#tdengine hasil pencarian

I recently participated in a Time Series DB Performance Challenge. After running the tests and script, I found that @TDengineDB outperformed TimescaleDB and InfluxDB. #TDengine #KubeCon

High-cardinality time-series data got you stuck? TDengine’s innovative Super Table model solves this pain point, outperforming traditional databases by 10x+ in write and query speed. Simplify your stack today ✨ #TDengine #Database
Join a growing community of innovators who use #TDengine to power their real-time analytics, driving efficiency and unlocking new insights from their time-series data. #Database

Beijing Taosi Data Technology Co., Ltd. and Tianyi Cloud Technology Co., Ltd. have recently completed product compatibility adaptation mutual certification. This test was conducted through adaptation certification between TDengine. #TDengine #timeseries database
CNPC replaced 40+ Oracle databases with just 9 TDengine instances. Streamlined time-series processing, lower costs, and scalable workloads—this is how enterprises modernize their data infrastructure 🏭 #TDengine #Database
Just read the TSBS benchmark report comparing TimeScaleDB, InfluxDB and TDengine. TDengine’s performance is off the charts! 🤯 #TDengine #timeseries database
SQL lovers, rejoice! TDengine now supports more MySQL functions (std, ifnull, group_concat + more) for seamless migration. No more learning new query languages—just powerful time-series Database capabilities 📊 #TDengine #Database
The new version 3050's Taosbenchmark is also quite new.Before 3020, it was basically the initial version. It is completely different from the current version in all aspects. #TDengine #timeseries database


AI Agent auto-pushes insights 📩 TDengine lets data speak for itself, no active query needed! #TDengine #Database
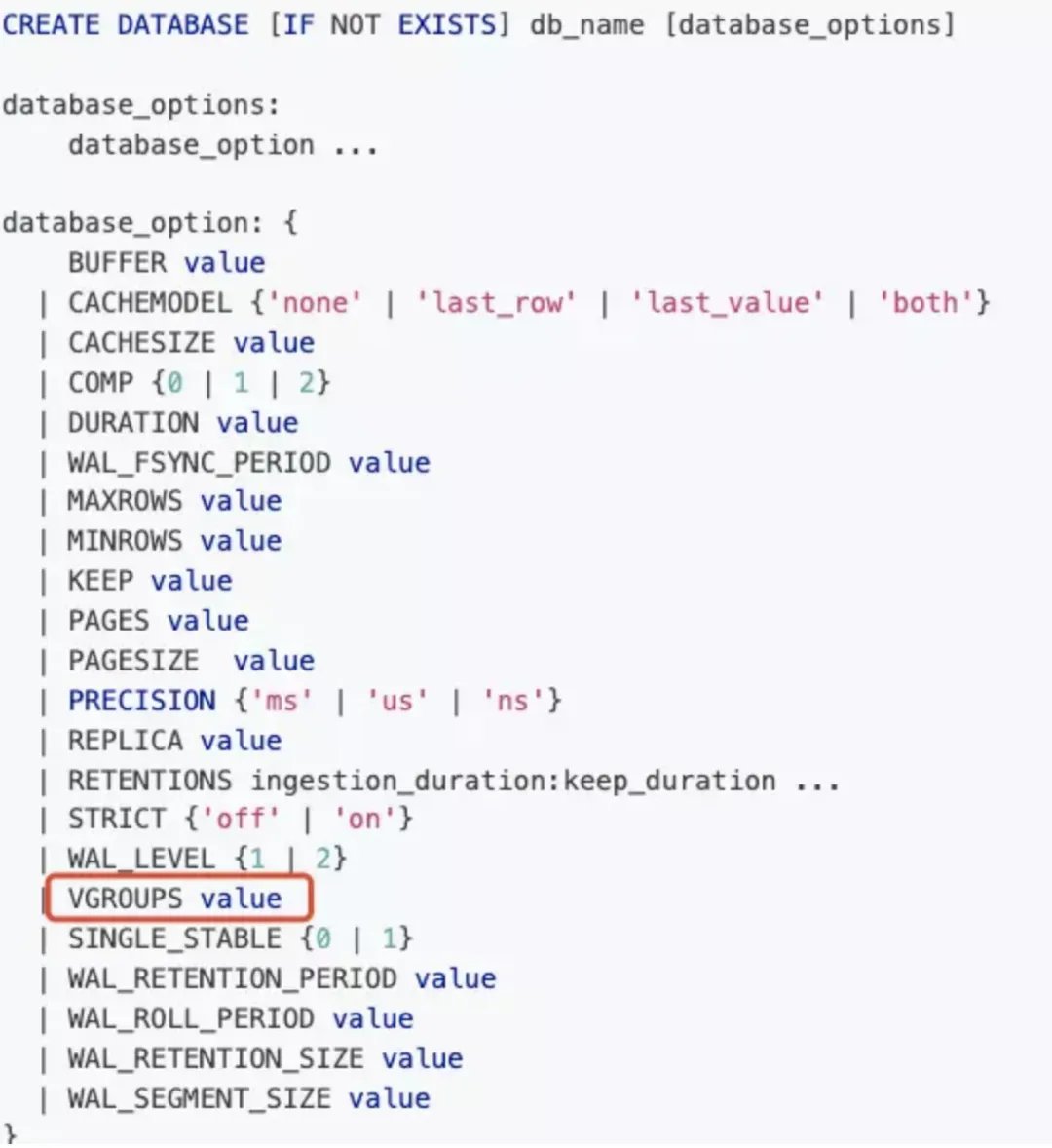
In TDengine 3.0, in order to support flexible resource allocation in cloud native scenarios, both temporal data and metadata require distributed technology. To this end, we remove the ordinary table metadata that exists in mnode #TDengine #timeseries database
For TDengine, every change request to the database (such as insert into test.d1 values (now, 1,2,3)) corresponds to a RAFT log record . During the process of continuously writing data, TDengine generates identical log records on each member . #TDengine #timeseries database
includes a built-in database named PERFORMANCE_SCHEMA to provide access to database performance statistics. This document introduces the tables of PERFORMANCE_SCHEMA and their structure. #TDengine #timeseries database

Loving the Data Explorer feature of TDengine! It allows me to effortlessly view and query my data. No more struggling with complex commands. #TDengine #DataExplorer

