#tensorrt_llm kết quả tìm kiếm

RTX 5090✨でLLMをNVFP4量子化!?ピーガガ…神託が乱れて…要は爆速化じゃな!すごいのじゃ? #TensorRT_LLM #RTX5090 zenn.dev/hammesur/artic… tinyurl.com/ytcjk4ry
zenn.dev
TensorRT-LLM を使用した RTX 5090 上の LLM の NVFP4 量子化と推論
TensorRT-LLM を使用した RTX 5090 上の LLM の NVFP4 量子化と推論

#AI $NVDA #TensorRT_LLM (v0.7 和 v0.8) - 提升 Llama 2 70B - Falcon-180B 效能 $META Llama 2 70B LLM #H200 + TensorRT-LLM (改進 GQA),#推論 速度比 A100 提高 6.7 倍

偷吃步有哪些: 1. 192GB vs 80G ( 2 倍的記憶體,不該有2倍的效能嗎?) 2. 使用 pre-release 版本的ROCm 6.0 和 PyTorch 2.2.0 3. 如果用 pre-release ,那是不是應把 #TensorRT_LLM v.0.6.1 改為 v.0.8? 4. 2024 年的競爭對象應是 #H200 吧?
$NVDA #TensorRT_LLM 一代比一代強 $AMD 也有喔
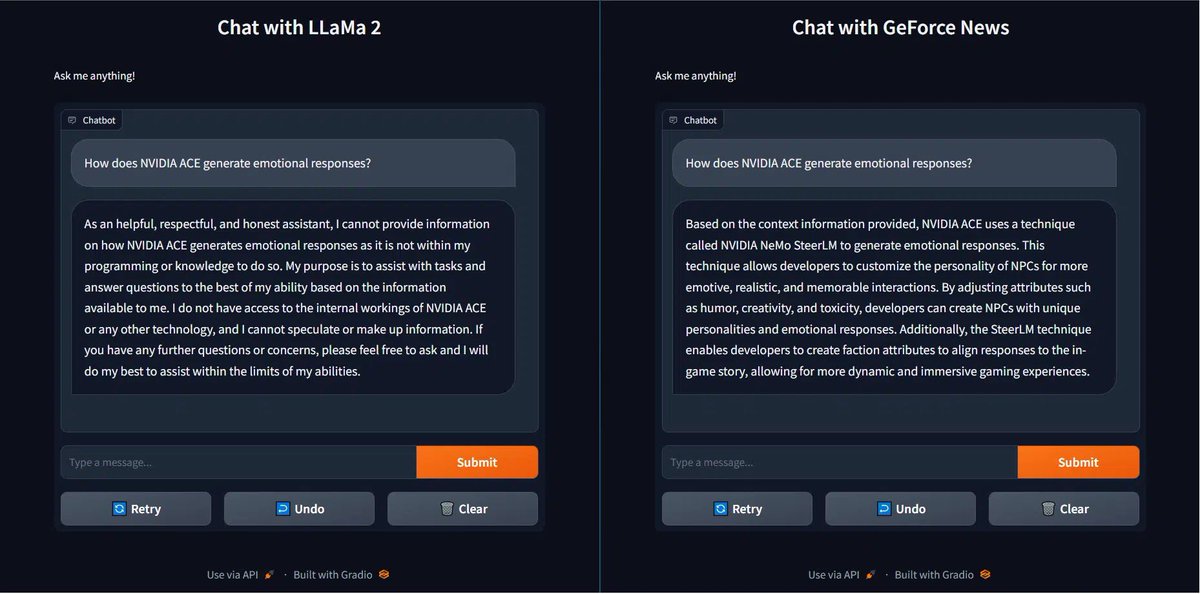
#AI #讓更多企業接觸AI #就會有更多需求跟應用 #就會有更多用戶 2023 年 9 月, $NVDA 先推出 #TensorRT-LLM 來強化資料中心專用的 #H100 的 #推論 能力後; 10 月宣布即將支援使用 GeForce RTX GPU (RTX 3060和RTX 4090) 的 Windows #PC,可讓 Llama 2 和 Code Llama 等最新 LLM 運行速度提高四倍
所以用 #TensorRT_LLM 推論軟體可以大勝 $AMD
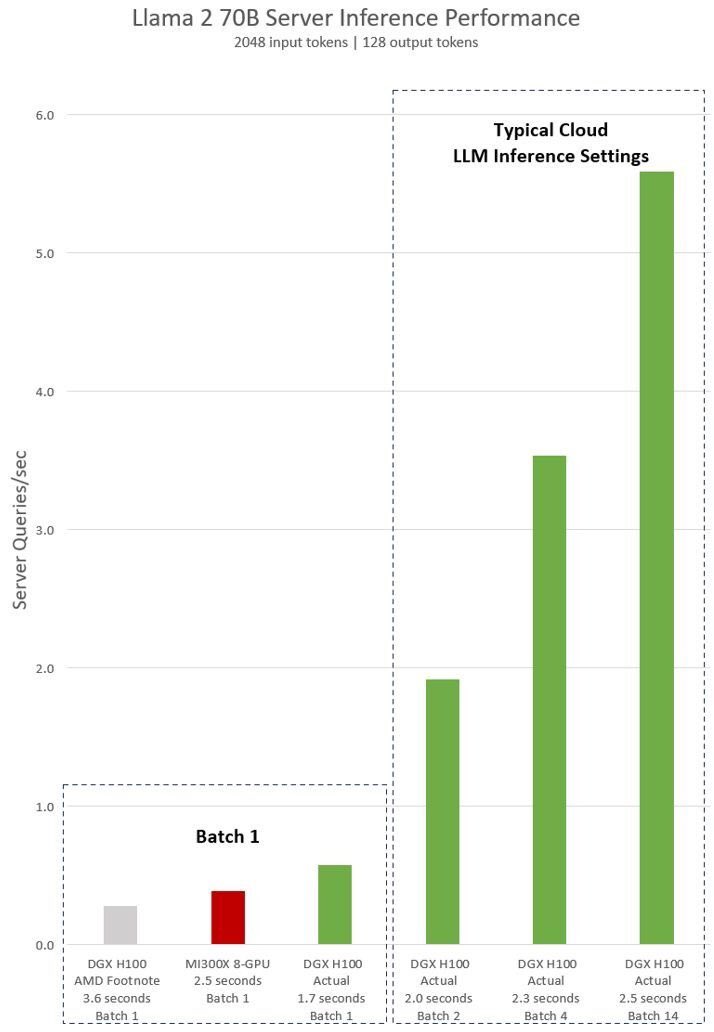
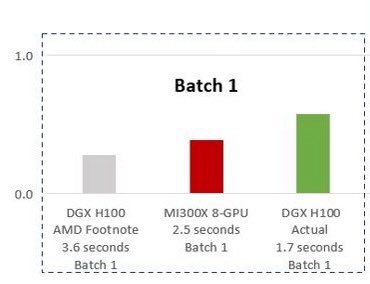
#AI $NVDA #TensorRT_LLM #教主77 $AMD 發表會 #沒用適當的最佳化軟體;否則 #H100會快二倍 - 使用 $AMD 推理軟體 vLLM v.02.2.2 處理 1 Batch ,#MI300X 僅需 2.5s,#H100 卻需 3.6s - 若搭 $NVDA 推理軟體 - #TensorRT_LLM v0.5.0 只需 1.7s (v0.8 已推出) #最右邊贏太多 #台灣人不為難台灣人

