

the ultimate guide to fine-tuning LLMs. this is a free 115-page book on arxiv and covers all the theory you need for fine-tuning: > NLP and LLMs fundamentals > peft, lora, qlora > mixture of experts (MoE) > seven stage fine-tuning pipeline > data prep, eval, best practices


ever wondered what an RLVR environment is? in 27 min I’ll show you: - what they made of - how RLVR differs from RLHF - the performance gain it gives to small models - and a walkthrough of the verifiers specs to define them. by the end you will be able to make your own 👺🦋


🕳️🐇Into the Rabbit Hull – Part I (Part II tomorrow) An interpretability deep dive into DINOv2, one of vision’s most important foundation models. And today is Part I, buckle up, we're exploring some of its most charming features.

MapAnything's evil sibling also supports flexible inputs but triples down on redundant outputs, estimating point maps, depths, and 3D Gaussians. x.com/chrisoffner3d/…


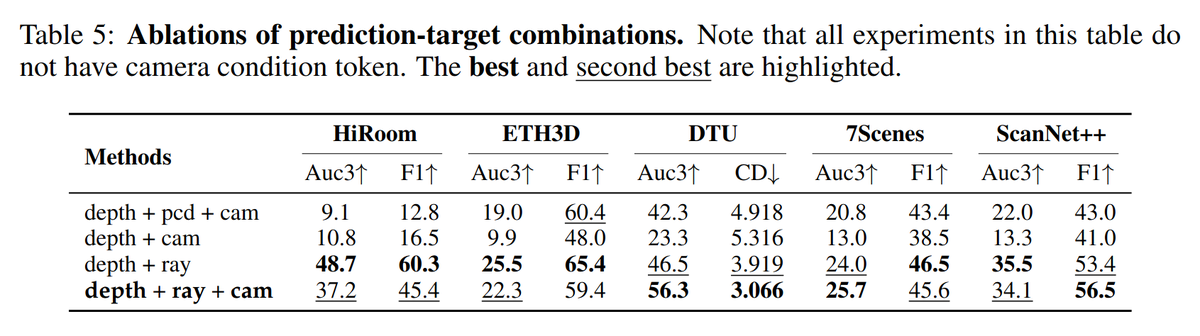
Is the terror reign of redundant scene representations ending? Where VGGT, CUT3R, and other recent models relied on godless redundant outputs (depth+points+pose) without guaranteeing internal prediction consistency, MapAnything and DepthAnything 3 are now heroically pushing back.


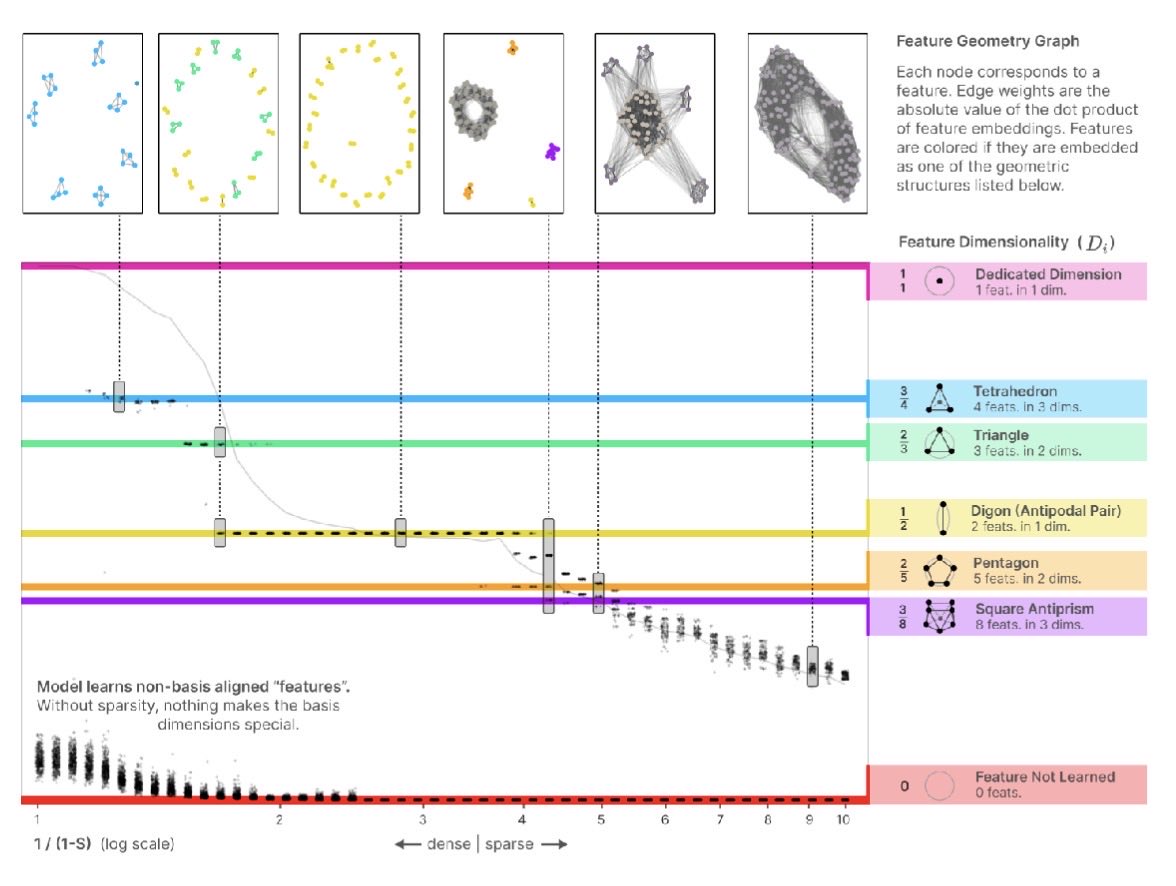
After building some mathematical foundation for transformers, we are on to tackling the next foundational paper, Toy Models of Superposition at the ML understanding group of @Cohere_Labs. This paper explores how networks pack many features into fewer dimensions, forming…