Vendor lock-in is a silent killer for industrial data strategy. Moving from proprietary APIs to standard SQL is not just a syntax change—it's a liberation. #database #TDengine
Get started with #TDengine in minutes! Its full SQL support and ease of use lower the learning curve, helping you build your time-series application faster. #Database
For most query types, TDengine performs better than InfluxDB and TimescaleDB. TDengine exhibits significant advantages in complex mixed queries, with avg load and breakdown request having query performance 426 and 53 times higher than InfluxDB #TDengine #timeseries database

#TDengine is a cutting-edge TSBS purpose-built for IoT. Designed as a distributed database from day one, it can support billions of IoT devices effortlessly while consistently outperforming other time-series databases in data ingestion, querying, and data compression.
Industrial data grows too fast for traditional databases—costs spiral. TDengine’s compression saved us 70% on hardware. With IDMP for data governance, the cost-performance ratio is unbeatable. #database #TDengine
TDengine 3.0.4.0 has released an important feature: support for custom functions (UDFs) written in the Python language. This feature greatly saves the time and cost of UDF development. It is obviously incomplete not to support Python UDF. #TDengine #timeseries database

Real-time data is fun until the volume explodes 😂 That’s when having a Time Series Database like TDengine becomes less of a “nice to have” and more of a necessity. #TDengine #TimeSeriesDatabase
TDengine offers professional solutions for the petrochemical industry ⛽ Real-time monitoring for equipment, pipelines and reactors to ensure production safety and efficiency! #TDengine #Database
When your data is basically “timestamp + value” over and over again, using a specialized Time Series Database feels like the obvious move 🤖 TDengine is one worth looking at. #TDengine #TimeSeriesDatabase
For the power IoT industry, TDengine solves big data pain points 🚦 It perfectly handles data storage, query and analysis in generation, transmission, distribution and consumption! #TDengine #Database
Been learning more about TDengine recently, and honestly, a dedicated Time Series Database just feels way more practical for IoT-style workloads ⚡ #TDengine #TimeSeriesDatabase #IoT

That’s why IDMP matters. It’s not just a time-series database with a nice UI—it’s built to carry industrial semantics natively. #database #TDengine
TDengine is a core infrastructure for smart manufacturing 🏭 It provides efficient and reliable data storage & analysis to boost enterprise digital and intelligent transformation! #TDengine #Database
Event is not just a tag. It’s a first-class analytical unit. When your time-series database understands that, root cause analysis and anomaly detection finally make sense. #database #TDengine
Next-gen industrial platforms aren’t just about faster queries. They’re about embedding the asset model into the #database core. #TDengine
AI in industry needs more than clean data. It needs operational semantics. Without the “why,” even the best model is blind. #database #TDengine
The core conflict? Modern UX vs. industrial context. We shouldn’t have to choose between a good interface and understanding the process. #database #TDengine
Not every database is happy dealing with massive streams of timestamped data 📈 That’s where a proper Time Series Database like TDengine starts to make sense. #TDengine #Database
AI in industrial can’t just eat raw time-series data. It needs structure (assets) and temporal segmentation (events). No context, no insight. This is the missing foundation. #database #TDengine
Industrial data isn’t just time-series points. It’s the context of a pump, a line, a failure. Generic tools strip that away. #database #TDengine
TDengine has top-tier global security compliance certifications 🛡️ ISO/IEC 27001, ISO/IEC 27017 and SOC 2® Type II, all checked for enterprise data security! #TDengine #Database
A lot of people don’t realize how different time-series workloads are until things start breaking 😅 That’s why tools like TDengine exist — built as a real Time Series Database from day one. #TDengine #TimeSeriesDatabase
If you're dealing with sensor data, logs, or telemetry all day, a good Time Series Database really makes life easier 😌 Been checking out TDengine lately. Pretty interesting. #TDengine #TimeSeriesDatabase
TDengine has complete domestic tech stack support in China 🇨🇳 It’s compatible with Loongson, Phytium, Kunpeng and other domestic CPUs as well as Kylin, Tongxin OS! #TDengine #Database
TDengine deeply supports industrial protocols such as MQTT and OPC 📡 It quickly converges data from various systems to realize unified cross-station and cross-system management! #TDengine #Database



#TDengine uses less processing power than InfluxDB or TimescaleDB to ingest the datasets. At its peak, InfluxDB’s CPU usage exceeds 90% during the ingestion process, while TDengine remains under 15%.

