
HumanFirst
@HumanFirst_ai
The Hub for Conversational AI Data.
Bunları beğenebilirsin




Our partnership with @googlecloud will help bring GenAI into enterprise workflows with easy integrations to #CCAI, #BigQuery, #Dialogflow, and #VertexAI. More collaborative, more reliable, less technical, and less time-consuming. 🤝 youtube.com/watch?v=-cY7EM…
youtube.com
YouTube
Build better #AI faster with HumanFirst and Google Cloud
Our CEO, @paisible, joined @usernews with @PublicationsTr to talk about using data and prompt engineering to prioritize AI investments based on ground-truth customer insights. ✅ The full episode is available here: bit.ly/3tJfWyh
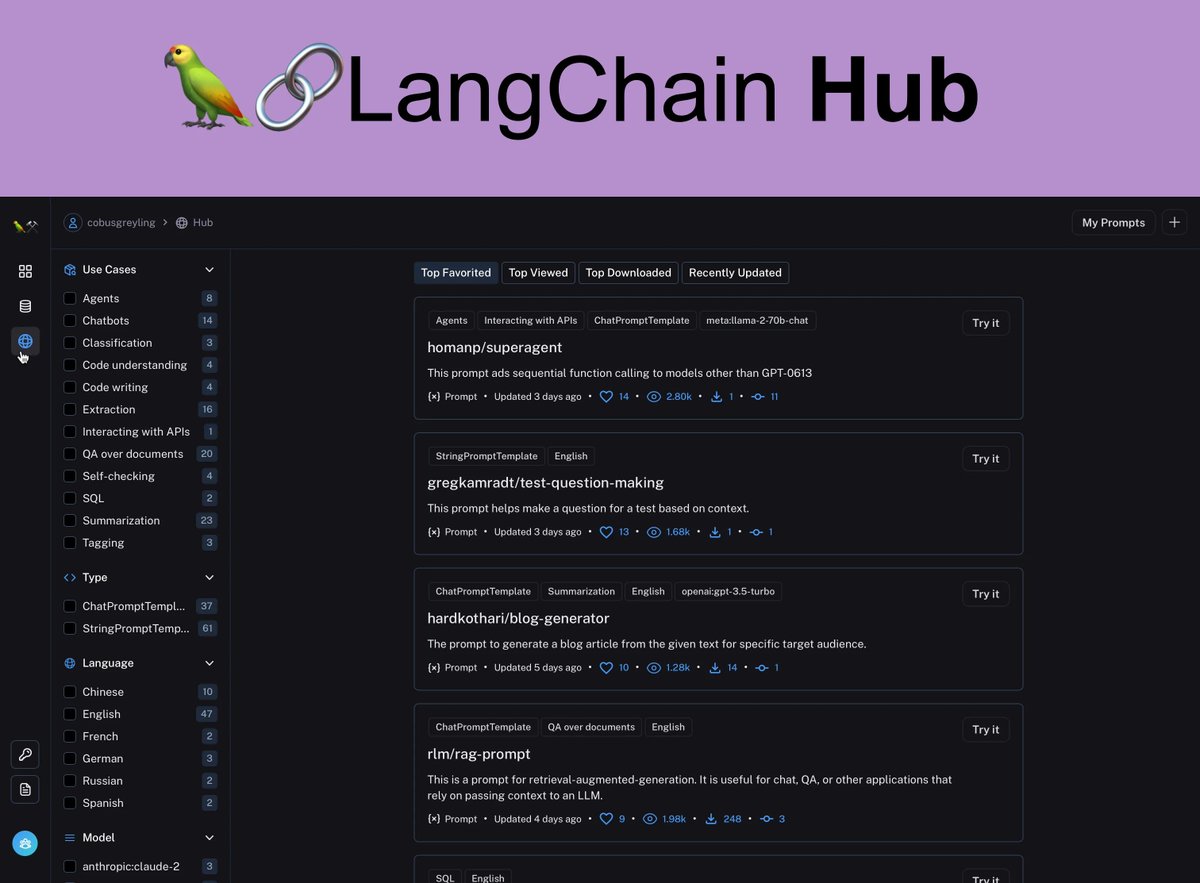
