#expediawebdatascraping search results

I’ve spent years building data scrapers. IPs get blocked. Selectors break. JS-heavy sites? Pure pain. Then I tried Oxylabs AI Studio You just describe what you want in plain English, and the AI handles the scraping, crawling, browser actions, JS rendering, proxy rotation……

we filter out private information locally, never leaves your computer, but you can manually delete your dms file here's a description of the data we use github.com/TheExGenesis/c…


Web Data Scraping using Excel VBA ⏱️ 1.9 hours ⭐ 4.42 👥 3,206 🔄 Aug 2020 💰 FREE comidoc.com/udemy/webscrap… #VBA #WebScraping #Excel #udemy


Comment From one of the other ME's That database is nothing more than continued scraping under the auspices of credit and copyright protection. Thank goodness I don't have an account there any longer so they can scrape my a-s.🤣 youtube.com/watch?v=gG0fj4…

youtube.com
YouTube
Why Everyone Is LEAVING Spotify

suarios reportan estafa a nombre de #Expedia. La investigación revela un esquema de robo de datos y compra de publicidad o dominios para aparecer a la cabeza de las búsquedas: @Vally_Duran. youtube.com/watch?v=RUiQ_G…

youtube.com
YouTube
Usuarios reportan estafa y robo de datos a nombre de Expedia: MCCI

The video showcases "Ultimate Web Scraper" (aka PandaExtract), a Chrome extension with AI for accurate data extraction like lists, emails, and leads. It doesn't use user prompts—it's point-and-click. It scrapes structured data from sites (e.g., products, prices) into CSV/Excel…

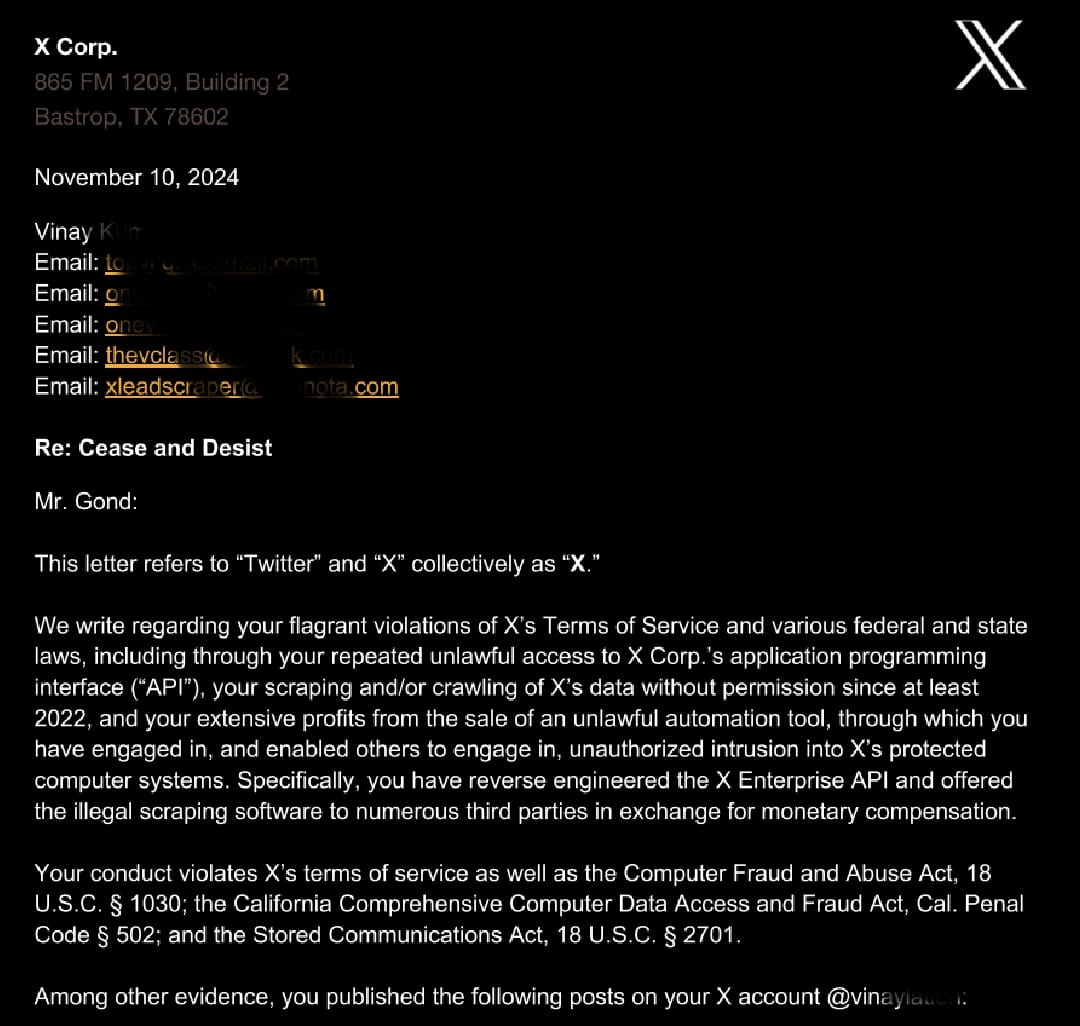
3/ 2023: Built X Lead Scraper Problem: Companies paying ₹35L/month for Twitter data Solution: Built scraper using proxy rotation + behavioral mimicry Result: ₹4cr ARR in 6 months Technical breakdown: xleadscraper.qzz.io/founder