#TensorRT_LLM v0.8👇
#AI $NVDA #TensorRT_LLM (v0.7 和 v0.8) - 提升 Llama 2 70B - Falcon-180B 效能 $META Llama 2 70B LLM #H200 + TensorRT-LLM (改進 GQA),#推論 速度比 A100 提高 6.7 倍
#AI $NVDA #TensorRT_LLM (v0.7 和 v0.8) - 提升 Llama 2 70B - Falcon-180B 效能 $META Llama 2 70B LLM #H200 + TensorRT-LLM (改進 GQA),#推論 速度比 A100 提高 6.7 倍
Something went wrong.
Something went wrong.
United States Trends
- 1. Good Saturday 20.5K posts
- 2. Texas 158K posts
- 3. #FELIX_MAMAAwards2025 15.5K posts
- 4. #JimmySeaFanconD1 384K posts
- 5. #BINIFIED 181K posts
- 6. 3-8 Florida 2,285 posts
- 7. hanbin 23.7K posts
- 8. Sark 5,389 posts
- 9. #BuyNow 21.9K posts
- 10. #Domain 21.8K posts
- 11. Reaves 21.1K posts
- 12. Jeff Sims 1,722 posts
- 13. Katie Miller 3,080 posts
- 14. Aggies 9,532 posts
- 15. Georgia 49.9K posts
- 16. Arch 25.5K posts
- 17. Check Analyze 2,045 posts
- 18. Token Signal 7,274 posts
- 19. AI Alert 7,176 posts
- 20. Kentucky and Mississippi State N/A