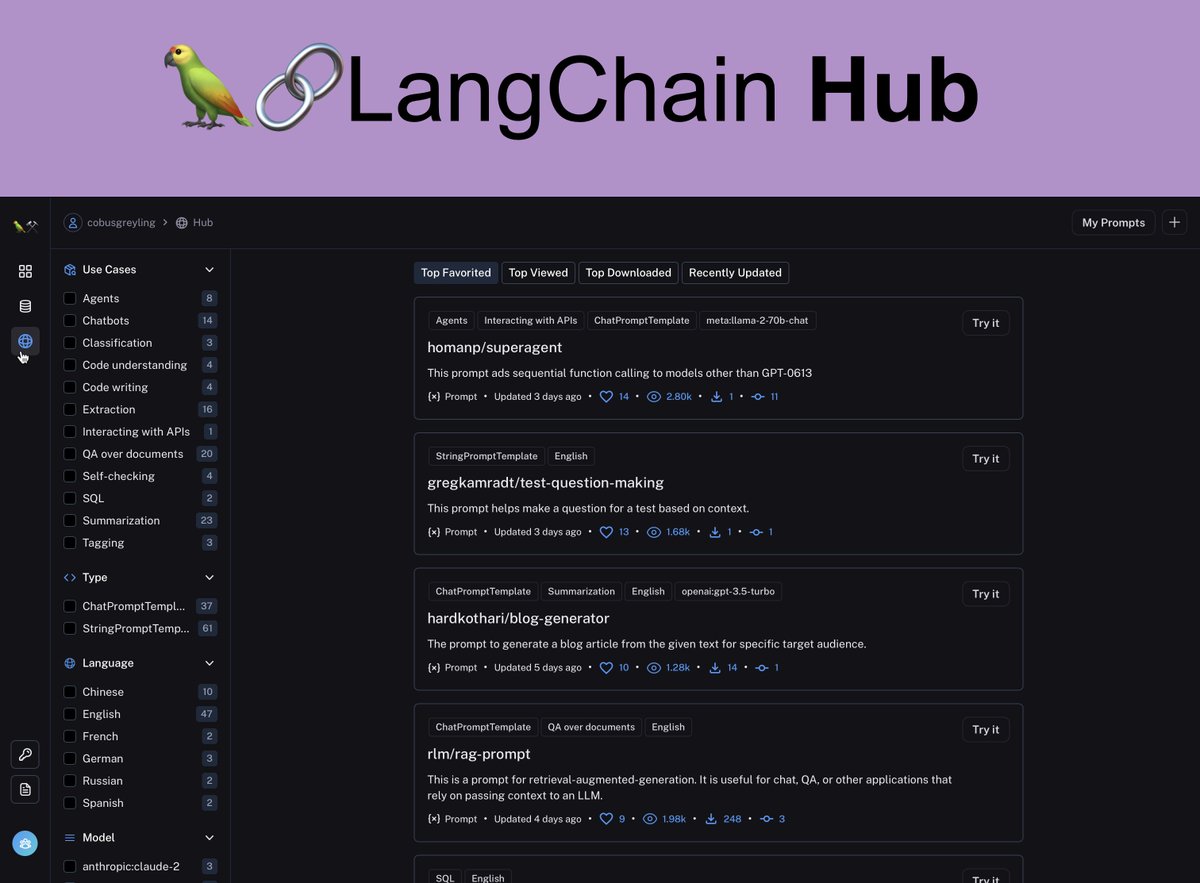
The LangChain Hub (Hub) is really an extension of the LangSmith studio environment and lives within the LangSmith web UI. Read more here: lnkd.in/ee5nRzBQ #LargeLanguageModels #PromptEngineering #ConversationalAI
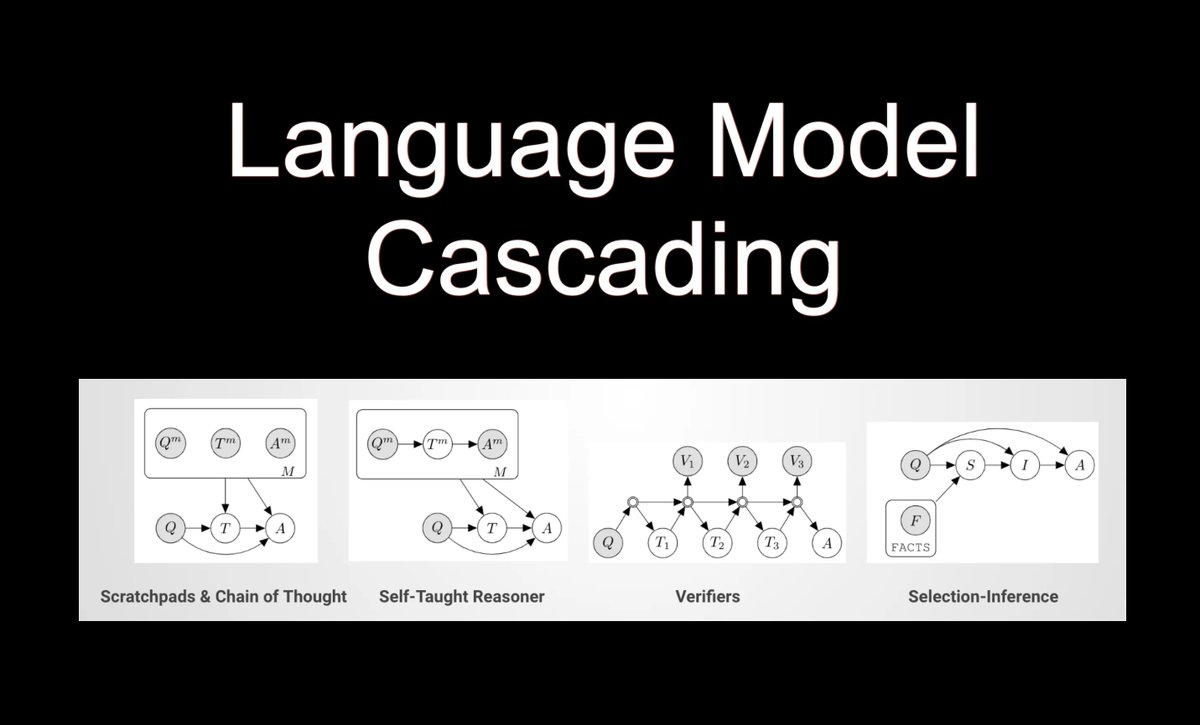
Language Model Cascading & Probabilistic Programming Language The term Language Model Cascading (LMC) was coined in July 2022, which seems like a lifetime ago considering the speed at which the LLM narrative arc develops… Read more here: humanfirst.ai/blog/language-…
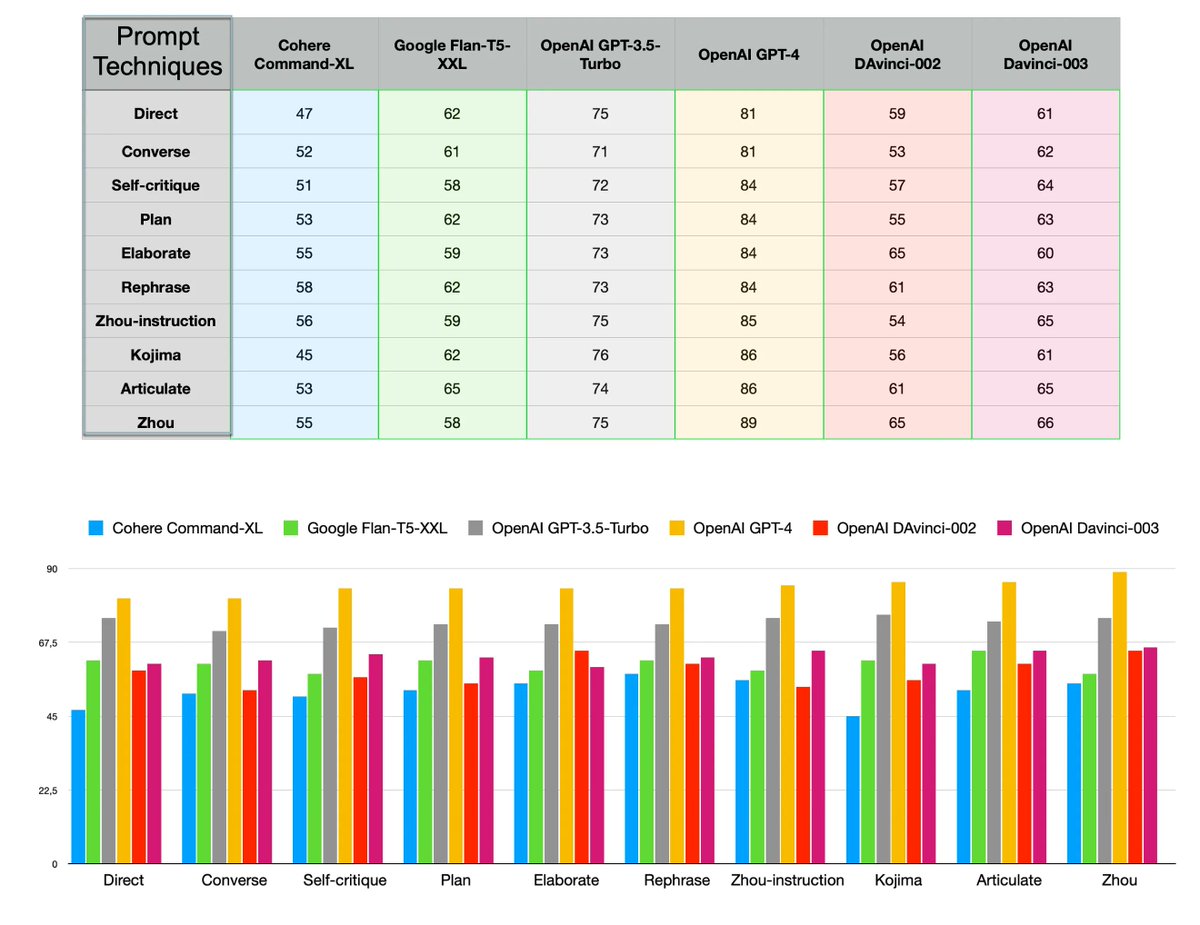
Comparing LLM Performance Against Prompt Techniques & Domain Specific Datasets. #LargeLanguageModels #LLMs #PromptEngineering Blog Post: humanfirst.ai/blog/comparing…
