
Gonna try to pin a few favorite posts that linger in mind over time:

Amusing how 99% of people using their own brains forget how it works: The brain is an advanced probability machine. It keeps predicting the next most likely thought, word, or action based on incoming signals and past learning. Under the hood, billions of neurons are doing…

🎉 How do we measure the rapid progress of robotic learning and embodied AI research? The 1st BEHAVIOR challenge results are out! And we're to see such strong performance on 50 challenging household tasks. Congrats to the winning teams! 🥇Robot Learning Collective 🥈Comet…

Don't think of LLMs as entities but as simulators. For example, when exploring a topic, don't ask: "What do you think about xyz"? There is no "you". Next time try: "What would be a good group of people to explore xyz? What would they say?" The LLM can channel/simulate many…

Stanford literally dropped a 70-minute masterclass on how GPT works

Oh wow...note to self, need to read and compare to synthetic pathology paper (this may change how I think about that significantly)

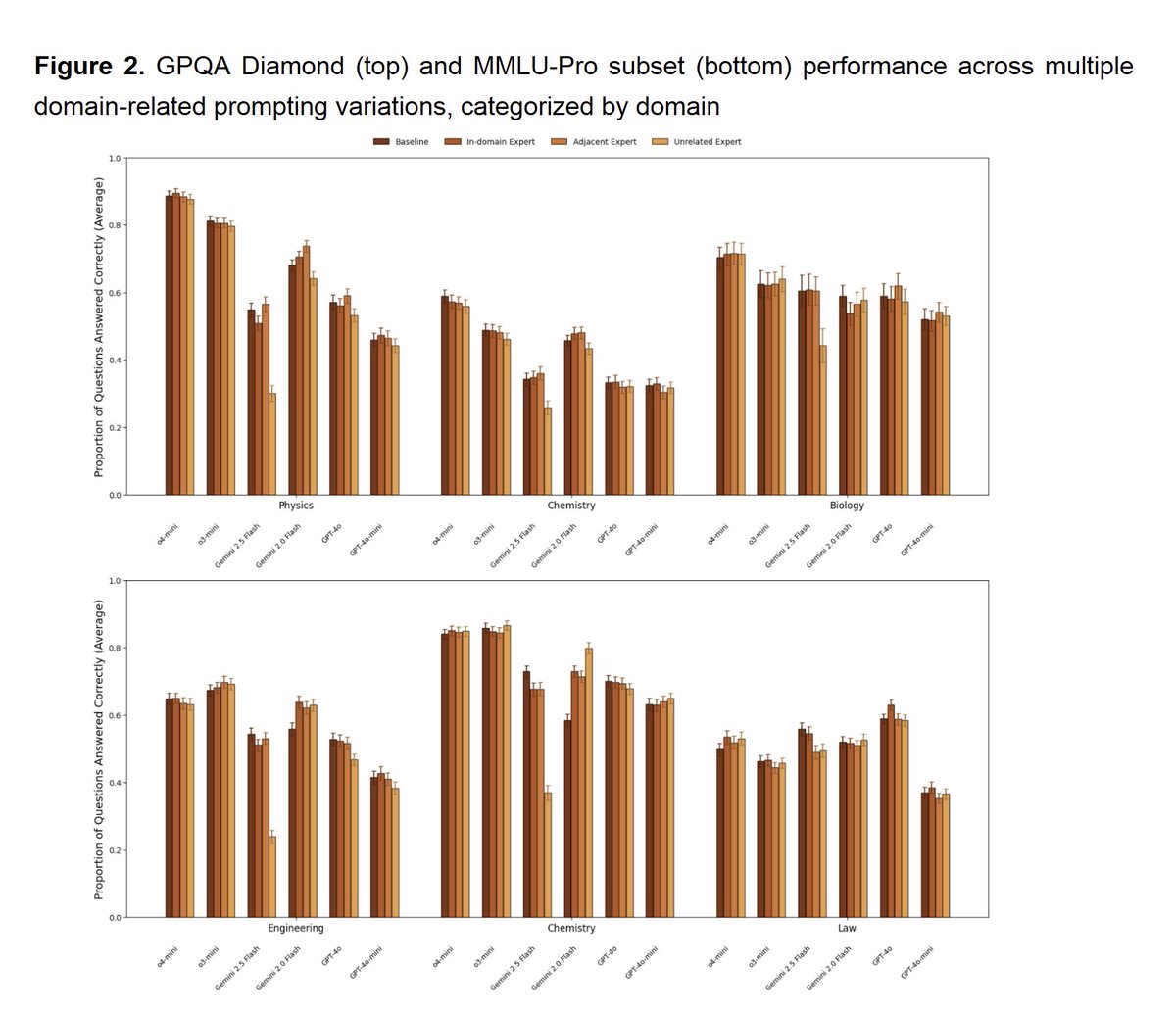
We tested one of the most common prompting techniques: giving the AI a persona to make it more accurate We found that telling the AI "you are a great physicist" doesn't make it significantly more accurate at answering physics questions, nor does "you are a lawyer" make it worse.


