
InclusionAI
@TheInclusionAI
InclusionAI (IAI) envisions AGI as humanity's shared milestone. See @AntLingAGI model series, and OSS projects like AReaL & AWorld https://discord.gg/2X4zBSz9c6
A remarkable moment on scaling!

🚀 Ring-1T-preview: Deep Thinking, No Waiting The first 1 trillion open-source thinking model -> Early results in natural language: AIME25/92.6, HMMT25/84.5, ARC-AGI-1/50.8, LCB/78.3, CF/94.7 -> Solved IMO25 Q3 in one shot, with partial solutions for Q1/Q2/Q4/Q5 Still evolving!

Ring-flash-linear-2.0 :cost effective ,as fast as flashlight ⚡️
🚀Meet Ring-flash-linear-2.0 & Ring-mini-linear-2.0 --> ultra-fast, SOTA reasoning LLMs with hybrid linear attentions --> 2x faster than same-size MoE & 10x faster than 32B models --> Enhanced with advanced RL methods Try the future of reasoning!

amazing try with our baby moe model, good reason to buy a new iphone 17

Managed to get Ling Mini 16B (1.4B active) running on my iPhone Air. It runs very fast with MLX. It's a DWQ of Ling Mini quantized to 3 bits-per-weight. A 16B model running on an Air at this speed is pretty awesome:
Nice work!We released Ling-flash-2.0, Ring -flash-2.0, you can try more and talk to us.😇

Another demo of the iPhone 17 Pro’s on-device LLM performance This time with Ling mini 2.0 by @TheInclusionAI, a 16B MoE model with 1.4B active parameters running at ~120tk/s Thanks to @awnihannun for the MLX DWQ 2-bit quants

𝘐𝘕𝘊𝘓𝘜𝘚𝘐𝘖𝘕 𝘐𝘚 𝘖𝘕 𝘈 𝘚𝘏𝘐𝘗𝘗𝘐𝘕𝘎 𝘚𝘗𝘙𝘌𝘌 Another addition to the Ring family, Ring-flash-2.0 (100B total, 6.1B active) is a high-performance thinking model built on Ling-flash-2.0-base, tuned with Long-CoT SFT, RLVR, and RLHF, and designed to tackle a core…