ICYMI - Announcement: A Powerful Partnership: HumanFirst Teams Up with Google Cloud to Boost Data Productivity, Custom AI Prompts and Models. Read more here: humanfirst.ai/blog/a-powerfu…

Does Submitting Long Context Solve All LLM Contextual Reference Challenges? #LargeLanguageModels #PromptEngineering #LLMs Read more here: humanfirst.ai/blog/does-subm…
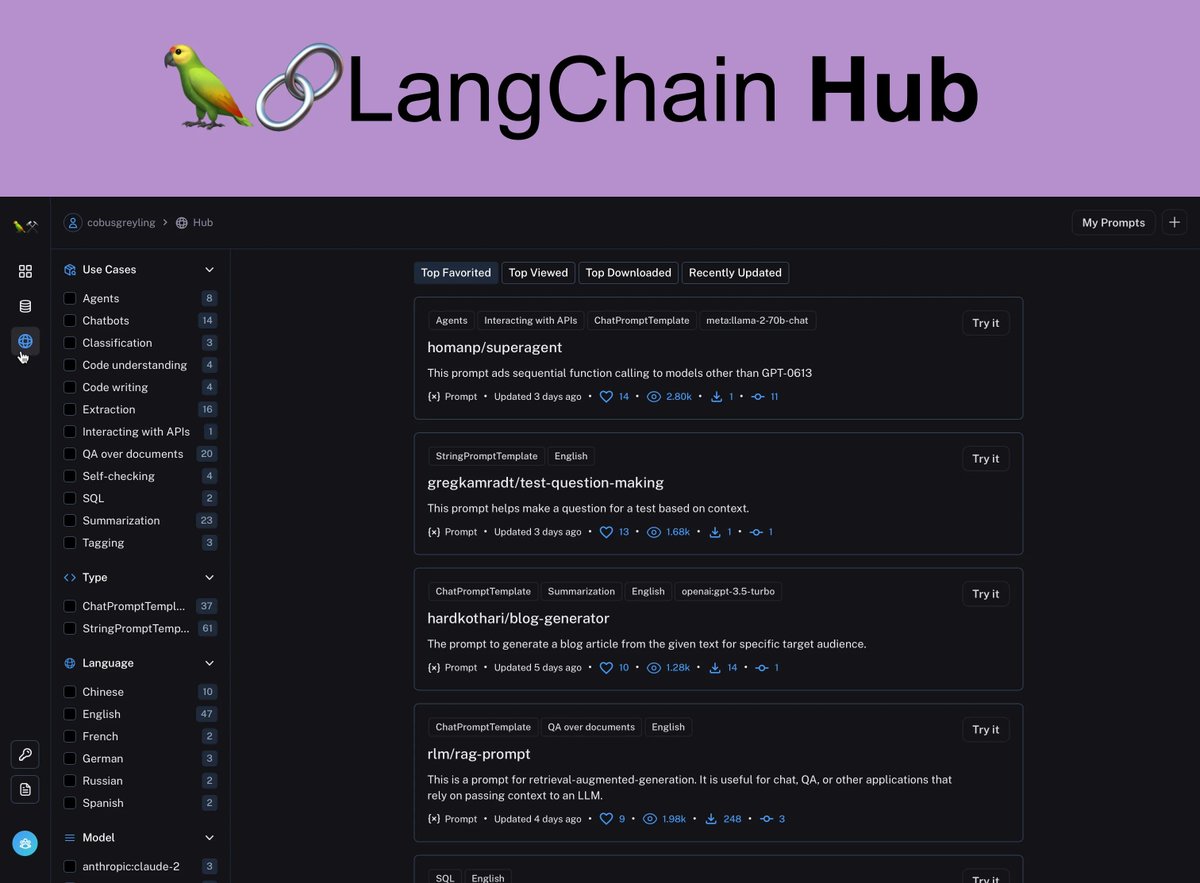
A few days ago LangChain launched the LangChain Hub… Read more here: lnkd.in/etfs2PJe #LargeLanguageModels #PromptEngineering #ConversationalAI
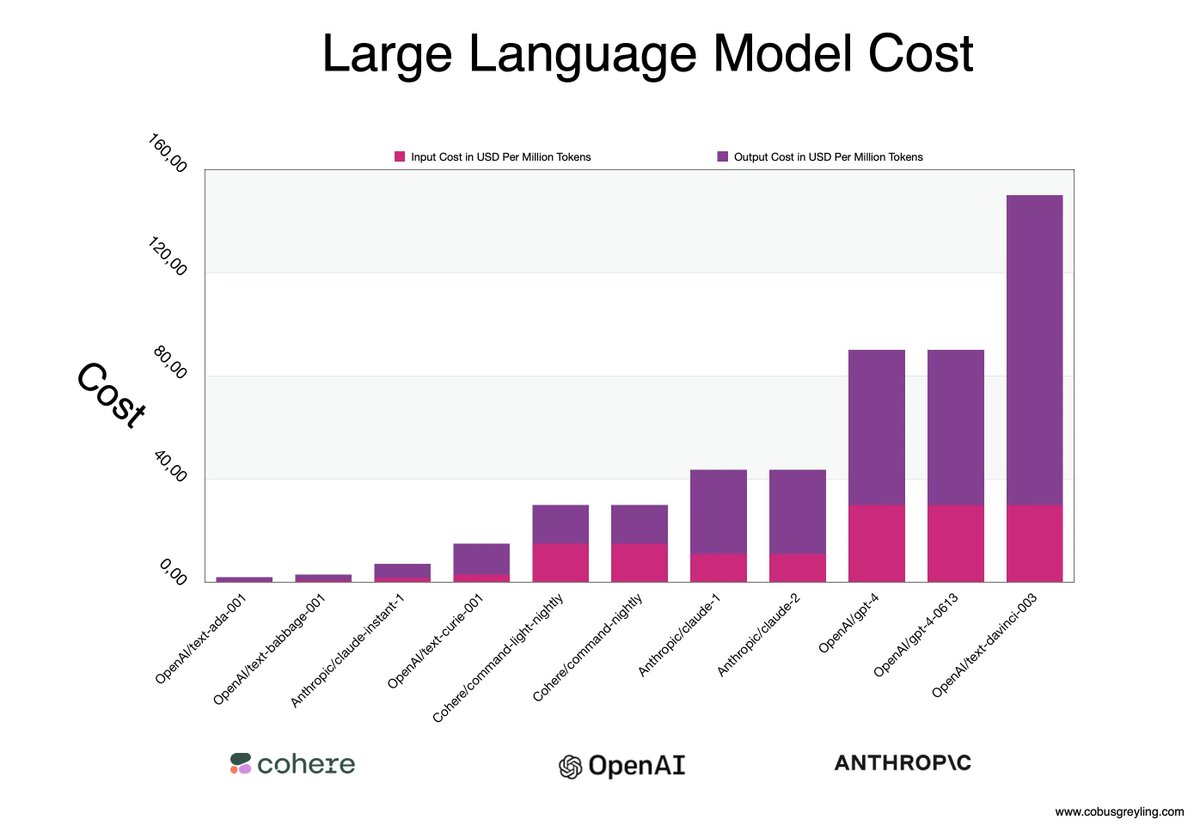