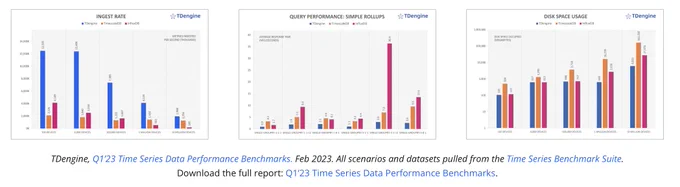
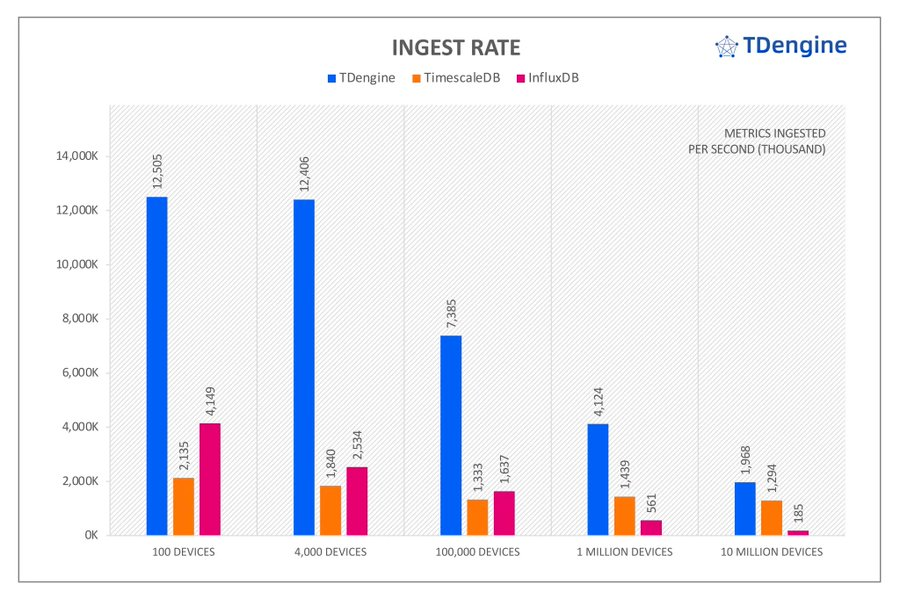
Time series databases need to ingest massive amounts of data, and #TDengine achieves the fastest ingestion speeds across all TSBS scenarios, ranging from 1.5 to 10.6 times the speed of the other products.
The new version 3050's Taosbenchmark is also quite new.Before 3020, it was basically the initial version. It is completely different from the current version in all aspects. #TDengine #timeseries database
I recently participated in a Time Series DB Performance Challenge. After running the tests and script, I found that @TDengineDB outperformed TimescaleDB and InfluxDB. #TDengine #KubeCon
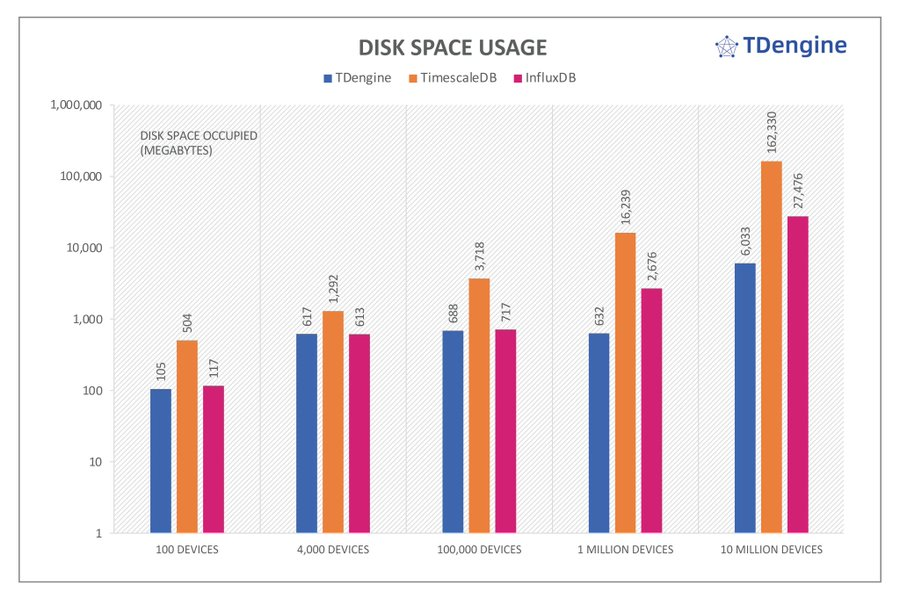
TSBS benchmark results show that TDengine has far superior performance than other time-series database products in both ingesting and querying big data—while using far fewer CPU and storage resources. #TDengine #Database #TimeSeries
TDengine 3.0.5.0 has finally been successfully released, which includes updates on system stability and performance optimization, streaming computing, data subscription, and some detailed optimizations that can improve user experience. #TDengine #timeseries database

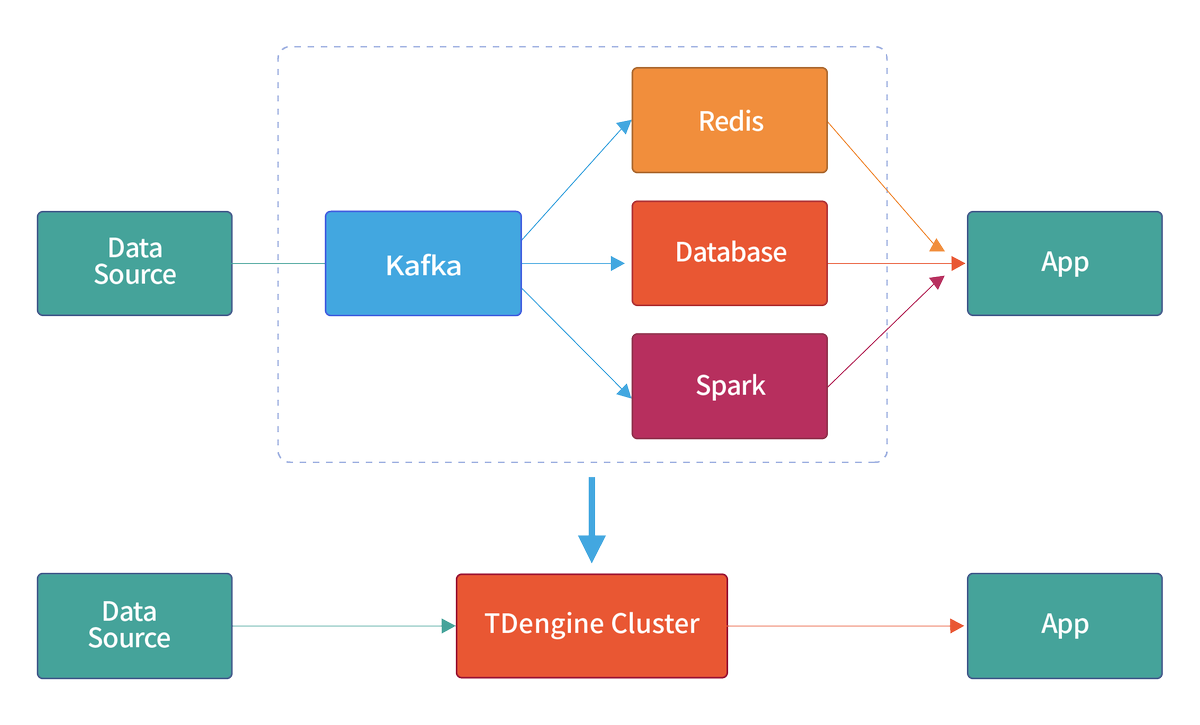
In addition to high-performance time-series databases with horizontal scalability, TDengine Cloud also provides: caching, data subscription and streaming computing functions.#TDengine #Database

