
Pulse
@Pulse__AI
Production-grade unstructured document extraction


Exciting research preview to share on XLSX parsing at @Pulse__AI . Spreadsheets are deceptively hard - merged cells, multi-tab workbooks, and cross-sheet references break when you flatten them. Our team has developed and implemented a token-efficient encoder resulting in…
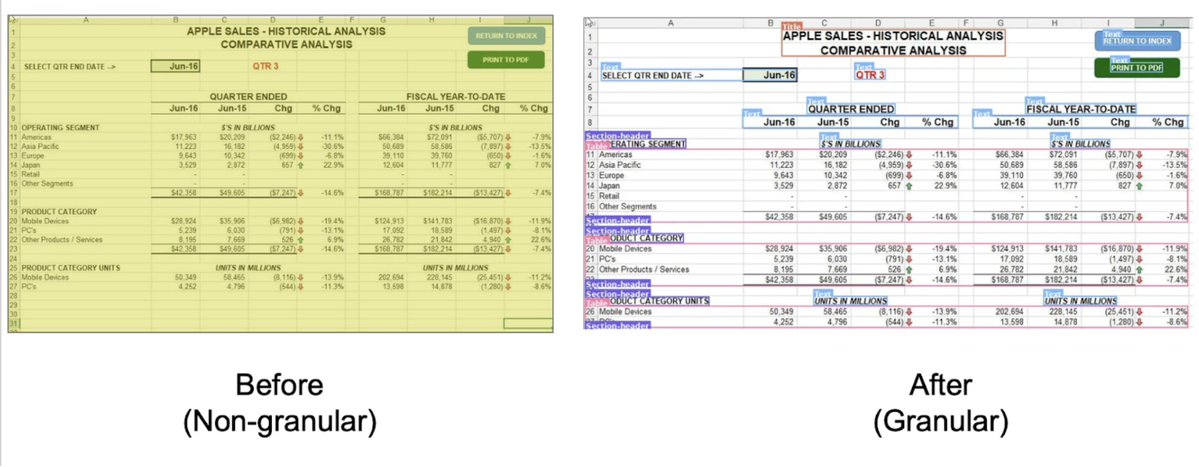
threw a screenshot of this post into @pulse__ai ~99% accurate try it here: platform.runpulse.com


deepseek-ocr can't handle rotated pages, hallucinates badly



DeepSeek AI dropped a new open-source OCR model today 👀 At @pulse__ai, we tested it on financial docs, handwritten forms, and complex tables. The results showed the same issues plaguing LLM-driven OCR: - Unstable outputs - Hallucinated text - Broken table structures Reality…
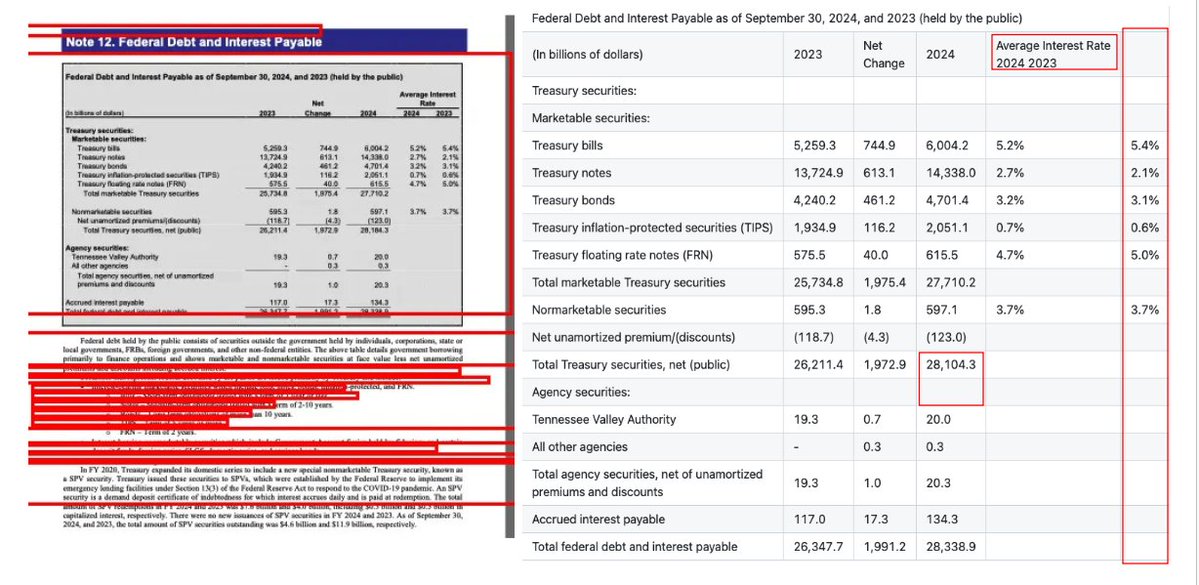

.@Pulse__AI just launched Ultra Nano, their new enterprise-focused document extraction model with complete self-hosting, already running across Fortune 50s, insurers, investment firms, banks, and foundational model labs. runpulse.com/blog/self-host… Congrats on the launch, @sid_mnk…


Pulse is now officially part of @cloudera's Enterprise AI ecosystem. Excited to partner with Cloudera and continue delivering the most accurate document extraction models at enterprise scale.

The @Pulse__AI team just published "The Precision Tax" - why "99% accuracy" fails in finance. One percent error in financial document processing means broken valuations, failed covenant tests, and regulatory exposure. The real benchmark isn't accuracy, it's determinism. Same…

Culture building is everything when you're asking engineers to solve the hardest problems for enterprises. The entire @Pulse__AI team is usually in the office 12 hours a day - everyone needs to be in one place, building together. Having an immediate feedback loop is incredibly…

@pulse__ai just launched formula recognition. trained on 10m+ formula/latex pairs from papers + handwritten notes. traditional ocr breaks on math (α, β, fractions, matrices). our model treats formulas as structured objects → clean latex. built on pulse’s production-grade…


Join us!