How Does Large Language Models Use Long Contexts? And how to manage the performance and cost of large context input to LLMs. #LargeLanguageModels #PromptEngineering #LLMs Read more here: humanfirst.ai/blog/how-does-…
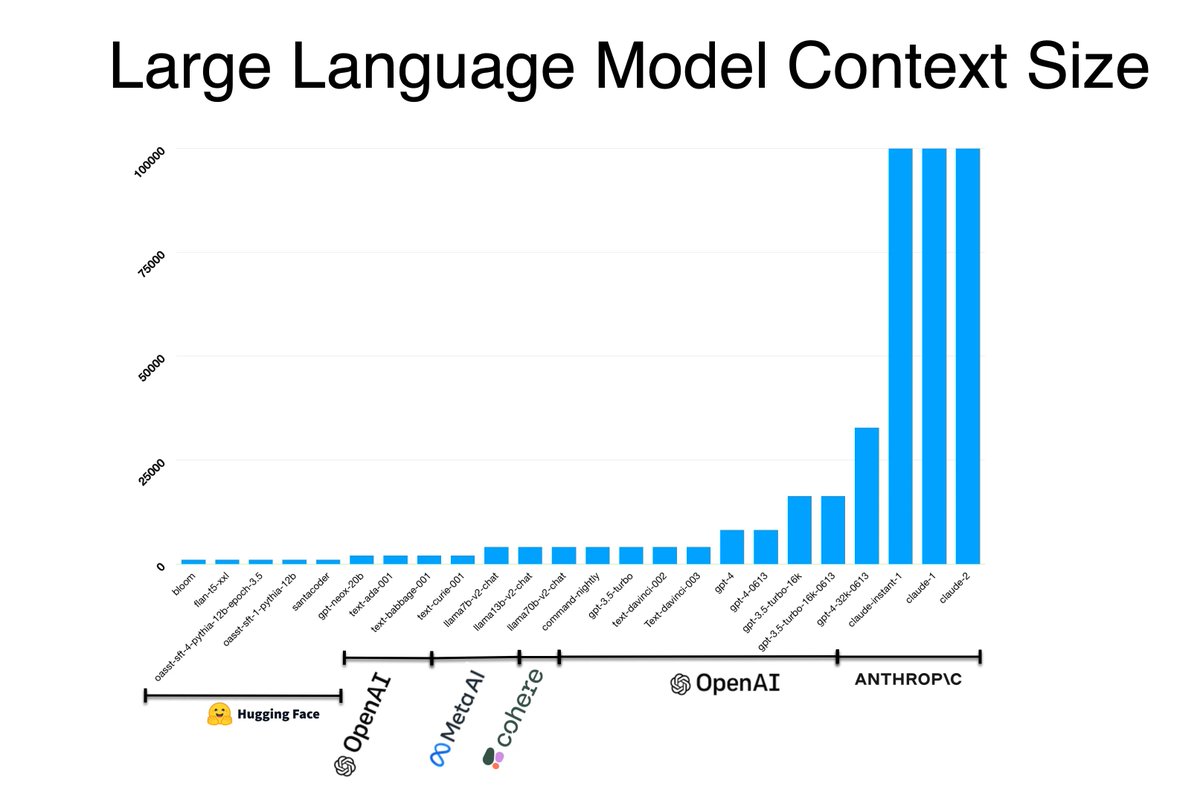
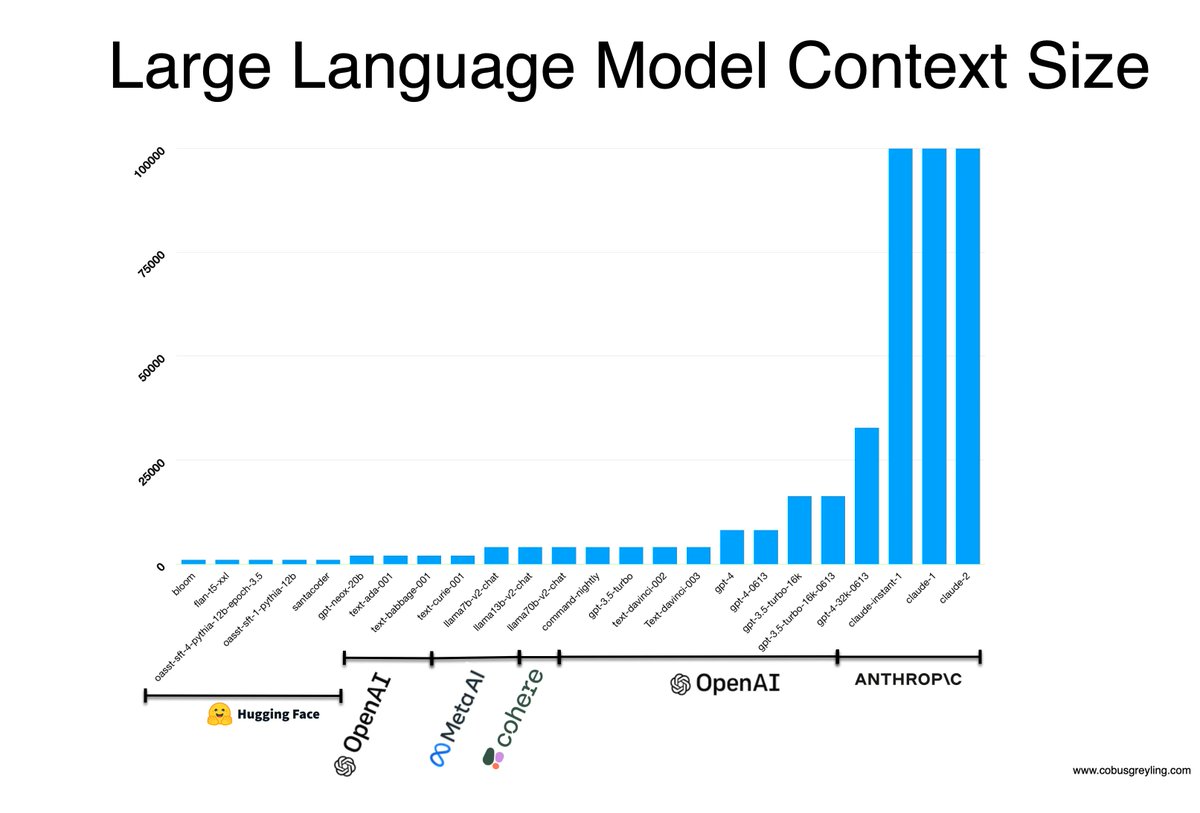
RAG & LLM Context Size In this article we consider the growing context of various Large Language Models (LLMs) to what extent it can be used and how a principle like RAG applies. #LargeLanguageModels #PromptEngineering #LLMs humanfirst.ai/blog/rag-llm-c…

It does seem that the future will be one where Generative Apps will become more model (LLM) agnostic and model migration will take place; with models becoming a