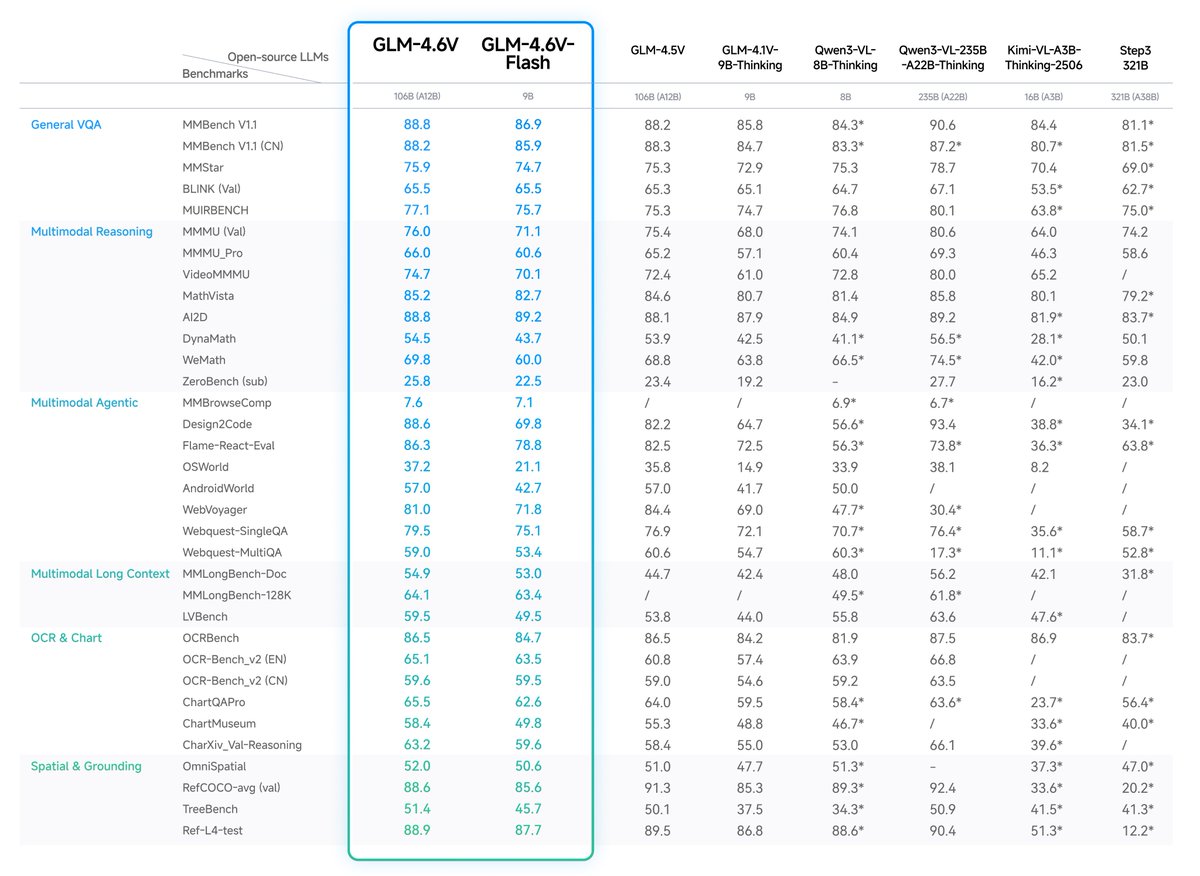
GLM-4.6V Series is here🚀 - GLM-4.6V (106B): flagship vision-language model with 128K context - GLM-4.6V-Flash (9B): ultra-fast, lightweight version for local and low-latency workloads First-ever native Function Calling in the GLM vision model family Weights:…