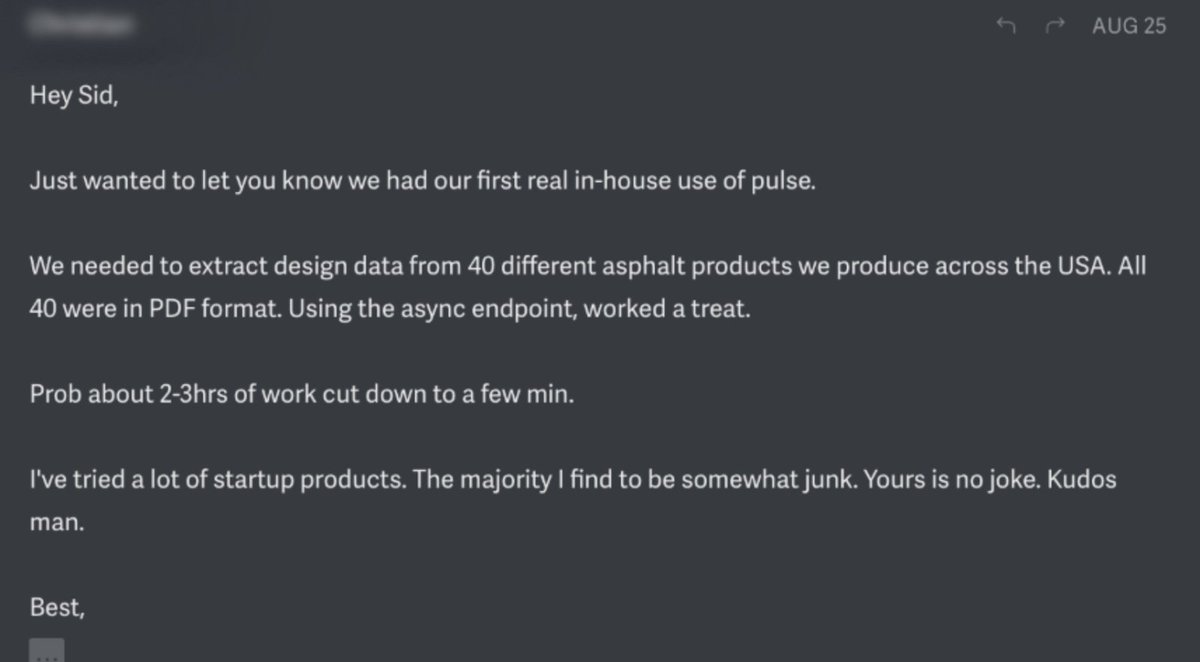
Pulse (@Pulse__AI) just launched their state-of-the-art document extraction platform. It turns complex PDFs, scans, decks, and images into LLM-ready data. No training required. runpulse.com/blog/pulse-ope… Congrats on the launch, @sid_mnk and @ritvikpandey21!
@pulse__ai team just dropped why "98% accurate" document extraction still breaks in production with 4000 errors per 1000 pages. single accuracy scores miss broken reading order, shifted table columns, and lost cross page context that silently corrupt entire datasets. we’ve…

the team at @Pulse__AI put bytedance's dolphin OCR to the test against complex documents that matter for real business use cases. while it shows improvements in reading order detection, we found critical limitations across key areas: - 7.7% structured data extraction from…

we're super excited to be launching Meridian publicly! no more analysts having to manually copy numbers from pdfs into spreadsheets at 2 am before a board deadline if you're interested in trying it out give me a DM! 🫡
Pulse (@Pulse__AI) has just launched Meridian, an AI-powered financial document processor that can automatically convert any PDF, Word doc, PowerPoint presentation, or image into a structured Excel export with charts and graphs. runpulse.com/blog/introduci… Congrats on the launch,…
Pulse (@Pulse__AI) has just launched Meridian, an AI-powered financial document processor that can automatically convert any PDF, Word doc, PowerPoint presentation, or image into a structured Excel export with charts and graphs. runpulse.com/blog/introduci… Congrats on the launch,…
After processing nearly 500M pages, we discovered the biggest challenge in document AI isn't OCR accuracy - it's semantic understanding across page breaks and column boundaries. 🧵 (1/8)

After processing 400M+ pages for the world's largest investment firms, AI startups, and Fortune 500s, @Pulse__AI is launching Ultra: their new hybrid reasoning model. It's the most accurate document extraction model in the industry. Live for all customers today.…

















































United States เทรนด์
- 1. Pat Spencer 2,557 posts
- 2. Chris Paul 3,092 posts
- 3. Kerr 5,408 posts
- 4. Podz 3,219 posts
- 5. Jimmy Butler 2,598 posts
- 6. Shai 15K posts
- 7. Seth Curry 4,555 posts
- 8. Hield 1,559 posts
- 9. Mark Pope 1,925 posts
- 10. #DubNation 1,412 posts
- 11. Carter Hart 3,973 posts
- 12. Derek Dixon 1,273 posts
- 13. Connor Bedard 2,357 posts
- 14. Kuminga 1,431 posts
- 15. Caleb Wilson 1,168 posts
- 16. #SeanCombsTheReckoning 4,553 posts
- 17. #ThunderUp N/A
- 18. Brunson 7,332 posts
- 19. Elden Campbell N/A
- 20. Braylon Mullins N/A
Something went wrong.
Something went wrong.