utility. Blue oceans are turning into red oceans very fast; and a myriad of applications and products are at threat…
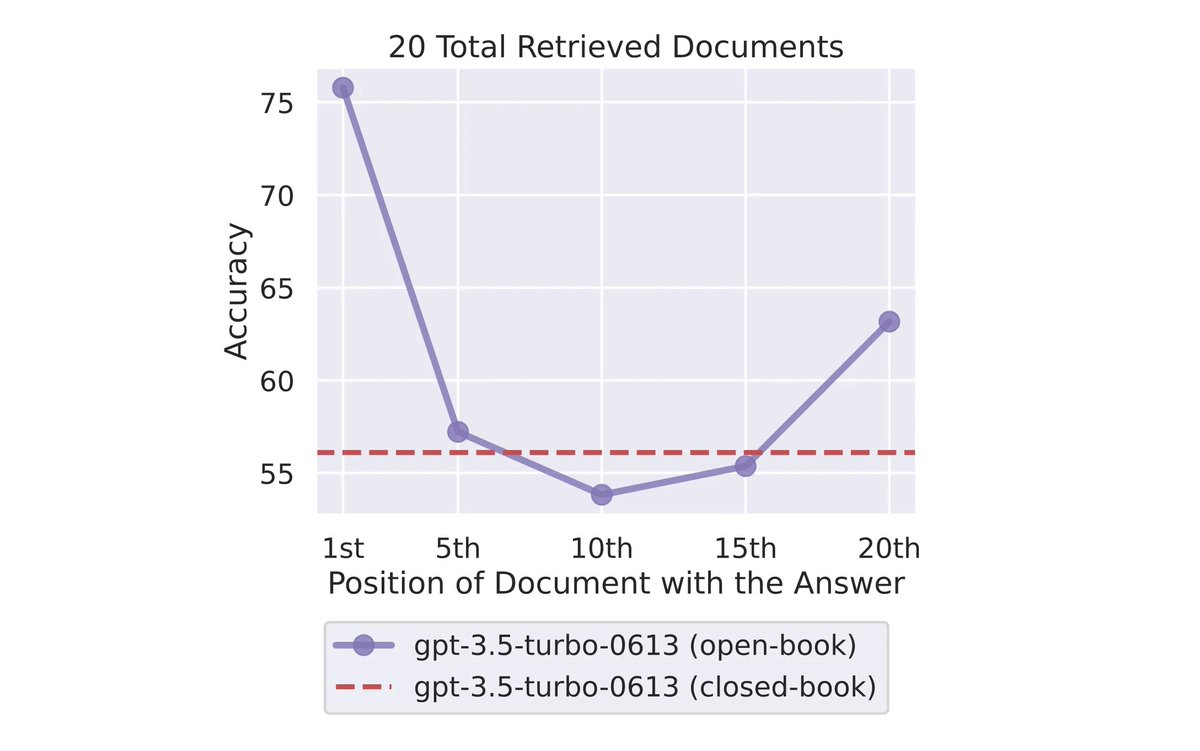
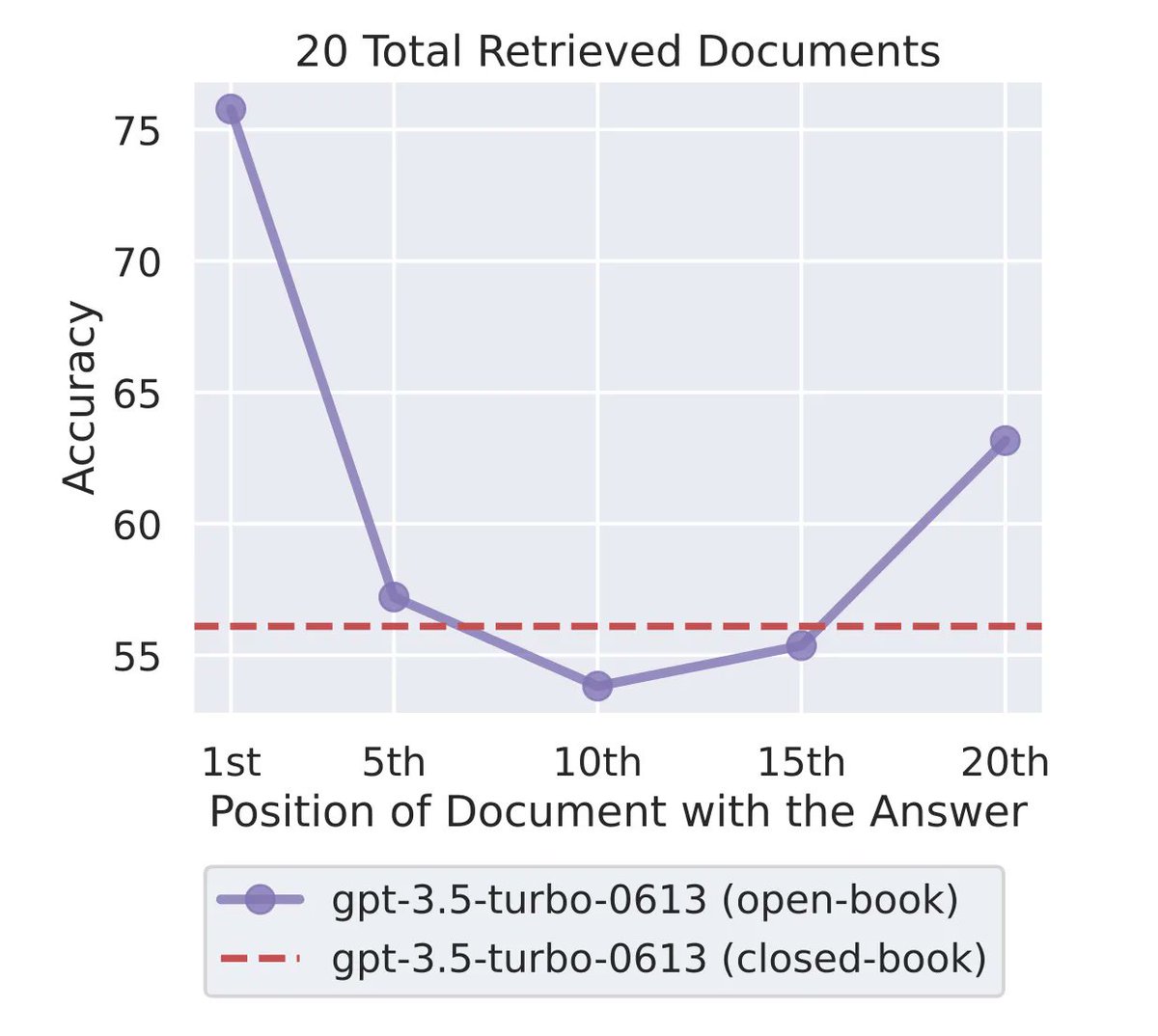
A recent study found that when LLMs are presented with longer input, LLM performance is best when relevant content is at the start or end of the input context. Performance degrades when relevant information is in the middle of long context. A few days ago Haystack by deepset…

Large Language Models (LLMs) are known to hallucinate. Hallucination is when a LLM generates a highly succinct and highly plausible answer; but factually incorrect. Hallucination can be negated by injecting prompts with contextually relevant data which the LLM can reference.…

