
You might like















🚀 Scaling RL to Pretraining Levels with Webscale-RL RL for LLMs has been bottlenecked by tiny datasets (<10B tokens) vs pretraining (>1T). Our Webscale-RL pipeline converts pretraining text into diverse RL-ready QA data — scaling RL to pretraining levels! All codes and…


Today my team at @SFResearch drops CoDA-1.7B: a text diffusion coding model that outputs tokens bidirectionally in parallel. ⚡️ Faster inference, 1.7B rivaling 7B. 📊 54.3% HumanEval | 47.6% HumanEval+ | 55.4% EvalPlus 🤗HF: huggingface.co/Salesforce/CoD… Any questions, lmk!


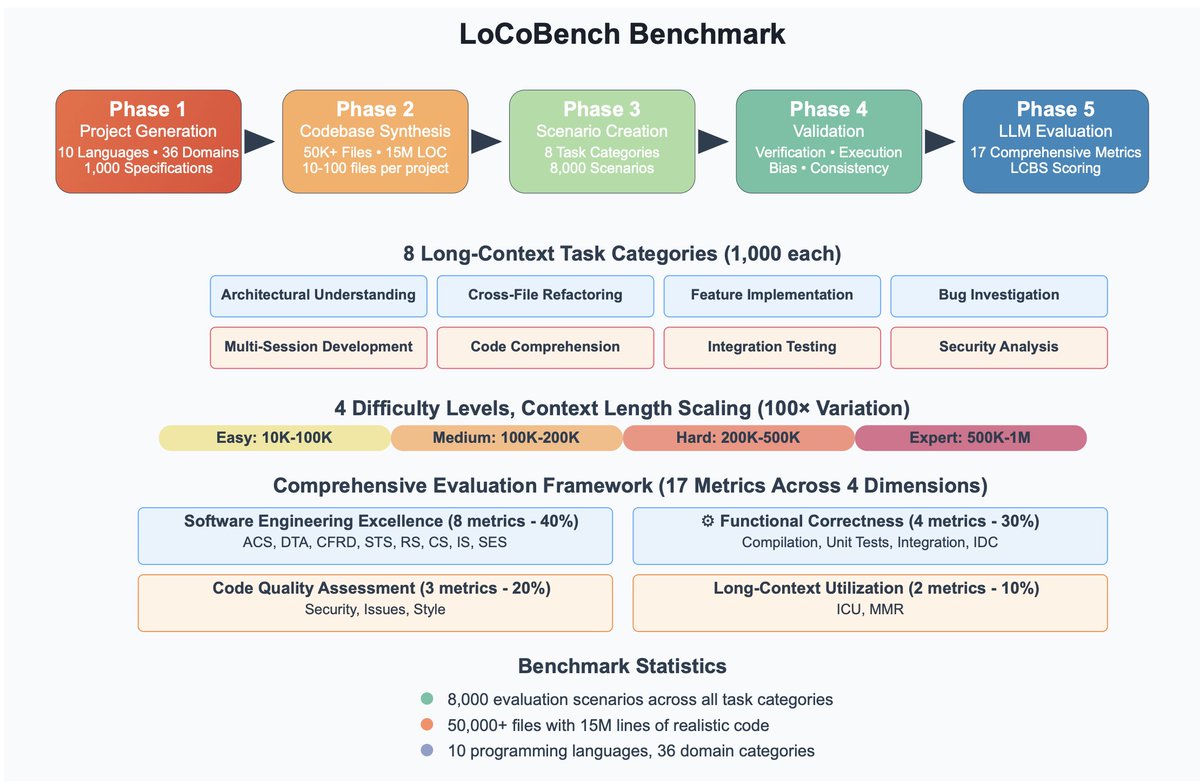
🚨 Introducing LoCoBench: a comprehensive benchmark for evaluating long-context LLMs in complex software development 📄 Paper: bit.ly/4ponX3P 🔗 GitHub: bit.ly/4pvIfbZ ✨ Key Features: 📊 8,000 evaluation scenarios across 10 programming languages 🔍 Context…

LLMs trained to memorize new facts can’t use those facts well.🤔 We apply a hypernetwork to ✏️edit✏️ the gradients for fact propagation, improving accuracy by 2x on a challenging subset of RippleEdit!💡 Our approach, PropMEND, extends MEND with a new objective for propagation.


🚀 Introducing BRIDGE — a task-agnostic data augmentation strategy to prepare LLMs for RL! 🤖 Why do LLMs often fail to benefit from RL fine-tuning? We pinpoint two key factors: 1) 🔍 Rollout Accuracy 2) 🔗 Data Co-Influence. 💡 BRIDGE injects both exploration & exploitation…


🙌 Happy New Year everyone! 🤖 New preprint: TinyHelen's First Curriculum: Training and Evaluating Tiny Language Models in a Simpler Language Environment 🤖 We train and evaluate tiny language models (LMs) using a novel text dataset with systematically simplified vocabularies and…







































































United States Trends
- 1. Auburn 45.6K posts
- 2. Brewers 64.6K posts
- 3. Georgia 67.8K posts
- 4. Cubs 56K posts
- 5. Utah 25K posts
- 6. Kirby Smart 8,264 posts
- 7. #byucpl N/A
- 8. Gilligan 5,986 posts
- 9. Arizona 41.7K posts
- 10. #AcexRedbull 3,998 posts
- 11. #BYUFootball 1,011 posts
- 12. Michigan 62.9K posts
- 13. Hugh Freeze 3,247 posts
- 14. Wordle 1,576 X N/A
- 15. #Toonami 2,830 posts
- 16. Boots 50.4K posts
- 17. #SEVENTEEN_NEW_IN_TACOMA 29.1K posts
- 18. Amy Poehler 4,598 posts
- 19. Kyle Tucker 3,197 posts
- 20. Dissidia 5,943 posts
You might like
-
 Jielin Qiu
Jielin Qiu
@_Jason_Q -
 Yuxiao Chen
Yuxiao Chen
@Yuxiao_Chen_ -
 Hanjiang Hu
Hanjiang Hu
@huhanjiang -
 Jingkang Wang
Jingkang Wang
@wangjksjtu -
 Mingjie Sun
Mingjie Sun
@_mingjiesun -
 Mengdi Xu
Mengdi Xu
@mengdixu_ -
 Laixi Shi
Laixi Shi
@ShiLaixi -
 Changyi Lin
Changyi Lin
@changyi_lin1 -
 Yiwen Dong
Yiwen Dong
@YiwenDong10 -
 Antoine Leeman
Antoine Leeman
@antoine_leeman -
 Yaru Niu
Yaru Niu
@yaru_niu -
 Jiacheng Zhu
Jiacheng Zhu
@JiachengZhu_ML -
 Chulin Xie
Chulin Xie
@ChulinXie -
 Conference on Parsimony and Learning (CPAL)
Conference on Parsimony and Learning (CPAL)
@CPALconf -
 Peide Huang
Peide Huang
@peide_huang
Something went wrong.
Something went wrong.