#encodingvstranscoding 검색 결과

I gave a lecture at @Stanford CS 25. Lecture video: youtu.be/orDKvo8h71o?si… AI is moving so fast that it's hard to keep up. Instead of spending all our energy catching up with the latest development, we should study the change itself. First step is to identify and understand…

Think all embeddings work the same way? Think again. Here are 𝘀𝗶𝘅 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝘁 𝘁𝘆𝗽𝗲𝘀 of embeddings you can use, each with their own strengths and trade-offs: 𝗦𝗽𝗮𝗿𝘀𝗲 𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝘀 Think keyword-based representations where most values are zero. Great…




Reminder: You can get high-quality Audio representations through Encodec! 🌟 EnCodec is trained specifically to compress any kind of audio and reconstruct the original signal with high fidelity! The 24 kHz model can compress to 1.5, 3, 6, 12 or 24 kbps, while the 48 kHz model…
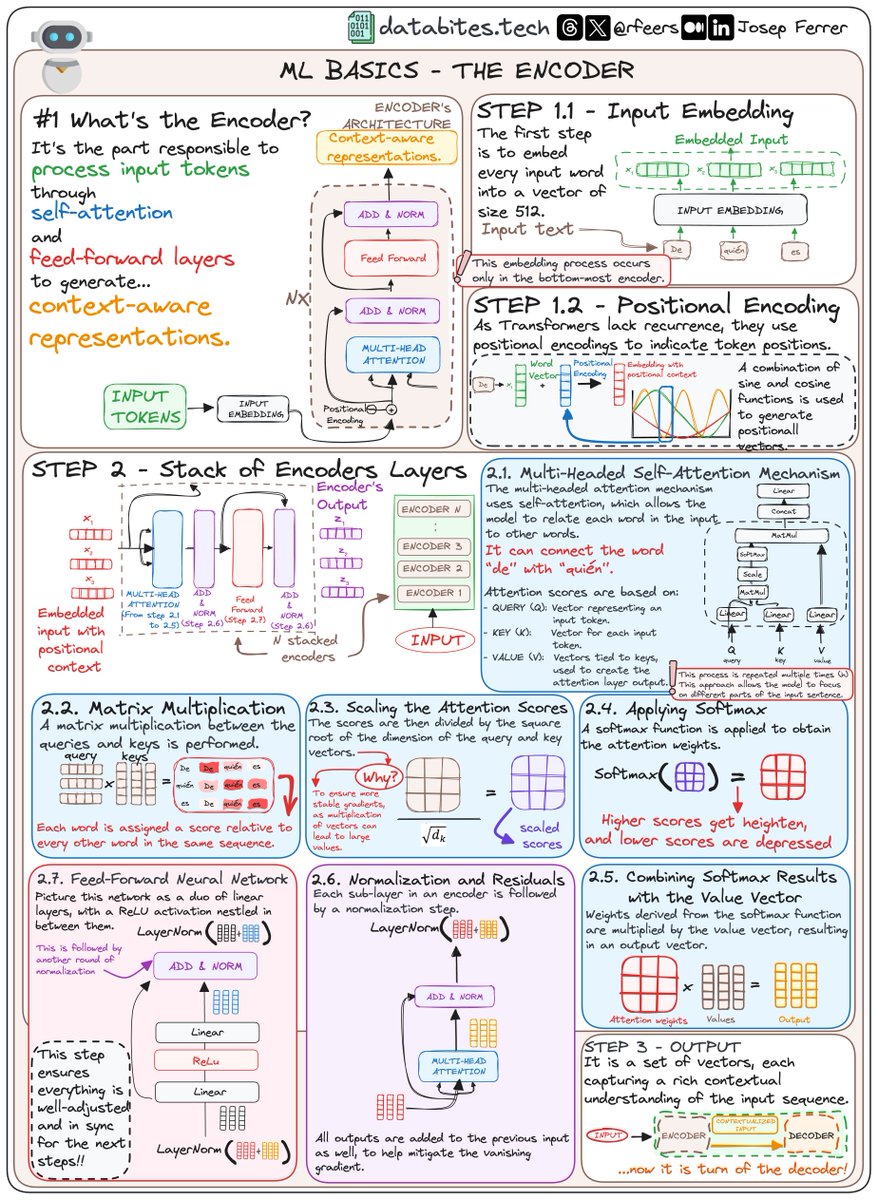

