2020 paper: we give some theoretical insight into the syntactic success of RNN LMs: we prove they can implement bounded-size stacks in their states to generate some bounded hierarchical langs with optimal memory! paper arxiv.org/pdf/2010.07515… blog nlp.stanford.edu/~johnhew/rnns-…


"Learning Music Helps You Read", our #emnlp2020 paper with @jurafsky! We use transfer learning between language, music, code and parentheses. Some exciting results about encoding and transfer of abstract structure, and the role (or not!) of recursion arxiv.org/abs/2004.14601


What kind of scientific ideas are more likely to spread beyond academia? In our recent #emnlp2020 findings paper, we carried out a large-scale data analysis to understand the knowledge transfer of scientific concepts across text corpora from research to practice. #CompSocSci

من مشاركة فريق #بيان في ورشة عمل NLP for COVID-19 Workshop (Part 2) من مؤتمر #emnlp2020 ✨ #EMNLP2020

🚀Release!🚀 RoBERTa models pre-trained on millions of tweets. Also fine-tuned models for tweet classification for the #emnlp2020 Findings paper 🎉TweetEval🎉. Models and starter code now online in 🤗@huggingface | huggingface.co/cardiffnlp/twi… #NLProc





Our NLP team got 16 papers (11 long, 2 short, and 3 finds) at #emnlp2020, which cover dialogue, summarization, question answering, multilingual, few-shot, NLI, semantic parsing, data augmentation, etc. Congrats to team members and coauthors. More info about papers coming soon!


🤔How can a pre-trained left-to-right LM do nonmonotonic reasoning, that requires conditioning on a future constraint⏲️? Our #emnlp2020 paper introduces DELOREAN🚘: an unsupervised backpropagation-based decoding strategy that considers both past context and future constraints.



We are giving an #emnlp2020 tutorial on "Interpreting Predictions of NLP Models". Come join me, @nlpmattg, and @sameer_ LIVE Thursday (tomorrow) at 15:00-19:30 UTC time (7-11:30 Pacific). Slides here: github.com/Eric-Wallace/i… Video available afterward

My 2nd PhD paper! Can models generate non-trivial explanations of their behavior in natural lang w/o just *leaking* the label? We address this in our #emnlp2020 findings paper (w/ @byryuer harry @mohitban47), via a new Leakage-Adjusted Simulatability(LAS) metric for NL Explns 1/6





How do we build adaptive language interfaces that learn through interaction with real human users? New work w/ my amazing advisors @DorsaSadigh and @percyliang, to be presented at the @intexsempar2020 workshop at #emnlp2020. Link: arxiv.org/abs/2010.05190 A thread 🧵(1 / N).


Introducing Wikipedia2Vec, an efficient and easy-to-use toolkit to learn and visualize the embeddings of words and entities from Wikipedia. Paper: arxiv.org/abs/1812.06280 Site:wikipedia2vec.github.io/wikipedia2vec/ Demo: wikipedia2vec.github.io/demo/ #emnlp2020 (demo) led by @ikuyayamada [1/3]
![AkariAsai's tweet image. Introducing Wikipedia2Vec, an efficient and easy-to-use toolkit to learn and visualize the embeddings of words and entities from Wikipedia.
Paper: arxiv.org/abs/1812.06280
Site:wikipedia2vec.github.io/wikipedia2vec/
Demo: wikipedia2vec.github.io/demo/
#emnlp2020 (demo) led by @ikuyayamada [1/3]](https://pbs.twimg.com/media/Ej57AVGUwAARz7c.jpg)
My 'present' to @huggingface for being awarded as Best Demo Paper at #emnlp2020. mT5-small fine-tuned on tydiQA for multilingual QA. EM = 41.65 huggingface.co/mrm8488/mT5-sm…

Join us at the 1st Workshop on Computational Approaches to Discourse (CODI) at #emnlp2020! Here's the schedule featuring invited speakers @ehovy and @eunsolc (click here to see more timezones codi-workshop.github.io/schedule/)


Should our probes be simple or accurate? @nsaphra and I reframe this trade off with Pareto fronts in our new #emnlp2020 paper with @adinamwilliams and @ryandcotterell arxiv.org/abs/2010.02180 Follow the thread :)

At the #nlpcss workshop at EMNLP, @dongng gave a wonderful overview of recent work in computational sociolinguistics. Some points: how do we "evaluate" our methods for detecting variation without ground truth data? How can we highlight speaker agency in variation? #emnlp2020

Can we improve chatbots after deployment from natural user feedback? A big YES :) User feedback has rich cues about errors but it cannot be used directly for training. So we use GANs to generate training data from feedback. arxiv.org/abs/2010.07261 #Findings-of-#EMNLP2020 #NLProc.



Excited to share our #EMNLP2020 work: REALSum: Re-evaluating Evaluation in Text Summ: arxiv.org/pdf/2010.07100… (super awesome coauthors: @manikb20 @Pranav @ashatabak786 and @gneubig ) Are existing automated metrics reliable??? All relevant resource has been released (1/n)!
Something went wrong.
Something went wrong.
United States Trends
- 1. #FinallyOverIt 5,565 posts
- 2. #TalusLabs N/A
- 3. Summer Walker 17.5K posts
- 4. 5sos 22K posts
- 5. #criticalrolespoilers 4,146 posts
- 6. Justin Fields 10K posts
- 7. #GOAI 3,075 posts
- 8. Wale 33.4K posts
- 9. #zzzSpecialProgram 2,880 posts
- 10. Jalen Johnson 8,989 posts
- 11. Go Girl 26.1K posts
- 12. Bihar 258K posts
- 13. Domain For Sale 12.9K posts
- 14. 1-800 Heartbreak 1,447 posts
- 15. Drake Maye 21.4K posts
- 16. Judge 206K posts
- 17. Robbed You 4,136 posts
- 18. Disc 2 1,019 posts
- 19. GM CT 20.9K posts
- 20. Give Me A Reason 1,709 posts