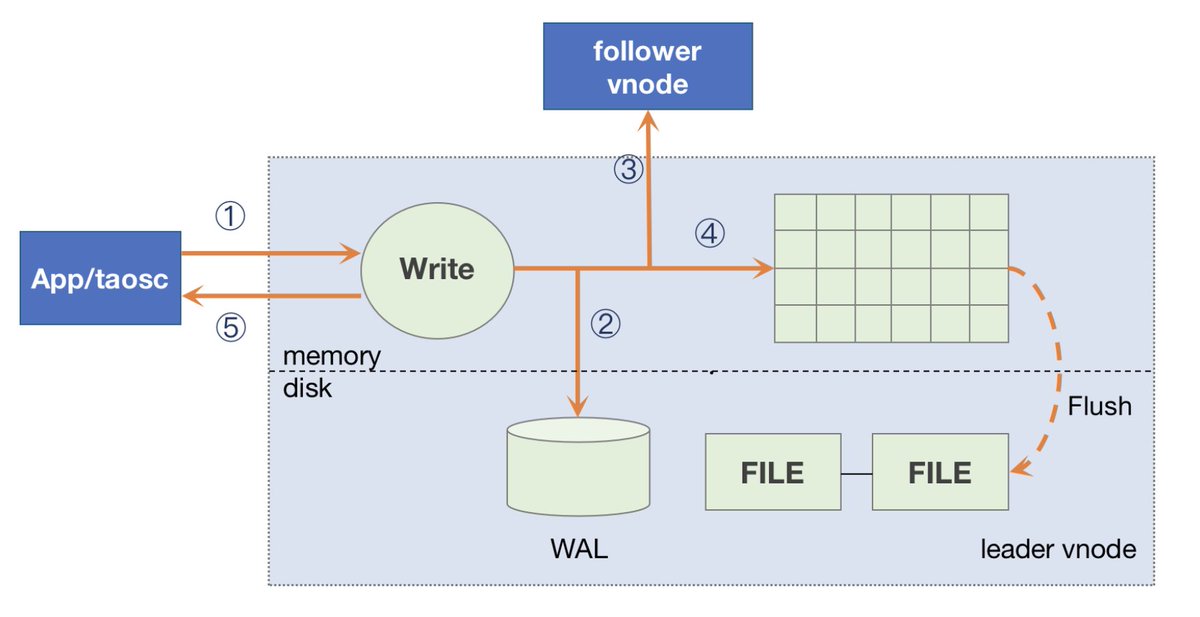
Writing process followed by Leader Vnode.When an application writes a new record to the system, only the leader vnode can accept the write request.#TDengine
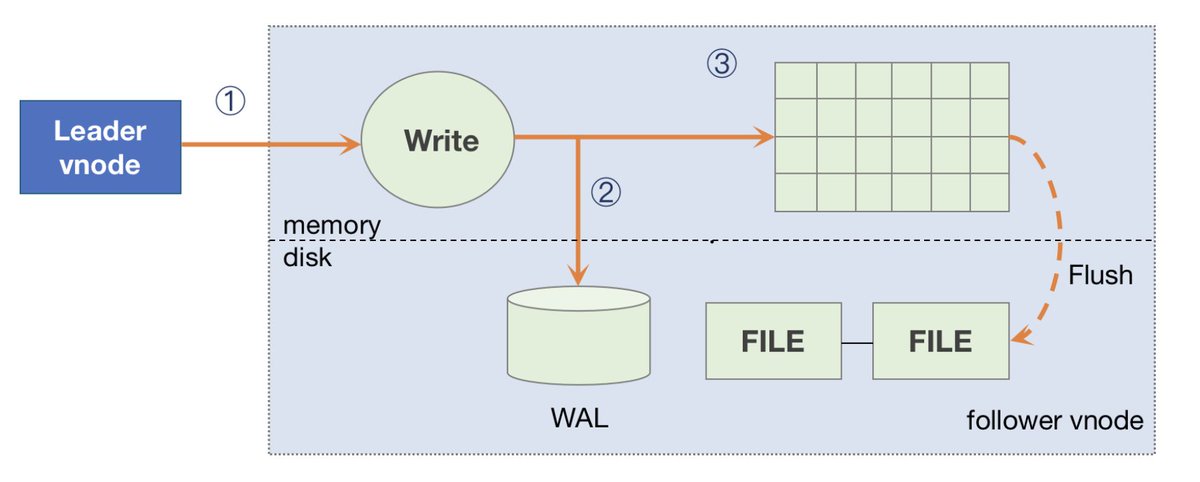
If the follower vnode receives a write request, the system will notify taosc that it needs to be redirected. For follower vnodes in TDengine, the writing process is as follows.#TDengine
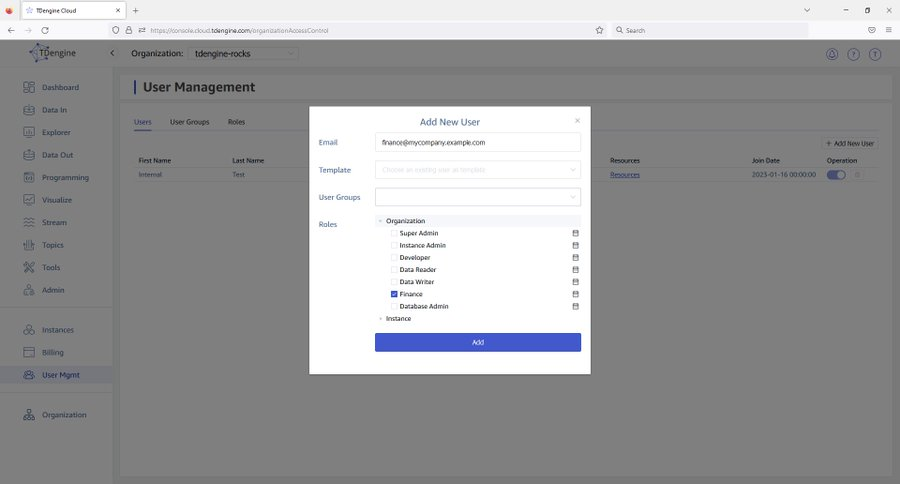
Invite collaborators and stakeholders to your organization with just an email address, even if they are not #TDengine Cloud users. Control their access to data with roles, user groups, and privilege templates in the full-featured TDengine Cloud user management system. #Database

Wishing you a merry and joyful Christmas filled with the warmth of family and the blessings of #TDengine's powerful time-series data management capabilities.