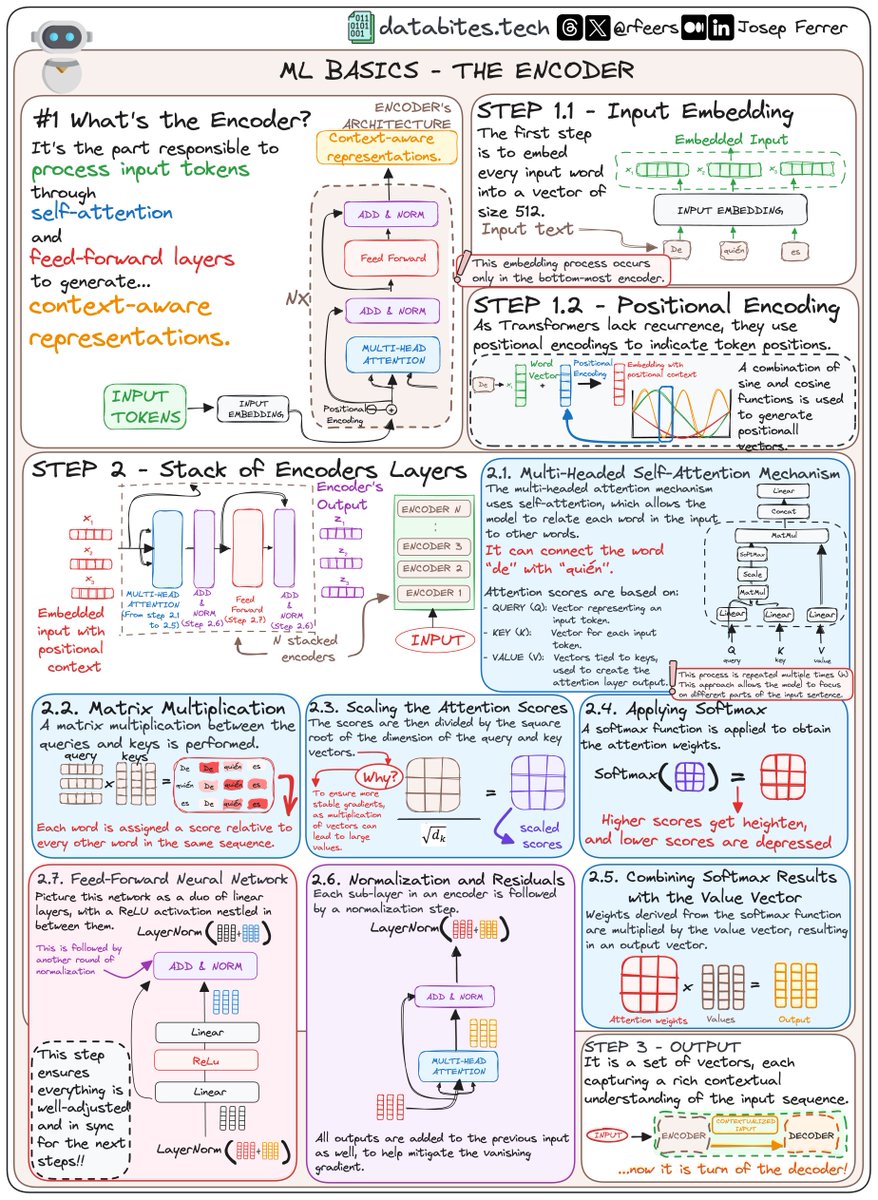
Embeddings & Positional Encoding in LLMs. Embeddings → Definition Convert discrete tokens (words, subwords, characters) into dense vectors in continuous space. → Process Text → Tokenization → Embedding Matrix Lookup → Vector Representation → Purpose ✓ Captures…


