
Hunyuan
@TencentHunyuan
Tencent's large model, encompasses text generation, image generation, video generation, and 3D generation.
Today, we are open-sourcing Hunyuan World 1.1 (WorldMirror), a universal feed-forward 3D reconstruction model. 🚀🚀🚀 While our previously released Hunyuan World 1.0 (open-sourced, lite version deployable on consumer GPUs) focused on generating 3D worlds from text or…
Impressive! A complete 3D model generated from a single image. Try Hunyuan3D and show us what you create🙌

the fact that this whole 3d model was generated in one shot from an image is completly nuts to me
The training code for Hunyuan World 1.1 (WorldMirror) is released now!🔥🔥🔥 This release provides researchers and developers the full stack for customization and fine-tuning: 📷 Your video to 3D worlds in 1 second. 🪄ANY input (image, video, 3D prior) to ANY output (3DGS,…

1/n) Images → 3D worlds, instantly and locally 🤯 @TencentHunyuan recently open-sourced hunyuan World-Mirror, a model that turns any image or video into a full 3D scene geometry, depth, camera pose, and 3D Gaussian splats, all in a single forward pass.
Hunyuan's latest work: Generating high-quality 3D worlds in 5 seconds with a single GPU. 🔥 Code: github.com/imlixinyang/Fl… Page: imlixinyang.github.io/FlashWorld-Pro…
imlixinyang.github.io
PAPER_TITLE
BRIEF_DESCRIPTION_OF_YOUR_RESEARCH_CONTRIBUTION_AND_FINDINGS

⚡️Generating 3DGS scenes in 5 seconds on a single GPU⚡️ #FlashWorld enables ⚡️*fast*⚡️ (10~100x faster than previous methods) and 🔥*high-quality*🔥 3D world generation, from a single image or text prompt. Code: github.com/imlixinyang/Fl… Page: imlixinyang.github.io/FlashWorld-Pro…

HunyuanImage 3.0 on @replicate passes this test with flying colors. Try it here: replicate.com/tencent/hunyua…


Seedream 4 passed this prompt test pretty well, only missing the tear in the gold backdrop.

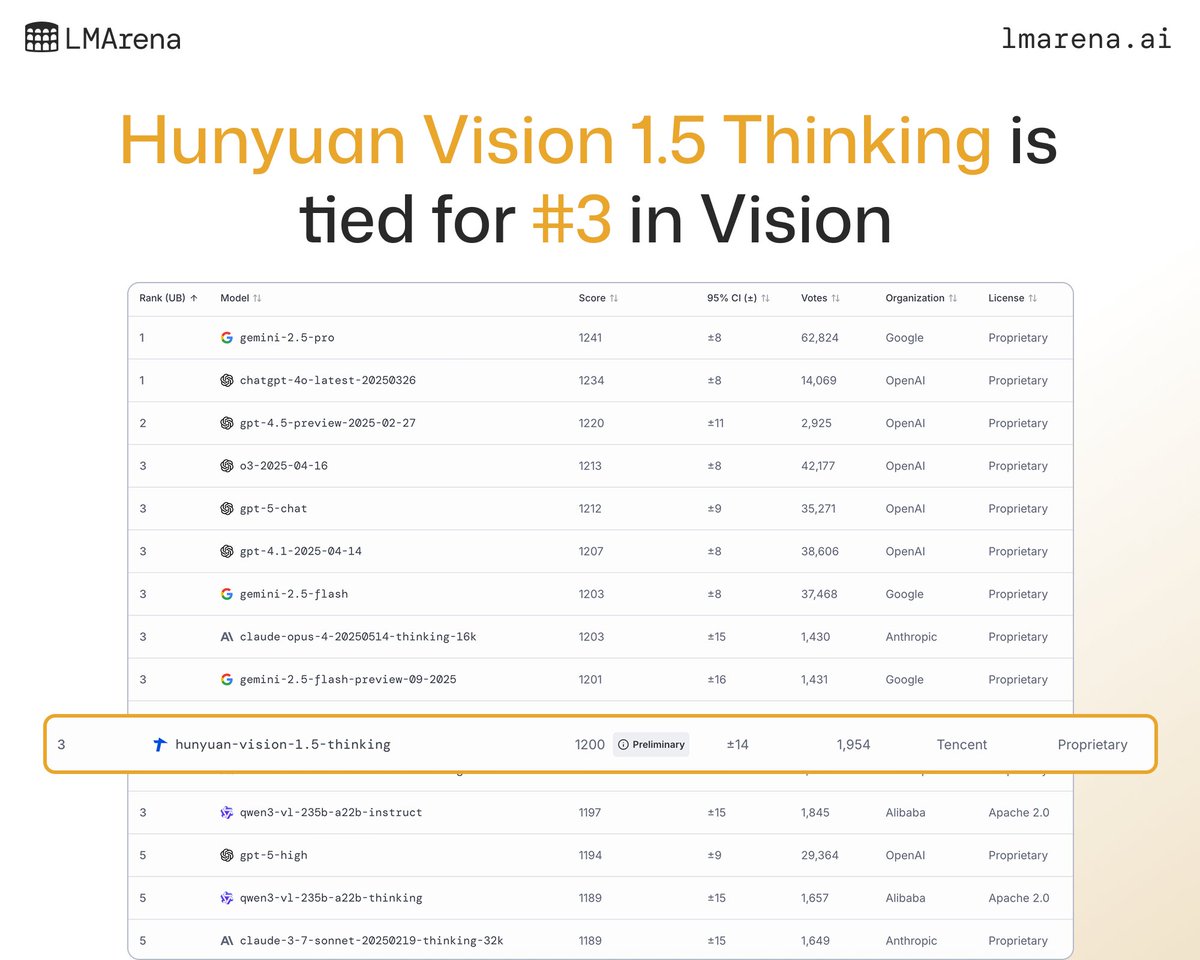
We are excited to introduce Hunyuan-Vision-1.5-Thinking, our latest and most advanced vision-language model. Hunyuan-Vision-1.5-Thinking is ranked No. 3 in @arena, and the model is now available on Tencent Cloud. The model and technical report will be released in late October.…