Has Claude sped up your biology research or enabled new capabilities for your lab? Is it underperforming on specific tasks? Do you have ideas to improve its usefulness in a specific domain of biology? Share feedback here: forms.gle/bXPqhLAHeo2CSa…

Demis Hassabis says the most ignored marvel is AI’s ability to understand video, images, and audio together. Gemini can watch a movie scene and explain the symbolism behind a tiny gesture. This shows the model grasps concepts, not just pixels or words. Such deep cross-media…

If you need a video guide to Karpathy's nanochat, check out Stanford's CS336! It covers: - Tokenization - Resource Accounting - Pretraining - Finetuning (SFT/RLHF) - Overview of Key Architectures - Working with GPUs - Kernels and Tritons - Parallelism - Scaling Laws - Inference…


As everyone gets increasingly excited about RL, imo one underrated method is mid-training / SFT to solve the cold-start problem before RLing. New paper from CMU highlights that 1) strong pretraining and midtraining are essential to get full RL gains 2) PRMs reduce reward…


New Anthropic research! We study how to train models so that high-risk capabilities live in a small, separate set of parameters, allowing clean capability removal when needed – for example in CBRN or cybersecurity domains.


Banger paper from Stanford University on the missing layer of AGI just flipped the entire “LLMs are just pattern matchers” argument on its head. Not scaling tricks. Not another architecture. A "coordination layer" that actually makes models think. Here’s why this is insane 👇…


It seems likely that mitochondria transfer and mitochondria-based therapies will be a significant part of medicine in the future.

Boosting mitochondria number and function to slow cellular aging washingtonpost.com/science/2025/1… pnas.org/doi/10.1073/pn…

I’ve been at NeurIPS this past week. Here’s six things I learned: 1. Basically everyone is doing RL 2. And anyone who isn’t doing RL is doing a startup for data (usually for RL) 3. Diffusion LMs are popular enough that you now have to clarify discrete or continuous 4. I…

all roads lead to the same subspace "The Universal Weight Subspace Hypothesis" 500 ViTs, 500 Mistral LoRAs, 50 LLaMA models all collapse into shared 16-dimension subspaces regardless of data Not every problem in AI is a data one


Open recipe to turn Qwen3 into a diffusion LLM 👀👀 > Swap the causal mask for bidirectional attention > Source model matters a lot for performance > Block diffusion (BD3LM) >> masked diffusion (MDLM) > Light SFT with masking Great work from @asapzzhou with his dLLM library!
fun and remarkably good!

My wife has been using AI to create educational songs for our children (She's a Cardiac Electrophysiologist by day) It's already had a positive impact on our children (ages 4 and 7). Her workflow involves Claude, Suno, and NanoBanana This is mainly a "personal podcast" that…


GLM4.6V is out! It's a reasoning vision language model that can write code and do tool-calling 😍 comes in 10B dense and 108B MoE variants with 128k tokens context window supported by transformers and vLLM from the get-go! 🤗


Fine-tuning using GRPO, visually explained:

You're in a Research Scientist interview at Google. Interviewer: We have a base LLM that's terrible at maths. How would you turn it into a maths & reasoning powerhouse? You: I'll get some problems labeled and fine-tune the model. Interview over. Here's what you missed:
you put cells in a dish and energize then, they naturally connect. Either physically by growing protrusions. Or through secreted signals—cytokines, metabolites.

Bleak outlook for an AI-native social media platform that exploits real-time in-session signals to generate addictive content on the fly. openreview.net/pdf?id=1IpHkK5… #neurips @petergostev






























































































United States 趨勢
- 1. FINALLY DID IT 564K posts
- 2. The BONK 104K posts
- 3. good tuesday 32.2K posts
- 4. US Leading Investment Team 6,824 posts
- 5. #Nifty 11.8K posts
- 6. $FULC 10.3K posts
- 7. Jalen 79.2K posts
- 8. Eagles 121K posts
- 9. #tuesdayvibe 1,732 posts
- 10. #TuesdayFeeling 1,060 posts
- 11. #BAZAARWomenofTheYearXFreen 401K posts
- 12. Israel and Judah 1,777 posts
- 13. Chainers 1,805 posts
- 14. LINGLING BA HAUS64 514K posts
- 15. #Haus64xLingMOME 516K posts
- 16. Piers 90K posts
- 17. Polk County 5,633 posts
- 18. Herbert 34.3K posts
- 19. Chargers 88.5K posts
- 20. Oslo 74.7K posts
Something went wrong.
Something went wrong.