Participate in time series data base challenge. After running the script by @TDengineDB #TDengine #Kubecon2023
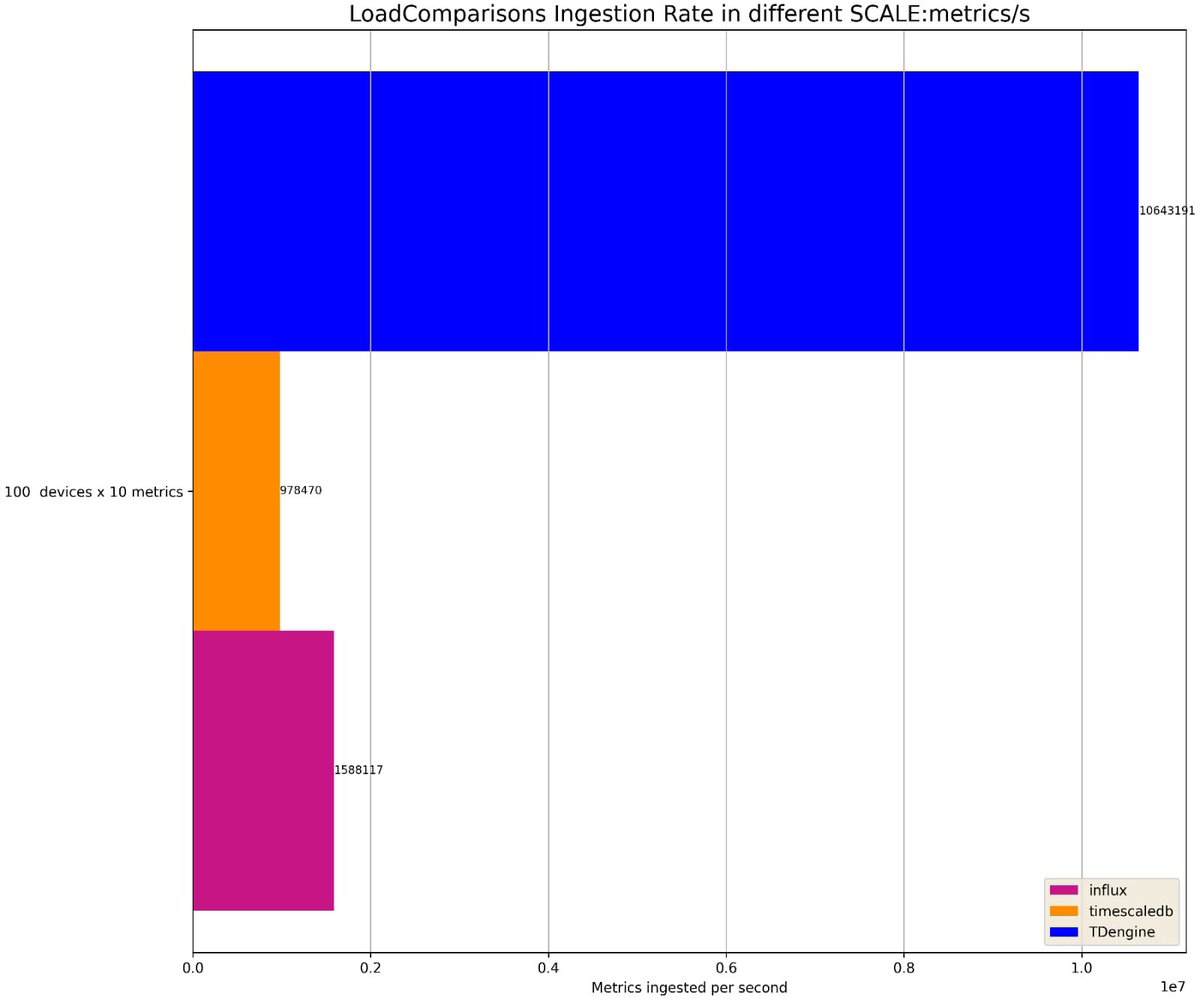
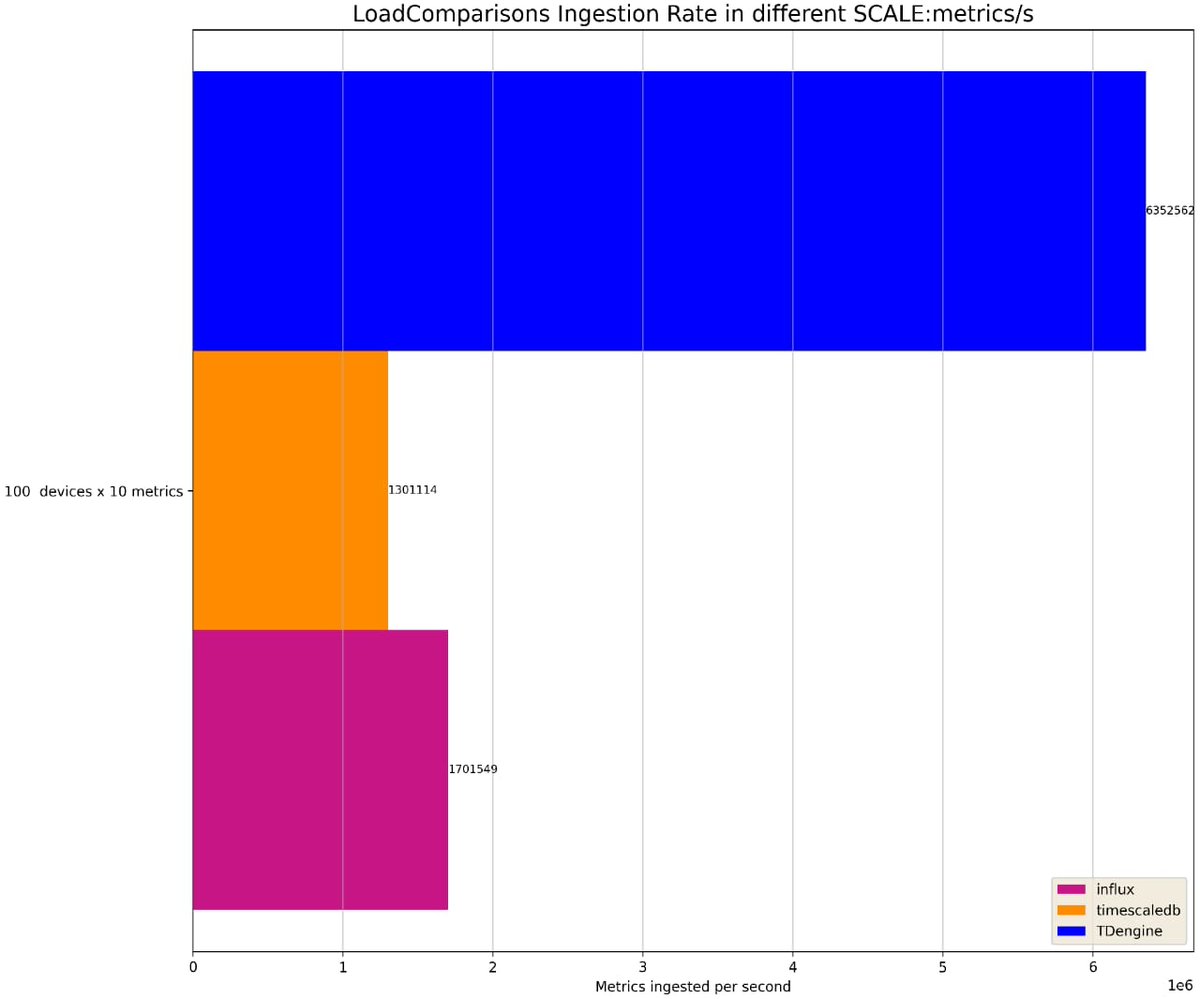
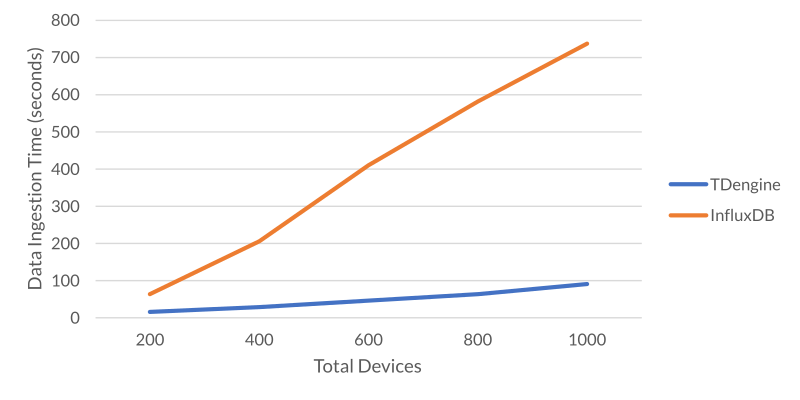
Figure 1 makes it clear that #TDengine outperforms InfluxDB in data ingestion as the number of devices increases. When the number of devices is 1000, InfluxDB takes 5.2 times longer to insert all the data.
In TDengine 3.0, in order to support flexible resource allocation in cloud native scenarios, both temporal data and metadata require distributed technology. To this end, we remove the ordinary table metadata that exists in mnode #TDengine #timeseries database