@Expedia your website is a mess and your customer service people are so untrained and difficult to understand. I have been using your website for more than 10 years and I want to leave it permanently, so disappointed
Usuarios reportan estafa a nombre de #Expedia. La investigación revela un esquema de robo de datos y compra de publicidad o dominios para aparecer a la cabeza de las búsquedas: @Vally_Duran. youtube.com/watch?v=RUiQ_G…
youtube.com
YouTube
Usuarios reportan estafa y robo de datos a nombre de Expedia: MCCI

The Essential Tools for Effective Web Scraping #webscraping #proxy #api #dataextraction #brightdata plainenglish.io/community/the-…
plainenglish.io
The Essential Tools for Effective Web Scraping
Discover the key to successful web scraping in this guide. Learn advanced techniques and strategies to effectively gather and utilize data from the web, enhancing your data analysis and business...

Stealing high quality items from stores with minimal security, and especially street merchants. That way I don’t have to pay for anything out of pocket

The 2-click scraping is insane. Select what you want → Click extract → Done. It automatically detects patterns and grabs exactly what you need. No XPath gymnastics. No regex nightmares. Just pure, instant data extraction.
Usuarios reportan estafa a nombre de #Expedia. La investigación revela un esquema de robo de datos y compra de publicidad o dominios para aparecer a la cabeza de las búsquedas:@Vally_Duran. youtube.com/watch?v=RUiQ_G…
youtube.com
YouTube
Usuarios reportan estafa y robo de datos a nombre de Expedia: MCCI

Web scraping isn’t hard when we’re by your side. Just one API call turns any URL into clean, structured data. No more patching proxies. No more battling bots. Unlock effortless scraping, get started today 💡eu1.hubs.ly/H0pP6dV0


Las he hecho por ahí durante años, fácil desde el 2010. Desde muchísimo antes que existiera la versión traducida para México. ✌️ en.wikipedia.org/wiki/Expedia
I made $500,000 in 6 months with a tool that scraped 2 MILLION X profiles per day. Then I got a 13-PAGE CEASE-AND-DESIST letter. I was banned. My business was terminated. And I learned the architecture of every bad scraper on the market is fundamentally wrong. This is the…



Excellent article on running YaCy #DecentralizedSearch #WebScraping in a professional, secure, and scalable way for web scraping and data extraction: scrapingant.com/blog/decentral… It covers everything needed for serious deployments.

Something went wrong.
Something went wrong.
United States Trends
- 1. Ferran 30.4K posts
- 2. Chelsea 358K posts
- 3. Barca 132K posts
- 4. Sonny Gray 8,083 posts
- 5. Godzilla 22K posts
- 6. Rush Hour 4 13.3K posts
- 7. Barcelona 267K posts
- 8. Happy Thanksgiving 22.7K posts
- 9. Enzo 38.4K posts
- 10. Raising Arizona 1,159 posts
- 11. Chalobah 5,753 posts
- 12. National Treasure 6,084 posts
- 13. Red Sox 7,730 posts
- 14. Kounde 12.2K posts
- 15. Cucurella 21.6K posts
- 16. 50 Cent 5,613 posts
- 17. Dick Fitts 1,013 posts
- 18. Caicedo 14.8K posts
- 19. Neto 26.6K posts
- 20. Gone in 60 2,249 posts