🚨Stop using positional encoding (PE) in Transformer decoders (e.g. GPTs). Our work shows 𝗡𝗼𝗣𝗘 (no positional encoding) outperforms all variants like absolute, relative, ALiBi, Rotary. A decoder can learn PE in its representation (see proof). Time for 𝗡𝗼𝗣𝗘 𝗟𝗟𝗠𝘀🧵[1/n]
![a_kazemnejad's tweet image. 🚨Stop using positional encoding (PE) in Transformer decoders (e.g. GPTs). Our work shows 𝗡𝗼𝗣𝗘 (no positional encoding) outperforms all variants like absolute, relative, ALiBi, Rotary. A decoder can learn PE in its representation (see proof). Time for 𝗡𝗼𝗣𝗘 𝗟𝗟𝗠𝘀🧵[1/n]](https://pbs.twimg.com/media/FxiwndLaAAIa4_5.jpg)
![a_kazemnejad's tweet image. 🚨Stop using positional encoding (PE) in Transformer decoders (e.g. GPTs). Our work shows 𝗡𝗼𝗣𝗘 (no positional encoding) outperforms all variants like absolute, relative, ALiBi, Rotary. A decoder can learn PE in its representation (see proof). Time for 𝗡𝗼𝗣𝗘 𝗟𝗟𝗠𝘀🧵[1/n]](https://pbs.twimg.com/media/FxiwwRtaQAkKi_8.png)


Since AV1 is the topic of discussion again, let me share screenshots from my encoder project earlier in the year. First is NVENC, second is AV1. Both at the same bitrate. The difference is revolutionary. Even through Twitter





Perception Encoder: The best visual embeddings are not at the output of the network "we find that contrastive vision-language training alone can produce strong, general embeddings for all of these downstream tasks. There is only one caveat: these embeddings are hidden within the…


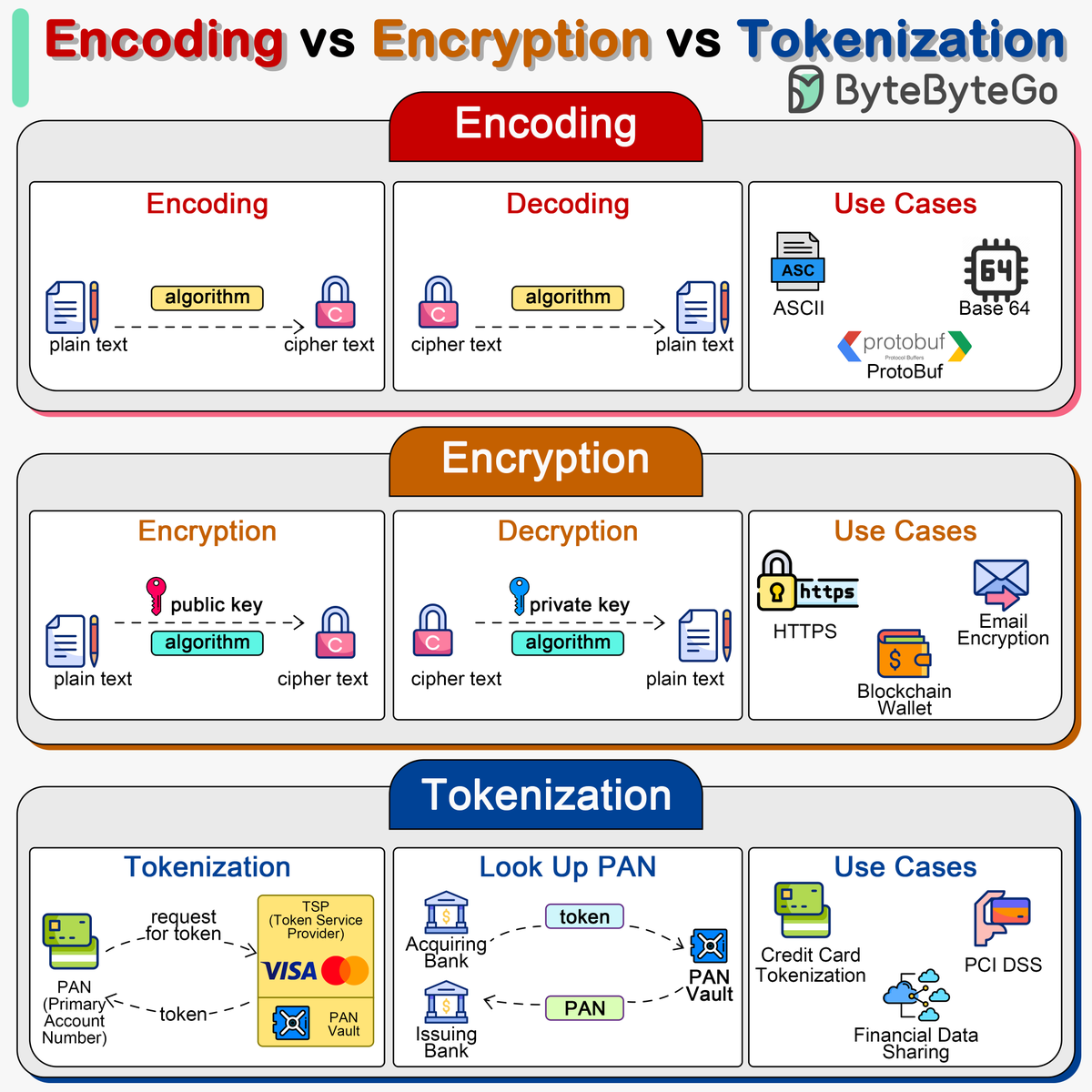
Encoding vs Encryption vs Tokenization. Encoding, encryption, and tokenization are three distinct processes that handle data in different ways for various purposes, including data transmission, security, and compliance. In system designs, we need to select the right approach…