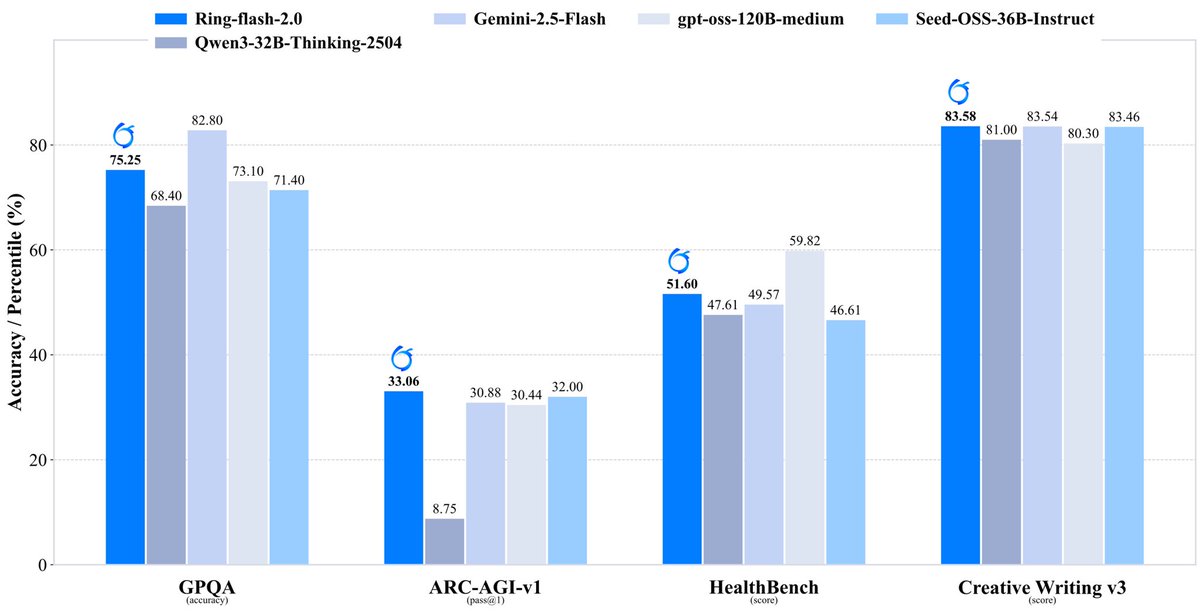


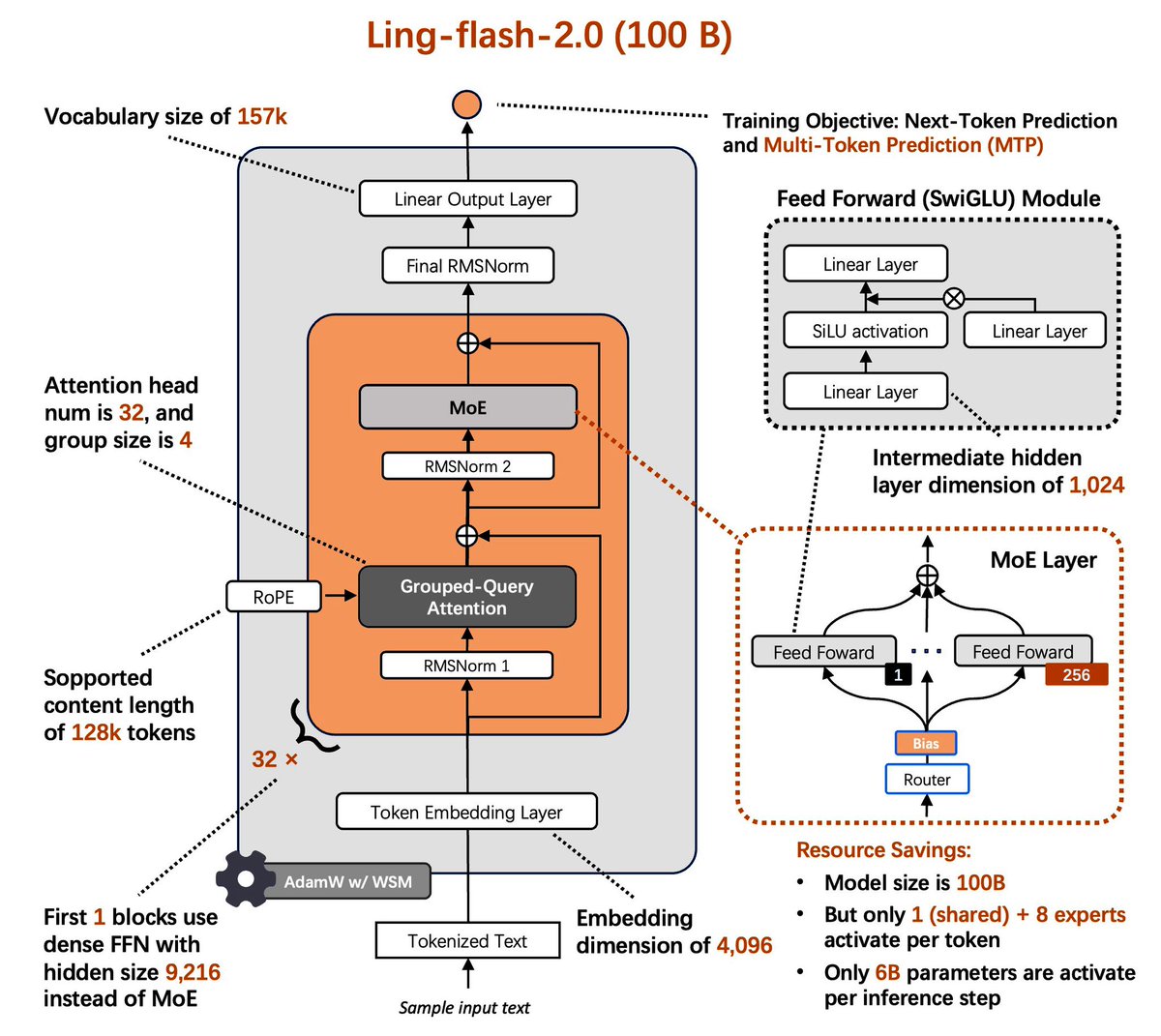
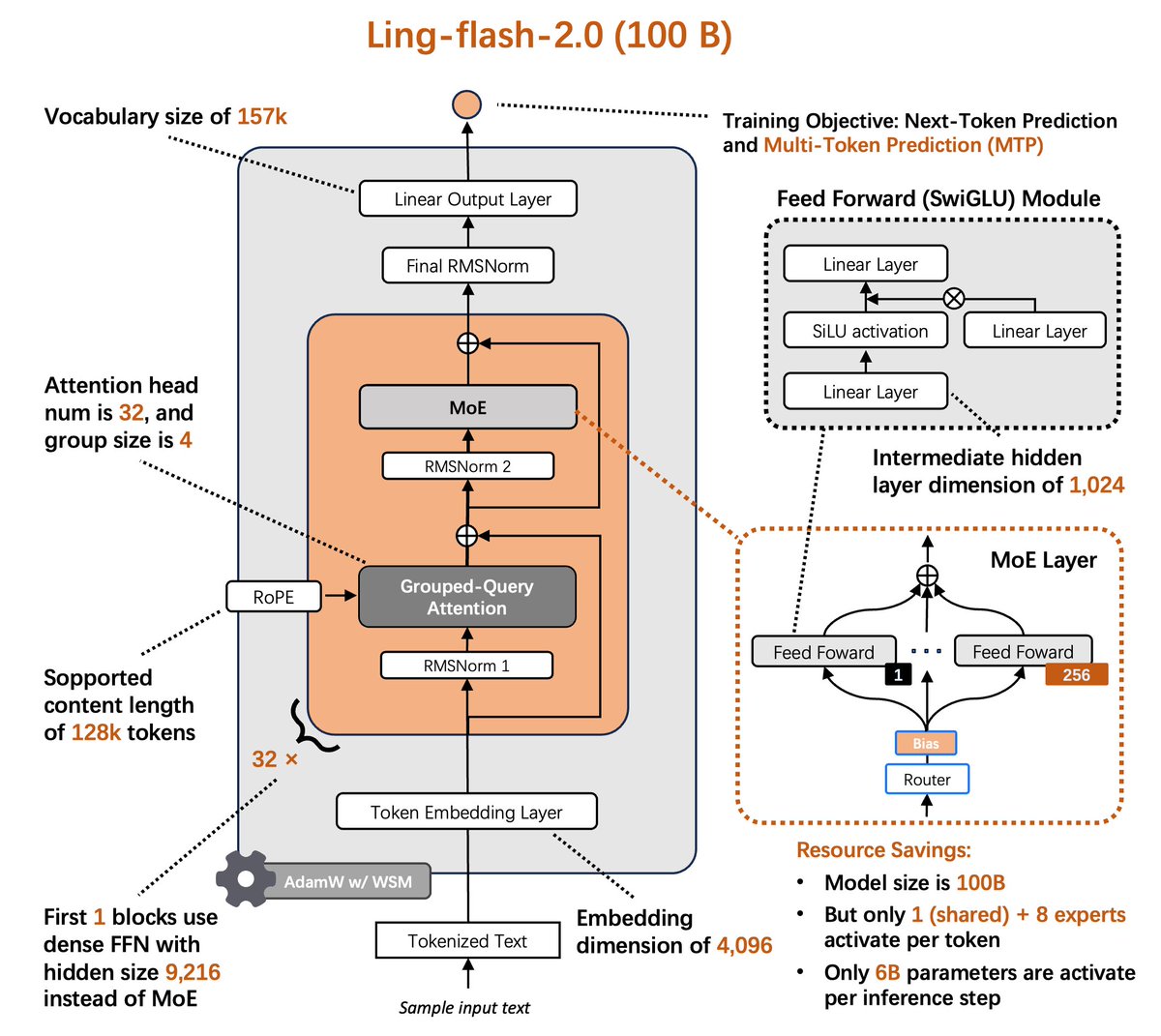
Ling-flash-2.0 (100B total, 6.1B active) is the third MoE model in the Ling 2.0 family, now open-sourced. Trained on 20T+ tokens with supervised fine-tuning and multi-stage reinforcement learning, it adopts a 1/32 activation-ratio architecture with sigmoid routing, MTP, QK-Norm,…