This article considers how Ragas can be combined with LangSmith for more detailed insights into how Ragas goes about evaluating a RAG/LLM implementation. Currently Ragas makes use of OpenAI, but it would make sense for Ragas to become more LLM agnostic; And Ragas is based on…

In this article I consider the growing context of various Large Language Models (LLMs) to what extent it can be used and how a principle like RAG applies. Read more here: humanfirst.ai/blog/rag-llm-c…
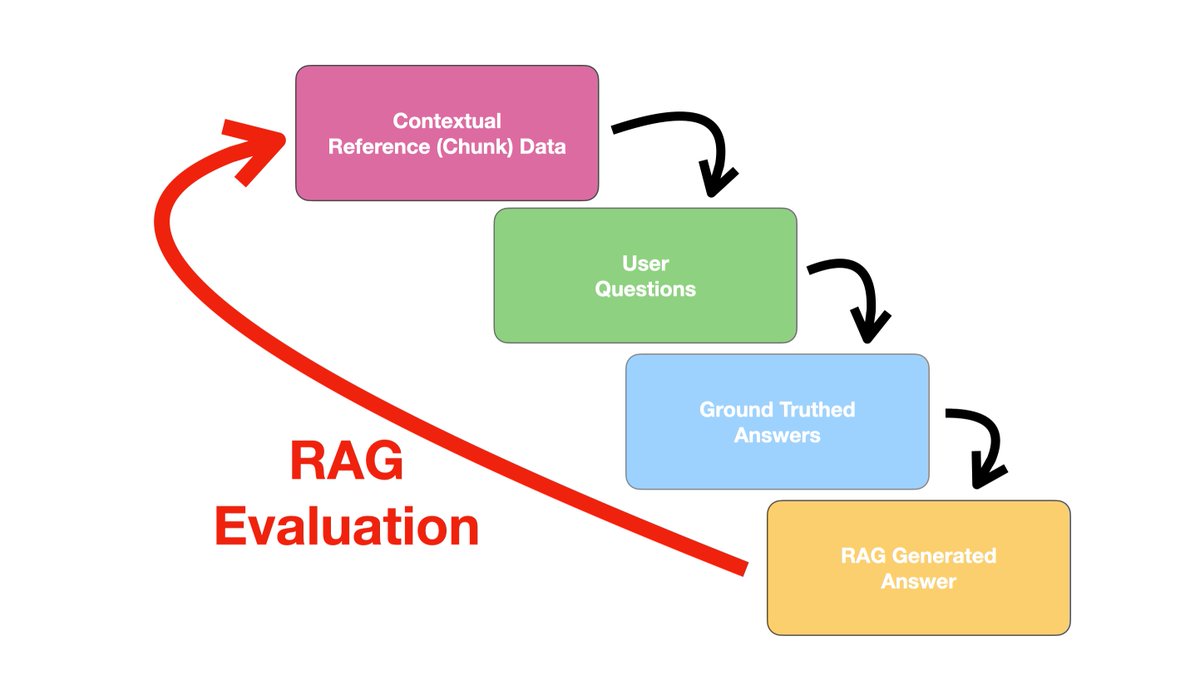
Steps In Evaluating Retrieval Augmented Generation (RAG) Pipelines - The basic principle of RAG is to leverage