Hunyuan-Vision-1.5-Thinking is ranked No. 3 in the Arena—the best performing model in China. You're welcome to try our most advanced model on LMArena Direct Chat:lmarena.ai/?mode=direct. Please stay tuned at: github.com/Tencent-Hunyua…

👀 Vision Leaderboard Shakeup New model, Hunyuan Vision 1.5 Thinking by @tencenthunyuan, has entered to tie for #3 in the Vision Arena. Evaluating AI models with vision adds new complexities when compared to text. To perform well a model must extract information from images,…
🥮 We challenged HunyuanImage 3.0 to design creative images for Mid-Autumn Festival, focusing on unique mooncake concepts. These images show the model's advanced rendering power, seamlessly integrating the Tencent Penguin mascot into custom mooncake molds, packaging, and LEGO…




Happy Mid-Autumn Festival! 🌕 Celebrating the festival with a visual feast rendered by HunyuanImage 3.0. 🎨 Wishing everyone a beautiful time of reunion and joy. Build your own festive art with the global text-to-image leader! Try HunyuanImage 3.0 now: hunyuan.tencent.com/image/en?tabIn…




🏆HunyuanImage 3.0 has taken the #1 spot in @arena, ranked as both the top overall and top open-source Text-to-Image model. This achievement came just one week after release and followed a week at the top of Hugging Face trend list. Big thanks to the community for the incredible…
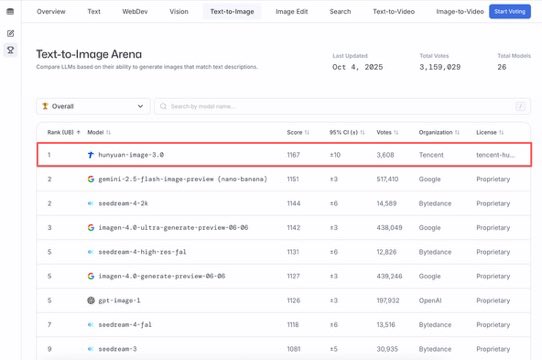
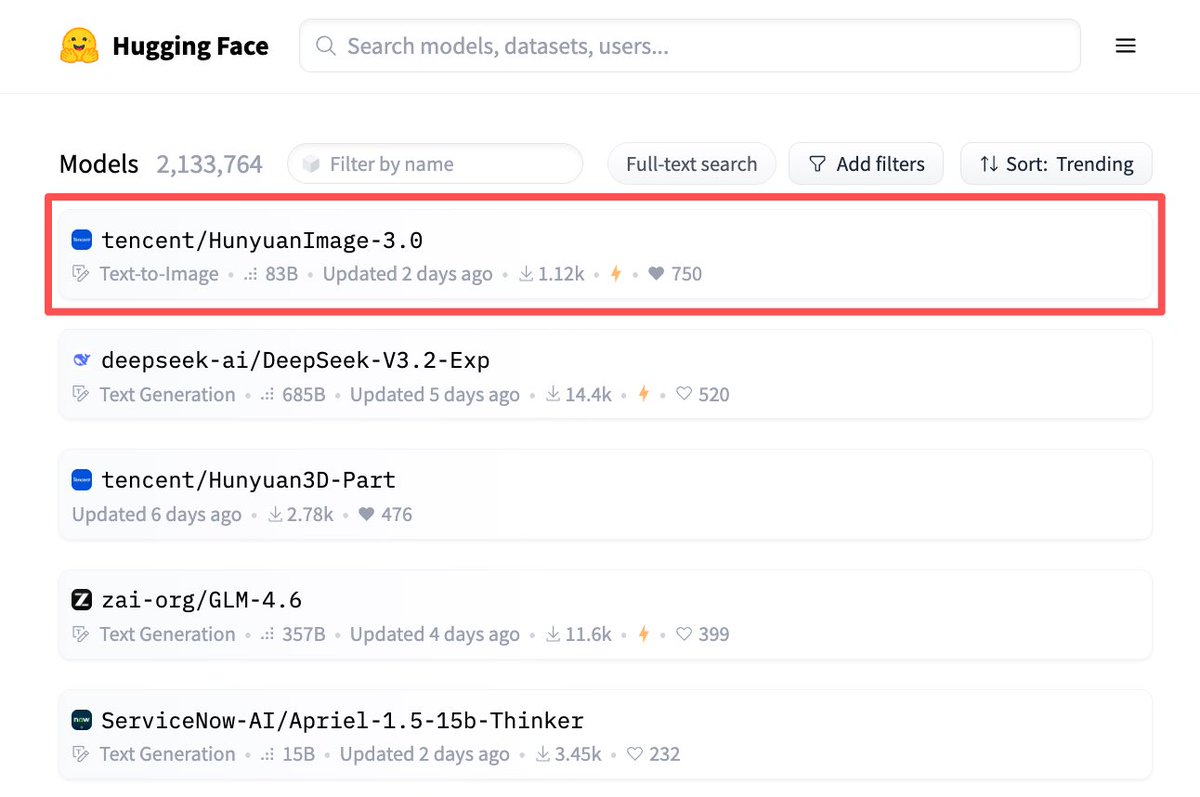