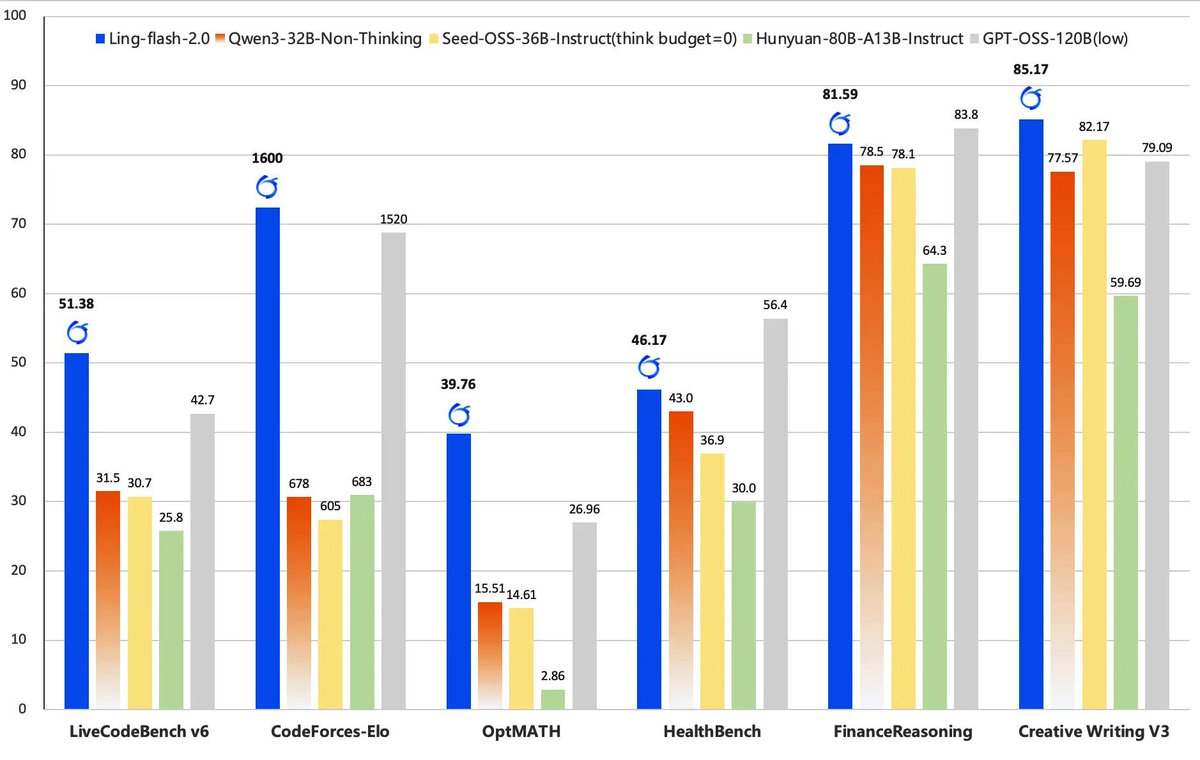

🚀🚀🚀 Ring-flash-2.0 shows a new breakthrough about Long-CoT RL traning on MoE models.
We open-source Ring-flash-2.0 — the thinking version of Ling-flash-2.0. --> SOTA reasoning in math, code, logic & beyond. --> 100B-A6B, 200+ tok/s on 4×H20 GPUs. --> Powered by "icepop"🧊, solving RL instability in MoE LLMs.


Small activation,big performance, significant milestone of MoE LLM.🚀🚀🚀
⚡️Ling-flash-2.0⚡️ is now open source. 100B MoE LLM • only 6.1B active params --> 3x faster than 36B dense (200+ tok/s on H20) --> Beats ~40B dense LLM on complex reasoning --> Powerful coding and frontend development Small activation. Big performance.



AQ Med AI team says hi to everyone!👋🏻 We’re on a mission to bring more MedAI breakthroughs to the world. 🦾 We invite all researchers, developers, and Med AI geeks to join us on this journey, transforming cutting-edge research into real-world impact. 🚀💥 🔗 GitHub, HuggingFace,…

cool

More reasoning work will coming soon🚀
Inclusion AI follows up on Ling-2.0 with a reasoning-oriented release: Ring-mini-2.0 (16.8B total / 1.4B active) - Built on Ling-mini-2.0 - Long-CoT SFT, stable RLVR, RLHF - 128K context, 500 tok/s on a single H20 (dual streaming, routed and shared experts) - Excels in logic,…





Yes !

