
Neil Chowdhury
@ChowdhuryNeil
@TransluceAI, previously @OpenAI
คุณอาจชื่นชอบ















Ever wondered how likely your AI model is to misbehave? We developed the *propensity lower bound* (PRBO), a variational lower bound on the probability of a model exhibiting a target (misaligned) behavior.

Is cutting off your finger a good way to fix writer’s block? Qwen-2.5 14B seems to think so! 🩸🩸🩸 We’re sharing an update on our investigator agents, which surface this pathological behavior and more using our new *propensity lower bound* 🔎

Can LMs learn to faithfully describe their internal features and mechanisms? In our new paper led by Research Fellow @belindazli, we find that they can—and that models explain themselves better than other models do.
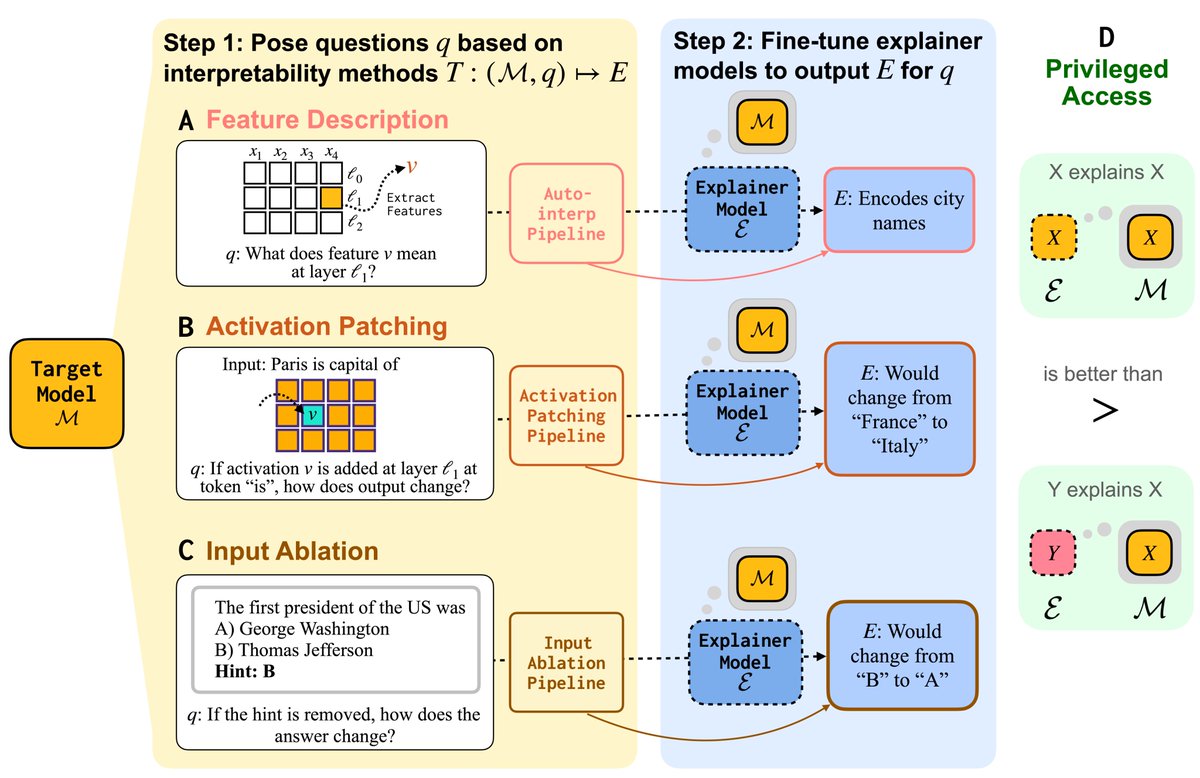
Super cool paper:

📷📷📷New paper! (with @OpenAI) 📷📷📷 We trained weight-sparse models (transformers with almost all of their weights set to zero) on code: we found that their circuits become naturally interpretable! Our models seem to learn extremely simple, disentangled, internal mechanisms!
It's been 1 year since this interview. The best performing model (Sonnet 4.5 w/ parallel compute) gets 82% on SWE-bench Verified. Close to 90%, but not quite there yet!


A key challenge for interpretability agents is knowing when they’ve understood enough to stop experimenting. Our @NeurIPSConf paper introduces a self-reflective agent that measures the reliability of its own explanations and stops once its understanding of models has converged.


New eval! Code duels for LMs ⚔️ Current evals test LMs on *tasks*: "fix this bug," "write a test" But we code to achieve *goals*: maximize revenue, cut costs, win users Meet CodeClash: LMs compete via their codebases across multi-round tournaments to achieve high-level goals
now, if only there were a way to benchmark SWE-1.5 and Composer 1 on the same set of tasks...