The Hidden Harmony in AI's Complexity: How Different Algorithms Whisper the Same Truth An exciting discovery revealed in this paper is that very different machine learning algorithms and neural networks can encode surprisingly similar representations of data, even though their…

Sinusoidal positional encoding (SPE) is one of the most mysterious components of the Transformer architecture... Fortunately, there is an intuitive analogy: - in a binary encoding, lower bits alternate more frequently - in SPE, lower dimensions use a wave of higher frequency!


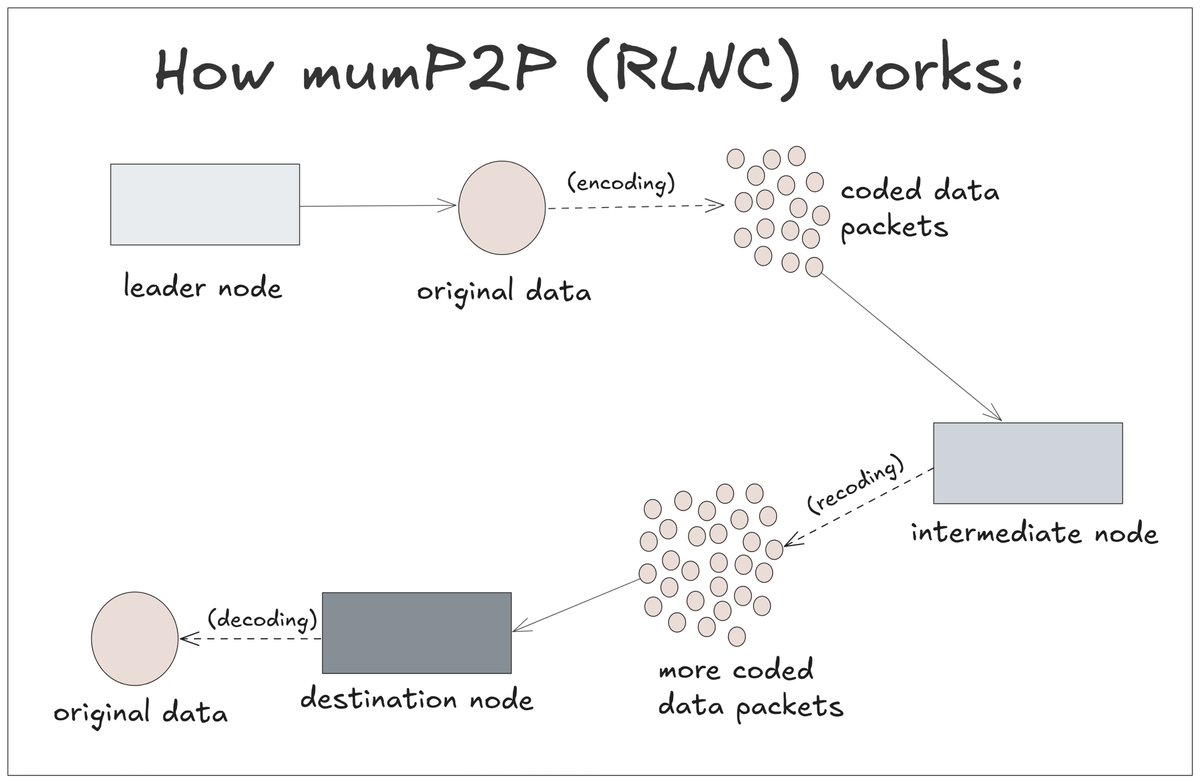
data propagation protocols differ in how data is delivered across the nodes btw, data propagation in blockchains is basically how data (txns, blocks) is sent across the network so every validator node gets a copy . . . during propagation, loss happens. some packets get lost…