#TDengine outperforms InfluxDB and TimeScaleDB based on my TSBS benchmark testing. TDengine is really cool!
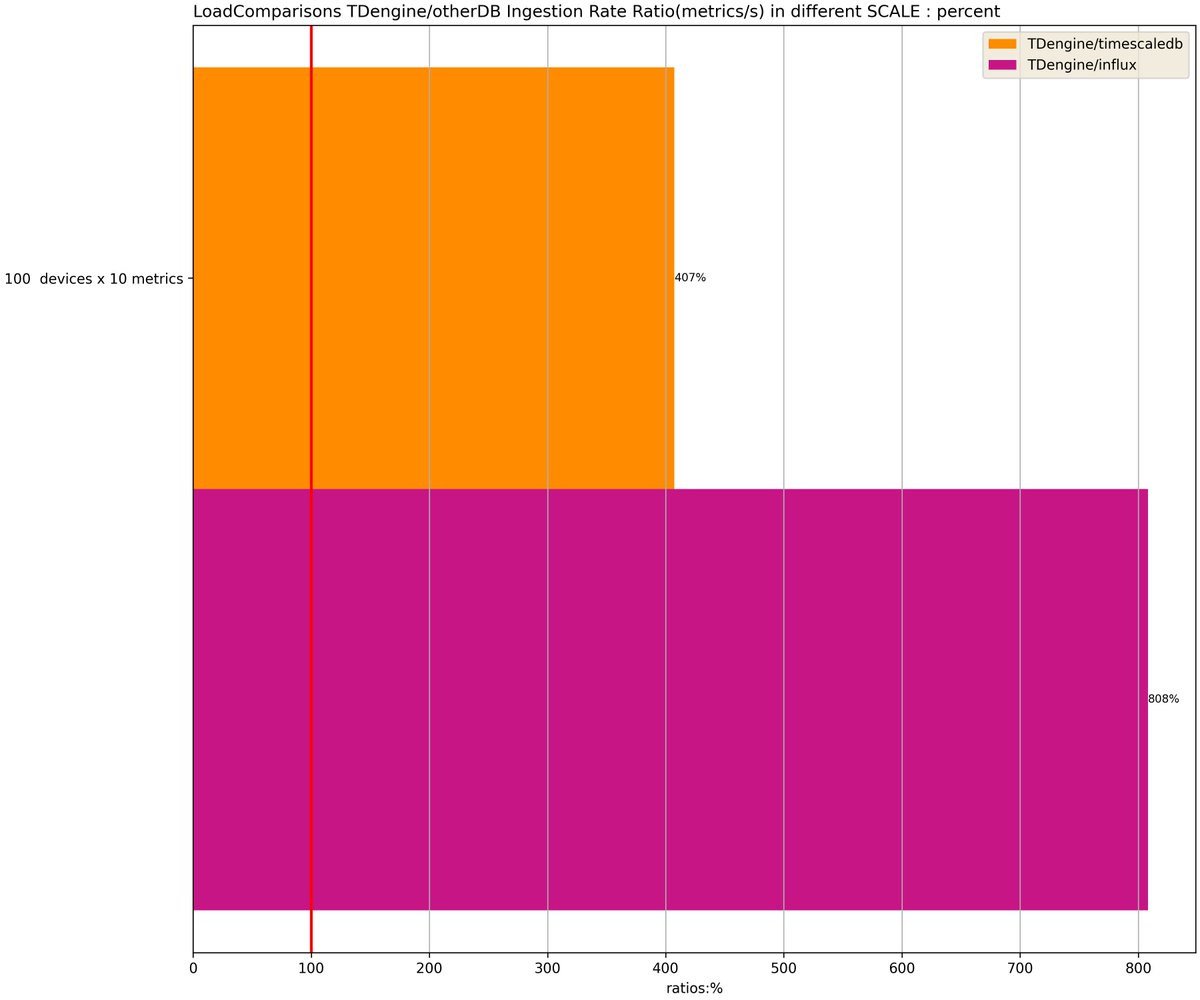
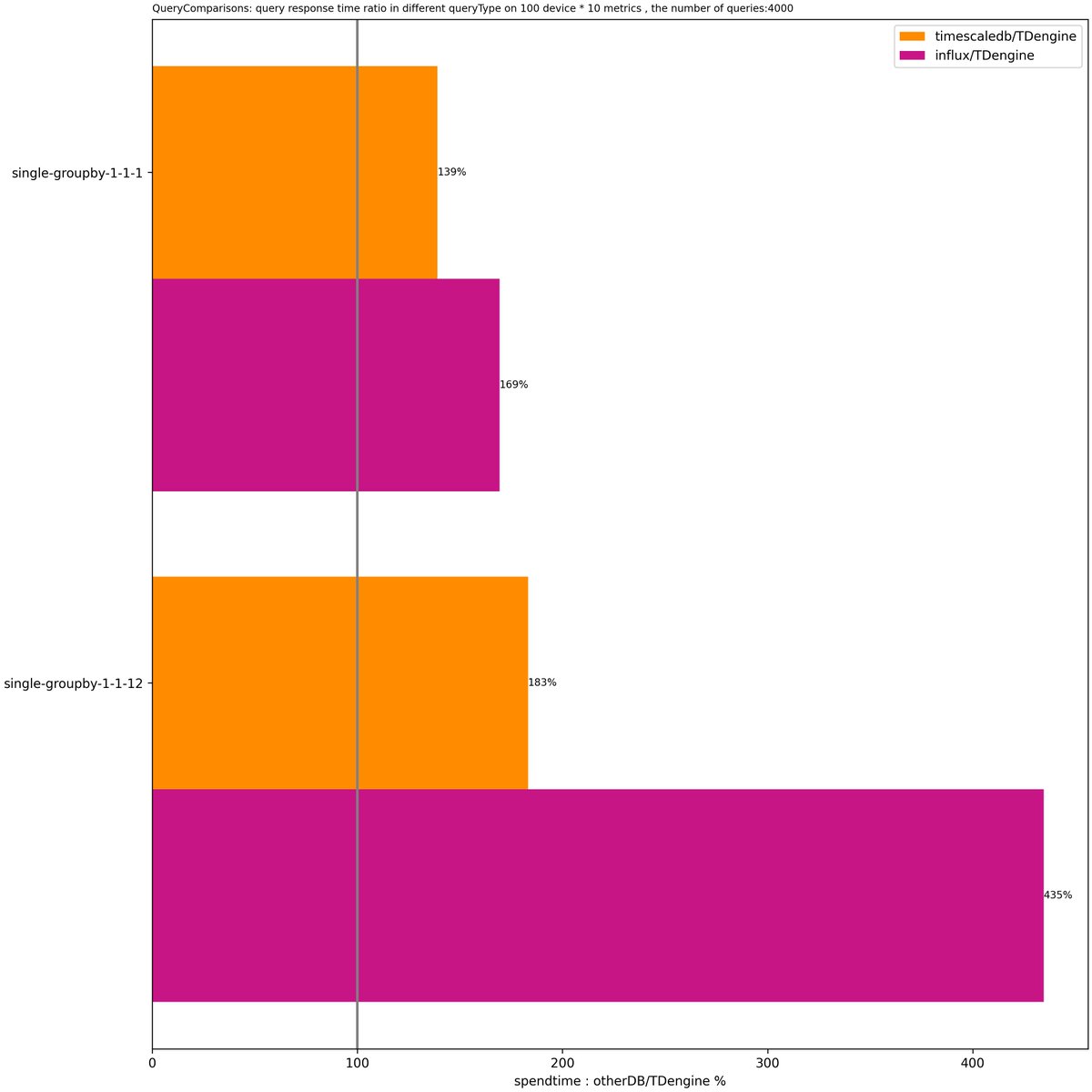

