
Mr. L
@JrtheProgrammer
IT #nextworld / Researcher Enthusiast #TheBoringFundamentals

My PhD thesis--On Zero-Shot Reinforcement Learning--is now on arXiv.


The most comprehensive, LLM architecture analysis I've read. Covers every flagship model: 1. DeepSeek V3/R1 2. OLMo 2 3. Gemma 3 4. Mistral Small 3.1 5. Llama 4 6. Qwen3 7. SmolLM3 8. Kimi 2 9. GPT-OSS Great article by @rasbt🙌 Link in the comments 👇 ♻️ Repost if you…


A free book 👇 "Foundations of Lange Language Models" by Tong Xiao and Jingbo Zhu It's good to refresh the core concepts and techniques behind LLMs. This 230-page book covers topics, such as: - Pre-training - Generative models (training, fine-tuning, memory, scaling) -…



Financial Statement Analysis with Large Language Models (LLMs) A 54-page PDF:


1/ With @BenDLaufer and Jon Kleinberg, we constructed the largest dataset of its kind to date: 1.86M Hugging Face models. In a new paper, we mapped how the open-source AI ecosystem evolves by tracing fine-tunes, merges, and more. Here's what we found 🧵

The freshest AI/ML research of the week Our top 9 ▪️ Sotopia-RL: Reward Design for Social Intelligence ▪️ Agent Lightning: Train ANY AI Agents with RL ▪️ Exploitation Is All You Need... for Exploration ▪️ Learning to Reason for Factuality ▪️ VeOmni ▪️ Is Chain-of-Thought…


Been working HRM, had been getting mixed results. AdamAtan2 usage is interesting. Paper covers Sudoku and ARC AGI 1/2. These are essentially step-based grid struct prob. Anyone working w/ HRM & finding other interesting examples? Seen tons of hype, but v few people implementing.


The importance of stupidity in scientific research


Training an LLM on 8 M4 Mac Minis Ethernet interconnect between Macs is 100x slower than NVLink so Macs can’t synchronise model gradients every training step. I got DiLoCo running so Macs synchronise once every 1000 training steps using 1000x less communication than DDP


Most people are still prompting wrong. I've found this framework, which was even shared by OpenAI President Greg Brockman. Here’s how it works:


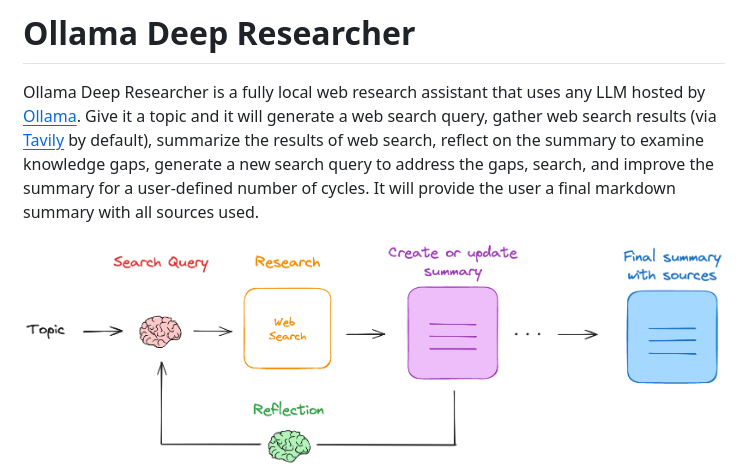
Local Deep Research - A local LLM research assistant that generates follow-up questions and uses DuckDuckGo for web searches - Runs 100% locally with Ollama - Works with Mistral 7B or DeepSeek 14B - Generates structured research reports with sources

my roadmap to learning LLMs - electrons - circuits - logic - transistors - comp arch - CPUs - GPUs - linear algebra - probability - machine learning - optimization - optimizers - tokenization - transformers - pretraining - distributed training - RL - post training - distillation…

You can solve 80% of interview problems about strings with a basic approach. But if the question is tricky, you probably have to think about tries. Tries are unique data structures you can use to represent strings efficiently. This is how to use them: ↓




OpenAI has released a new prompting guide for their reasoning models. It emphasizes simplicity, avoiding chain-of-thought prompts, the use of delimiters, and when to use them. Here’s a breakdown and an optimized prompt to have it write like you:






Financial Statement Analysis with Large Language Models (LLMs) A 54-page PDF:


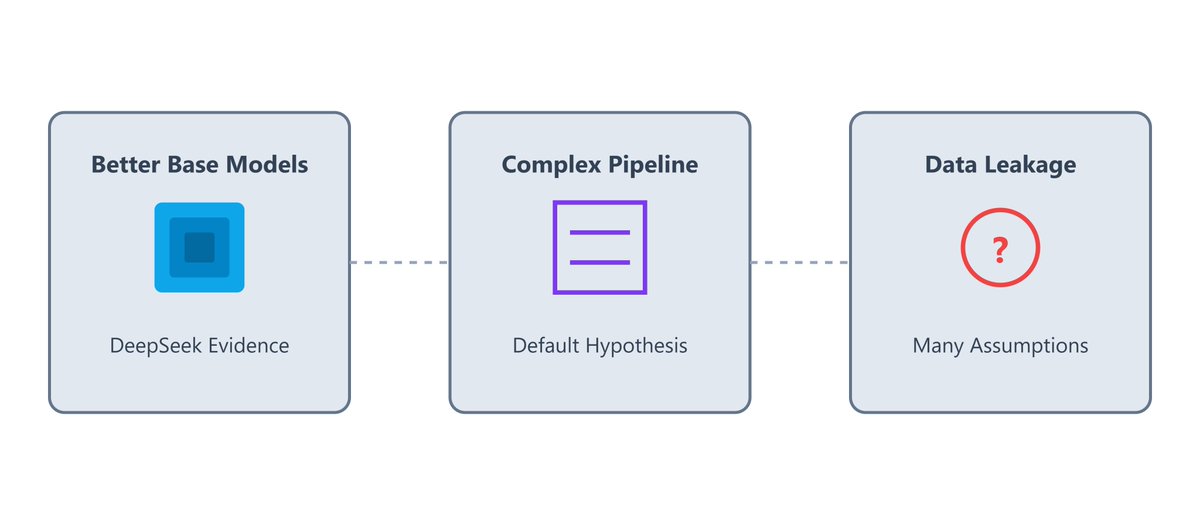
Training LLMs with Reinforcement Learning (RL) isn’t a new idea. So why does it suddenly seem to be working now (o1/DeepSeek)? Here are a few theories and my thoughts on each of them: (1/N)









































































United States Trends
- 1. #เพียงเธอตอนจบ 318K posts
- 2. LINGORM ONLY YOU FINAL EP 333K posts
- 3. Good Friday 52K posts
- 4. #FanCashDropPromotion N/A
- 5. #FridayVibes 5,261 posts
- 6. Ayla 44.4K posts
- 7. Tawan 75.4K posts
- 8. Cuomo 110K posts
- 9. Happy Friyay 1,067 posts
- 10. Justice 338K posts
- 11. Mamdani 261K posts
- 12. Shabbat Shalom 2,382 posts
- 13. #FursuitFriday 12.3K posts
- 14. RED Friday 2,682 posts
- 15. #FridayFeeling 2,242 posts
- 16. Flacco 103K posts
- 17. Finally Friday 2,451 posts
- 18. Dorado 4,264 posts
- 19. New Yorkers 46.2K posts
- 20. Arc Raiders 3,683 posts
Something went wrong.
Something went wrong.