external data sources. For each user query or question, a contextual chunk of text is retrieved to inject into the prompt. This chunk of text is retrieved based on its…
How to Mitigate LLM Hallucination and Single LLM Vendor Dependancy (Link to the full article in the comments) Four years ago I wrote about the importance of context when developing a chatbot. Context is more relevant now with LLMs than ever before. Injecting prompt with a…
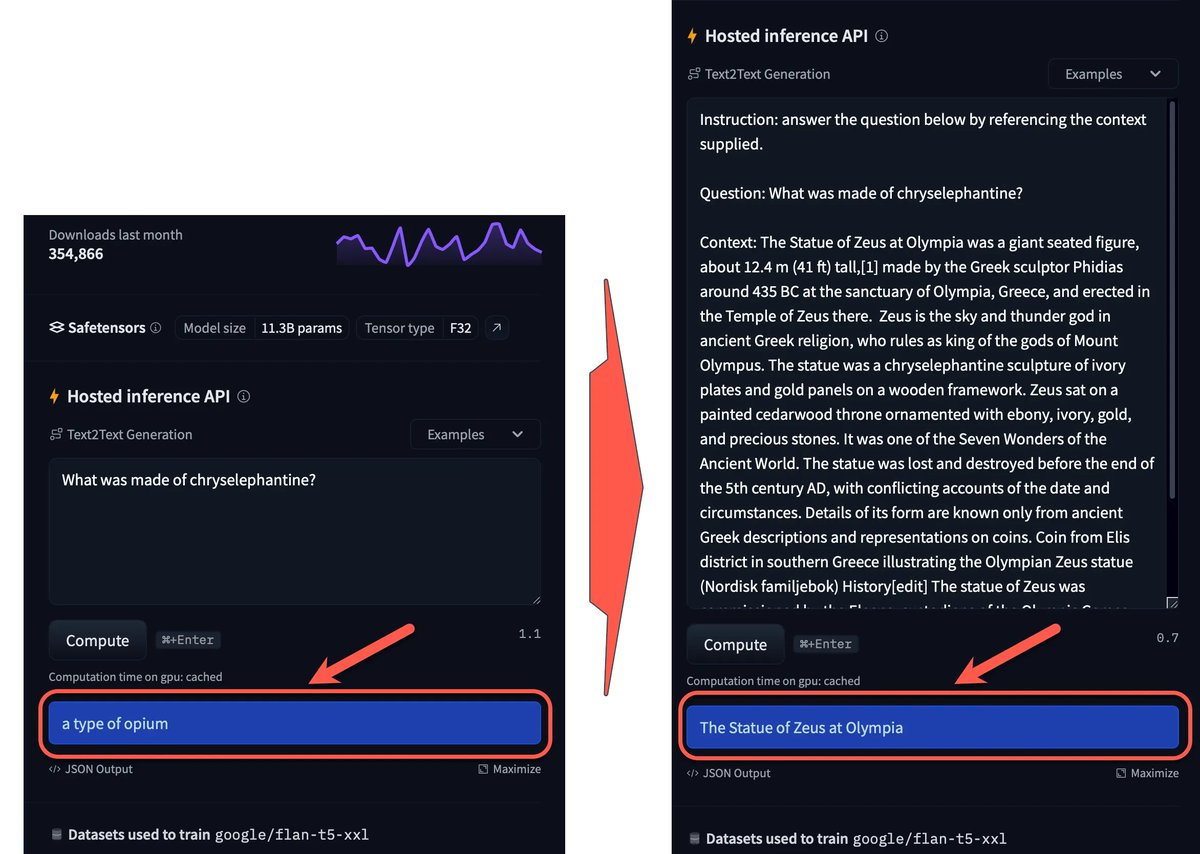
The graph below graphically illustrates how the accuracy improves at the beginning and end of the information entered. And the performance deprecation when referencing data in the middle is also visible.




































































































United States Trendler
- 1. Mamdani 288K posts
- 2. Kandi 4,936 posts
- 3. Mama Joyce 1,377 posts
- 4. #ItsGoodToBeRight N/A
- 5. Aiyuk 1,608 posts
- 6. #HMGxBO7Sweeps 1,513 posts
- 7. Egg Bowl 2,220 posts
- 8. Chance Moore N/A
- 9. Joshua 41.8K posts
- 10. #RHOA 1,843 posts
- 11. #BY9sweepstakes N/A
- 12. Adolis Garcia 2,009 posts
- 13. Putin 211K posts
- 14. Khalifa 45.5K posts
- 15. Richie Saunders N/A
- 16. #AleMeRepresenta N/A
- 17. Wisconsin 8,489 posts
- 18. El Bombi N/A
- 19. Chance Mallory N/A
- 20. Nolan Jones N/A
Bunları beğenebilirsin




Something went wrong.
Something went wrong.