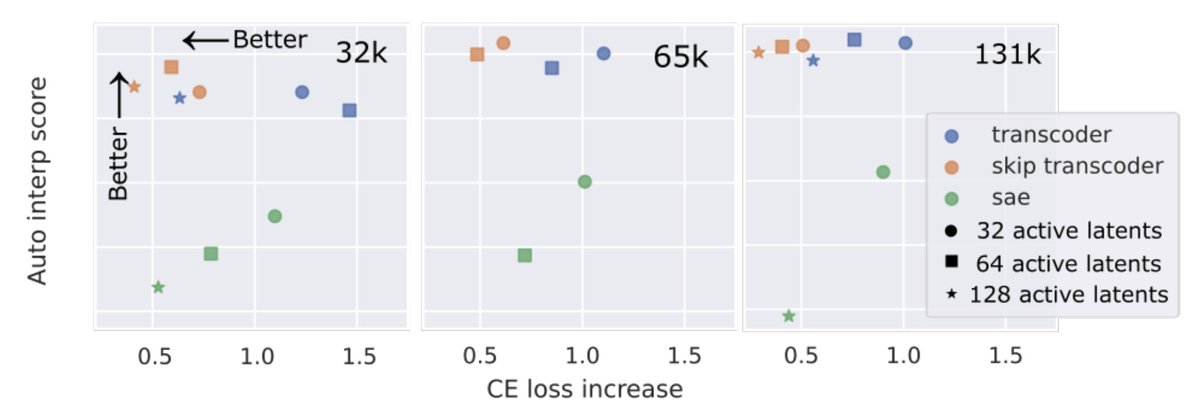
Sparse autoencoders (SAEs) have taken the interpretability world by storm over the past year or so. But can they be beaten? Yes! We introduce skip transcoders, and find they are a Pareto improvement over SAEs: better interpretability, and better fidelity to the model 🧵

🔥 If you ever seed your Vue components with JSON data in your Blade templates, you *definitely* want to enable double-encoding. Without it, a rogue """ in any user-submitted data might blow up your front end!

Something went wrong.
Something went wrong.
United States Trends
- 1. Ohtani 55.2K posts
- 2. #WWERaw 41.6K posts
- 3. #WorldSeries 62.4K posts
- 4. Chiefs 71.8K posts
- 5. Mahomes 22.5K posts
- 6. Mariota 7,346 posts
- 7. Treinen 2,699 posts
- 8. Terry 23.2K posts
- 9. Kelce 14.7K posts
- 10. #Dodgers 11.2K posts
- 11. Rashee Rice 3,459 posts
- 12. #RaiseHail 6,941 posts
- 13. Maxey 8,853 posts
- 14. Mookie 7,610 posts
- 15. Vladdy 4,954 posts
- 16. Bulls 25.4K posts
- 17. Glasnow 5,384 posts
- 18. Freddie 11.1K posts
- 19. Deebo 5,482 posts
- 20. Dave Roberts 2,985 posts