🥇 Just one week after the release, HunyuanImage 3.0 has taken the #1 spot in LMArena, ranked as both the top overall and top open-source Text-to-Image model. We are so grateful for the support from the community! 🙌
🚨 Text-to-Image Leaderboard Shakeup! Hunyuan Image 3.0 by @TencentHunyuan just stormed into the #1 spot in the Arena 🏆 - ranked as both the top overall and top open-source Text-to-Image model. 🖼️ This image generation model has leapfrogged over Seedream 4, and the famous…

We just hit the top of the Hugging Face trend list with two models! 🏆 🔹HunyuanImage 3.0: The largest and most powerful open-source text-to-image model to date with over 80 billion parameters. The performance is comparable to industry flagship closed-source models.…

The creativity flowing from the community is absolutely insane! 🔥🔥🔥We love seeing what you’re making with HunyuanImage 3.0. 🎨 Shout out to @ring_hyacinth @imxiaohu @op7418 @优设AIGC


























































United States Тренды
- 1. #FaithFreedomNigeria 1,087 posts
- 2. Good Wednesday 29.3K posts
- 3. Peggy 23.9K posts
- 4. #wednesdaymotivation 6,327 posts
- 5. #LosVolvieronAEngañar 1,219 posts
- 6. Mega Zeraora 1,745 posts
- 7. Hump Day 13K posts
- 8. #Wednesdayvibe 2,038 posts
- 9. Dearborn 300K posts
- 10. Jessica Tisch N/A
- 11. Happy Hump 8,398 posts
- 12. #hazbinhotelseason2 87.4K posts
- 13. Cory Mills 15.1K posts
- 14. Gettysburg Address N/A
- 15. For God 219K posts
- 16. $TGT 4,341 posts
- 17. LINGORM PRESENTER LAURIER 545K posts
- 18. Abel 17.3K posts
- 19. $NVDA 39.6K posts
- 20. Grayson 7,789 posts
Something went wrong.
Something went wrong.