《CS 224V:Conversational Virtual Assistants with Deep Learning》这门课不错,但是没有上视频比较可惜。 核心目标是构造基于LLM的聊天助手,包括 RAG、Agent、实时语音相关的技术点。 web.stanford.edu/class/cs224v/s…


Holy shit. MIT just built an AI that can rewrite its own code to get smarter 🤯 It’s called SEAL (Self-Adapting Language Models). Instead of humans fine-tuning it, SEAL reads new info, rewrites it in its own words, and runs gradient updates on itself literally performing…


Can LLMs reason like a student? 👩🏻🎓📚✏️ For educational tools like AI tutors, modeling how students make mistakes is crucial. But current LLMs are much worse at simulating student errors ❌ than performing correct ✅ reasoning. We try to fix that with our method MISTAKE 🤭👇


Introducing 𝐓𝐡𝐢𝐧𝐤𝐢𝐧𝐠 𝐰𝐢𝐭𝐡 𝐂𝐚𝐦𝐞𝐫𝐚📸, a unified multimodal model that integrates camera-centric spatial intelligence to interpret and create scenes from arbitrary viewpoints. Project Page: kangliao929.github.io/projects/puffi… Code: github.com/KangLiao929/Pu…

MIT's 6.851: Advanced Data Structures (Spring'21) courses.csail.mit.edu/6.851/spring21/ This has been on my recommendation list for a while, and the Memory hierarchy discussions are great in the context of cache-oblivious algorithms.

"Cache‑Oblivious Algorithms and Data Structures" by Erik D. Demaine erikdemaine.org/papers/BRICS20… This is a foundational survey on designing cache‑oblivious algorithms and data structures that perform as well as cache‑aware approaches that require hardcoding cache size (M) and block…


📢📢📢We've released the ScanNet++ Novel View Synthesis Benchmark for iPhone data! 🥳 Test your models on RGBD video featuring real-world challenges like exposure changes & motion blur! Download the newest iPhone NVS test split and submit your results! ⬇️ scannetpp.mlsg.cit.tum.de/scannetpp/benc…

New inference method TAG fights diffusion model hallucinations Introducing Tangential Amplifying Guidance (TAG): a training-free, plug-and-play method for diffusion models that significantly reduces hallucinations and boosts sample quality by steering generation to…


🚀 Dear Future 𝗔𝗜 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿, If you want to break into AI in 2025, stop chasing trends and start mastering the fundamentals. I've curated a list of must-read books 📚 that every successful AI Engineer swears by, from Machine Learning to LLMs & MLOps. Ready to level…



CLoD-GS: Continuous Level-of-Detail via 3D Gaussian Splatting Abstract (excerpt): Traditionally, Level of Detail (LoD) is implemented using discrete levels (DLoD), where multiple, distinct versions of a model are swapped out at different distances. This long-standing paradigm,…





Mamba3 just silently dropped on ICLR🤯 A faster, longer-context, and more scalable LLM architecture than Transformers A few years ago, some researchers started rethinking sequence modeling from a different angle. Instead of stacking more attention layers, they went back to an…





"Introduction to Machine Learning Systems" - FREE from MIT Press - Authored by Harvard Professor - 2048 Pages To Get It Simply: 1. Retweet & Reply "ML" 2. Follow so that I will DM you.


Our general-reasoner (arxiv.org/abs/2505.14652) came out in March this year and has been accepted by NeurIPS. We are among the first few works to extract QA from pre-training data for RL. No comparison, no citation to our paper at all 😂



🚀 Scaling RL to Pretraining Levels with Webscale-RL RL for LLMs has been bottlenecked by tiny datasets (<10B tokens) vs pretraining (>1T). Our Webscale-RL pipeline converts pretraining text into diverse RL-ready QA data — scaling RL to pretraining levels! All codes and…


This survey paper argues Small language models can handle most agent tasks, and big models step in only when needed. This setup cuts cost by 10x to 30x for common tool tasks. Agent work is mostly calling tools and producing structured outputs, not recalling vast facts. So a…