Ring-mini-2.0 🔥 Latest reasoning model by @InclusionAI666 @AntLing20041208 huggingface.co/inclusionAI/Ri… ✨ 16B/1.4B active - MIT license ✨ Trained on 20T tokens of high-quality data ✨ 128K context length ✨ Reasoning with CoT + RL

🚀🚀🚀🧠🧠🧠
🔥 Exciting release! We’re open-sourcing **Ring-mini-2.0**, a powerful yet lightweight 16B-A1B thinking model! 💡 Trained with a novel stable RLVR + RLHF strategy to achieve balanced and robust performance across tasks. 🧠 Outperforms similar-scale dense models in logical…

🚀🚀🚀
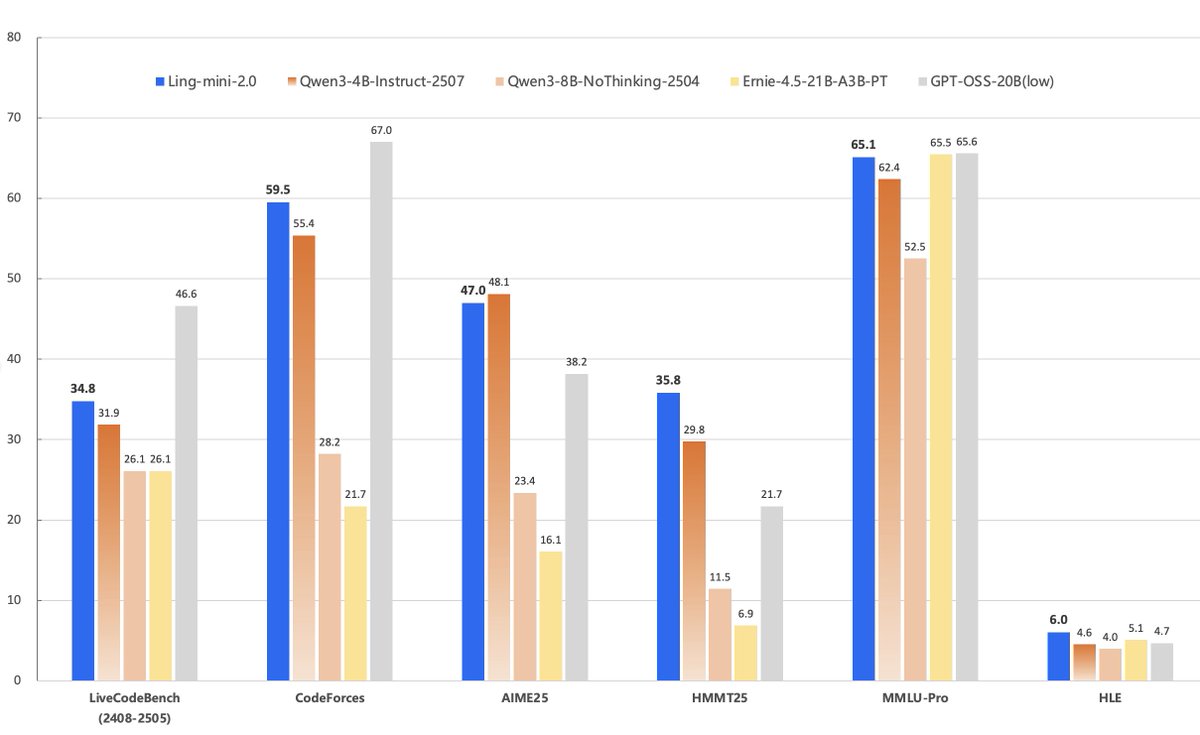
🚀 Open-sourcing Ling-mini-2.0 — 16B-A1B MoE LLM.💻Trained on 20T+ tokens w/ SFT + RLVR + RLHF. ⚡ 300+ tok/s (7× faster vs dense). 📦 Open source FP8 training + 4 pretrain CKPTs 👉 Ideal starting point for small-size MoE LLM research & application. 🤗huggingface.co/inclusionAI/Li…
Inclusion AI's AWorld introduces a comprehensive end-to-end agentic learning method, talk to authors.@gujinjie @zhuangchenyi

















































United States Trends
- 1. Auburn 46K posts
- 2. Brewers 65.2K posts
- 3. Georgia 67.9K posts
- 4. Cubs 56.4K posts
- 5. Utah 25.2K posts
- 6. Gilligan 6,112 posts
- 7. #byucpl N/A
- 8. Kirby 24.2K posts
- 9. Arizona 41.7K posts
- 10. #SEVENTEEN_NEW_IN_TACOMA 32.1K posts
- 11. Wordle 1,576 X N/A
- 12. #AcexRedbull 4,164 posts
- 13. Michigan 62.8K posts
- 14. #Toonami 2,981 posts
- 15. #BYUFootball 1,017 posts
- 16. Boots 50.6K posts
- 17. Hugh Freeze 3,271 posts
- 18. mingyu 87.1K posts
- 19. Amy Poehler 4,875 posts
- 20. Holy War 2,209 posts
Something went wrong.
Something went wrong.