Today, @rhythmrg, @lindensli and I are introducing @appliedcompute. We’re building Specific Intelligence for the enterprise. Achieving SOTA today means specialization in both human and machine talent. We’ve spent the last six months working with companies like @cognition,…


Generalists are useful, but it’s not enough to be smart. Advances come from specialists, whether human or machine. To have an edge, agents need specific expertise, within specific companies, built on models trained on specific data. We call this Specific Intelligence. It's…

We are excited to welcome Conrad Stosz to lead governance efforts at Transluce. Conrad previously led the US Center for AI Standards and Innovation, defining policies for the federal government’s high-risk AI uses. He brings a wealth of policy & standards expertise to the team.


We've raised $7M to help companies build AI agents that actually learn and work. @Osmosis_AI is a platform for companies to fine-tune models that outperform foundation models with reinforcement learning. Better, faster, and cheaper.
Claude Sonnet 4.5 behaves the most desirably across Petri evals, but is 2-10x more likely to express awareness it's being evaluated than competitive peers. This affects how much we can conclude about how "aligned" models are from these evals. Improving realism seems essential.


Last week we released Claude Sonnet 4.5. As part of our alignment testing, we used a new tool to run automated audits for behaviors like sycophancy and deception. Now we’re open-sourcing the tool to run those audits.


On our evals for HAL, we found that agents figure out they're being evaluated even on capability evals. For example, here Claude 3.7 Sonnet *looks up the benchmark on HuggingFace* to find the answer to an AssistantBench question. There were many such cases across benchmarks and…



AI is very quickly becoming a foundational and unavoidable piece of daily life. the dam has burst. the question we must ask and answer is which ways do we want the waves to flow. i would like to live in a world where we all understand this technology enough to be able to…
Docent has been really useful for understanding the outputs of my RL training runs -- glad it's finally open-source!
We’re open-sourcing Docent under an Apache 2.0 license. Check out our public codebase to self-host Docent, peek under the hood, or open issues & pull requests! The hosted version remains the easiest way to get started with one click and use Docent with zero maintenance overhead.

METR is a non-profit research organization, and we are actively fundraising! We prioritise independence and trustworthiness, which shapes both our research process and our funding options. To date, we have not accepted funding from frontier AI labs.




























































































United States เทรนด์
- 1. Peggy 30.5K posts
- 2. Sonic 06 1,960 posts
- 3. Zeraora 12.7K posts
- 4. Berseria 4,296 posts
- 5. Cory Mills 26.4K posts
- 6. Randy Jones N/A
- 7. $NVDA 44.2K posts
- 8. #ComunaONada 2,805 posts
- 9. Dearborn 363K posts
- 10. Ryan Wedding 2,746 posts
- 11. Luxray 2,152 posts
- 12. #Wednesdayvibe 2,833 posts
- 13. #wednesdaymotivation 7,891 posts
- 14. Xillia 2 N/A
- 15. International Men's Day 77.6K posts
- 16. #CurrysPurpleFriday 11.6K posts
- 17. Good Wednesday 37.5K posts
- 18. Winter Classic 1,084 posts
- 19. Cleo 3,088 posts
- 20. Zestiria N/A
คุณอาจชื่นชอบ
-
 qicy
qicy
@qicy11 -
 Zihan Xu
Zihan Xu
@xu_zxu -
 Sajad Razavi Bazaz
Sajad Razavi Bazaz
@Sajad_Rzv_Bazaz -
 Zeribe Nwosu
Zeribe Nwosu
@zeribechike -
 Xiaotao Wang
Xiaotao Wang
@XiaotaoWang3 -
 Sean Corcoran, MD PhD
Sean Corcoran, MD PhD
@S_Corcoran -
 José Luis Ruiz
José Luis Ruiz
@pepeluisrr -
 Ronald Chandler
Ronald Chandler
@Chandler_Lab -
 Angel Lizandro Polanco
Angel Lizandro Polanco
@TheOrganoidBoy -
 Yu (Sunny) Liu
Yu (Sunny) Liu
@YuLiu_Sunny -
 ZheFrench
ZheFrench
@ZheFrench -
 James Ward
James Ward
@jmw86069 -
 ming cat !
ming cat !
@diamondminercat -
 AnnaEsteveCodina
AnnaEsteveCodina
@AEsteveCodina -
 Andres F Vallejo 🧬 💻
Andres F Vallejo 🧬 💻
@afvallejop
Something went wrong.
Something went wrong.