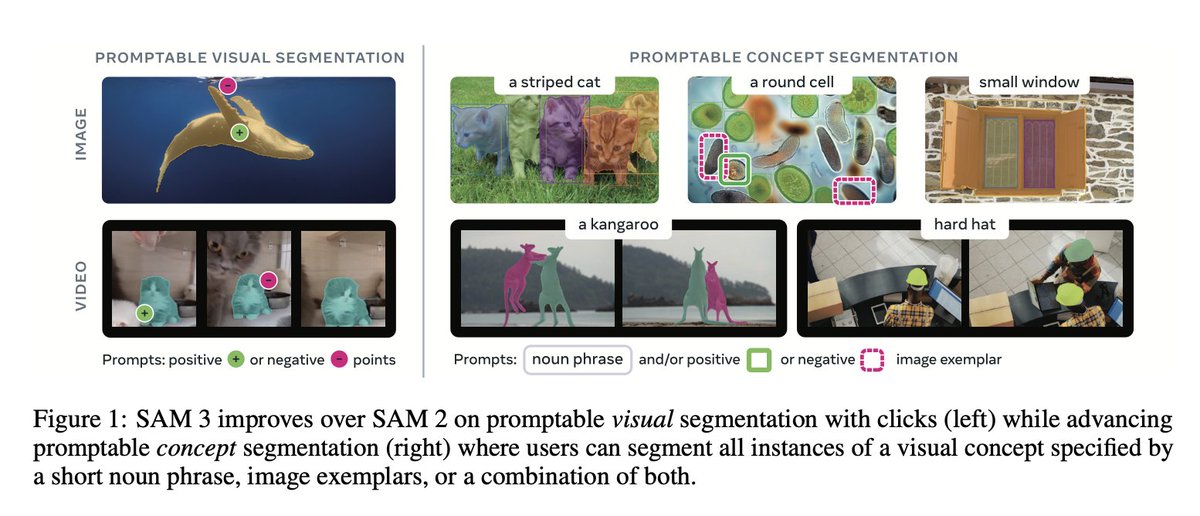
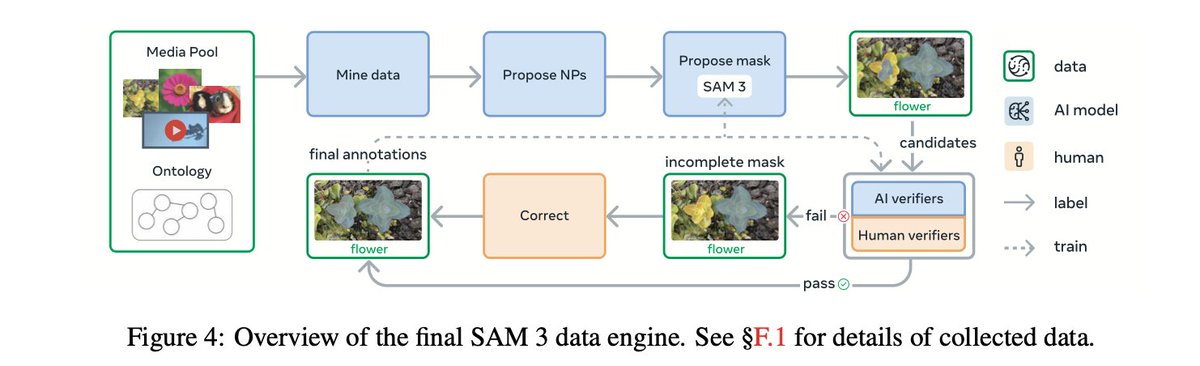
Segment Anything 3 just silently dropped on ICLR 🤯 The first SAM let you click on an object to segment it. SAM 2 added video and memory. Now SAM 3 says: just describe what you want — “yellow school bus”, “striped cat”, “red apple” — and it will find and segment every instance…



🚀Try out rCM—the most advanced diffusion distillation! ✅First to scale up sCM/MeanFlow to 10B+ video models ✅Open-sourced FlashAttention-2 JVP kernel & FSDP/CP support ✅High quality & diversity videos in 2~4 steps Paper: arxiv.org/abs/2510.08431 Code: github.com/NVlabs/rcm
























































United States 트렌드
- 1. Prince Andrew 30.6K posts
- 2. No Kings 274K posts
- 3. Duke of York 14.4K posts
- 4. #BostonBlue N/A
- 5. Chandler Smith N/A
- 6. Zelensky 73.2K posts
- 7. Andrea Bocelli 20.1K posts
- 8. Strasbourg 26K posts
- 9. #DoritosF1 N/A
- 10. zendaya 9,586 posts
- 11. #SELFIESFOROLIVIA N/A
- 12. #FursuitFriday 17.3K posts
- 13. Arc Raiders 7,183 posts
- 14. trisha paytas 4,157 posts
- 15. #CashAppFriday N/A
- 16. Apple TV 12.3K posts
- 17. TPOT 20 SPOILERS 11.9K posts
- 18. Trevon Diggs 1,554 posts
- 19. Louisville 4,441 posts
- 20. My President 50.8K posts
Something went wrong.
Something went wrong.