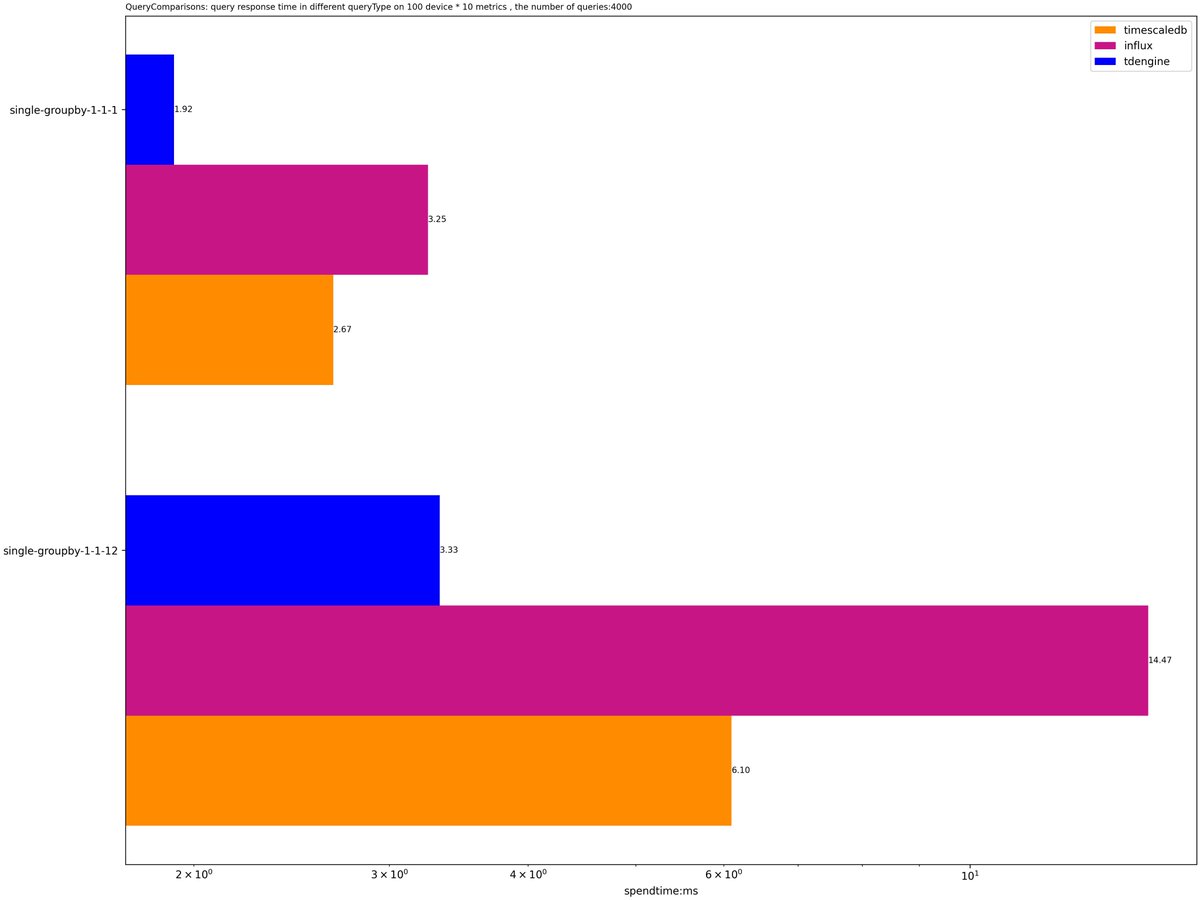
🧐What does a complete TDengine system look like? It runs on one or more physical nodes, logically, it includes dnode, taosc and app. There are one or more data nodes in the system, and these data nodes form a cluster. #TDengine #Database
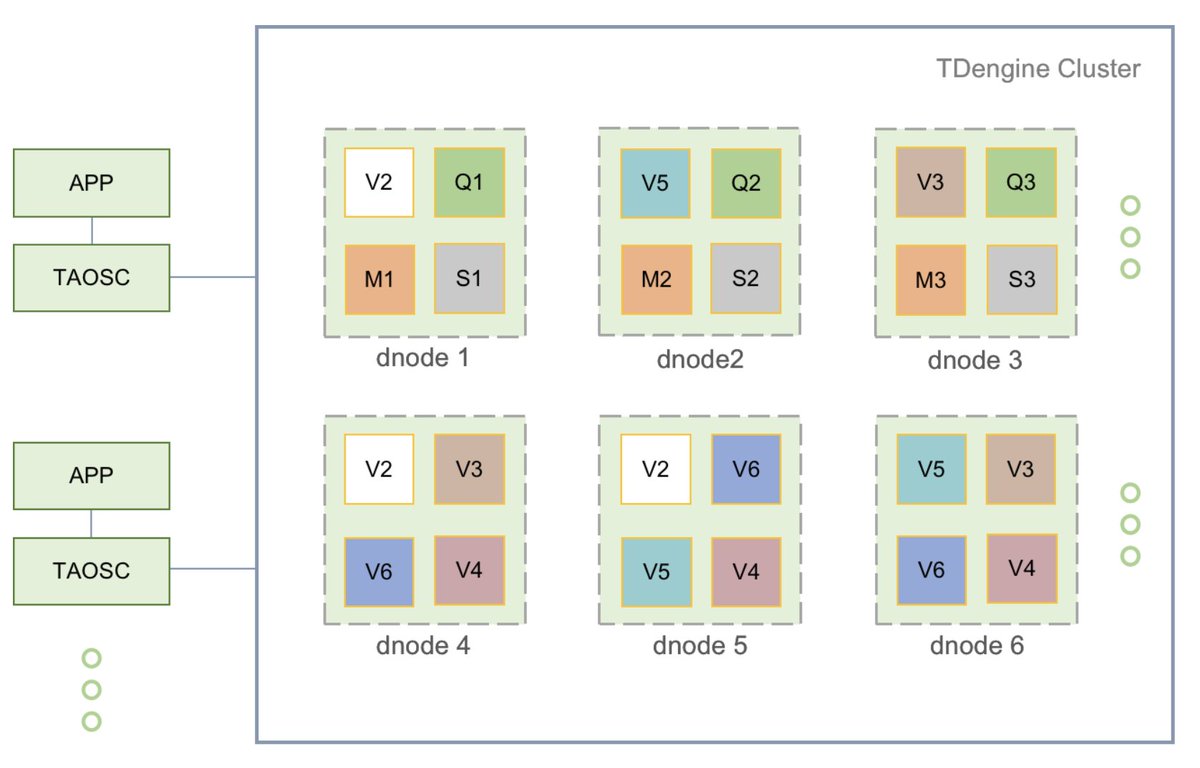
In addition, TSBS benchmark results show that #TDengine has far superior performance than other time-series database products in both ingesting and querying big data—while using far fewer CPU and storage resources.
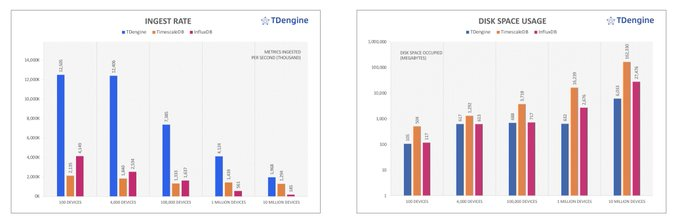
More complex queries allowed #TDengine to show off its processing power, reaching 24.3 times the performance of TimescaleDB and 34.3 times the performance of InfluxDB in the most challenging scenario: double-groupby-all.

In addition, the #TDengine project has received a total of 20.5k stars on GitHub, and the number of installed instances worldwide has exceeded 192.0k, with users in more than 50 countries and regions around the world.
#TDengine is a cutting-edge TSBS purpose-built for IoT. Designed as a distributed database from day one, it can support billions of IoT devices effortlessly while consistently outperforming other time-series databases in data ingestion, querying, and data compression.
Something went wrong.
Something went wrong.
United States Trends
- 1. #earthquake N/A
- 2. #bayarea N/A
- 3. Simon's Cat N/A
- 4. #xokitty N/A
- 5. Santa Cruz N/A
- 6. Stone Age N/A
- 7. #Survivor50 N/A
- 8. NASA N/A
- 9. Superform Foundation N/A
- 10. Maundy Thursday N/A
- 11. #BELIFT_WE_DEMAND_ACTION N/A
- 12. Holy Thursday N/A
- 13. Sharks N/A
- 14. Macklin Celebrini N/A
- 15. Colby N/A
- 16. Genevieve N/A
- 17. Invincible N/A
- 18. Nolan N/A
- 19. Mario Galaxy N/A
- 20. Conquest N/A