
You might like









VLM embeddings for complex documents is so refreshing and we need better benchmarks! Thank you for this work!

📢 ViDoRe V3, our new multimodal retrieval benchmark for enterprise use cases, is finally here! It focuses on real-world applied RAG scenarios using high-quality human-verified data. huggingface.co/blog/QuentinJG… 🧵(1/N)


Most OCR benchmarks optimize for text similarity, but a document can be 99% "correct" and still be 100% useless. Unfortunately, these benchmarks overlook the real issues that happen in production. I'm linking to a report here. It challenges how the entire industry measures the…


hate to say it.... but i regret building this backend in python. shoulda gone ts all the way.

Context Engineering 2.0 This report discusses the context of context engineering and examines key design considerations for its practice. Explosion of intelligence will lead to greater context-processing capabilities, so it's important to build for the future too. This aligns…


grad's tweets are full of alpha! highly recommend to read this one.



How to get Claude code output top-tier UI? 👇 This is my 3-step process to turn Claude code into design mode


And we are out! 🚀🚀🚀

Introducing MagicPath, an infinite canvas to create, refine, and explore with AI. Create beautiful components and functional apps, while providing production ready code. Available today, free, for everyone. The Cursor moment for design is here.

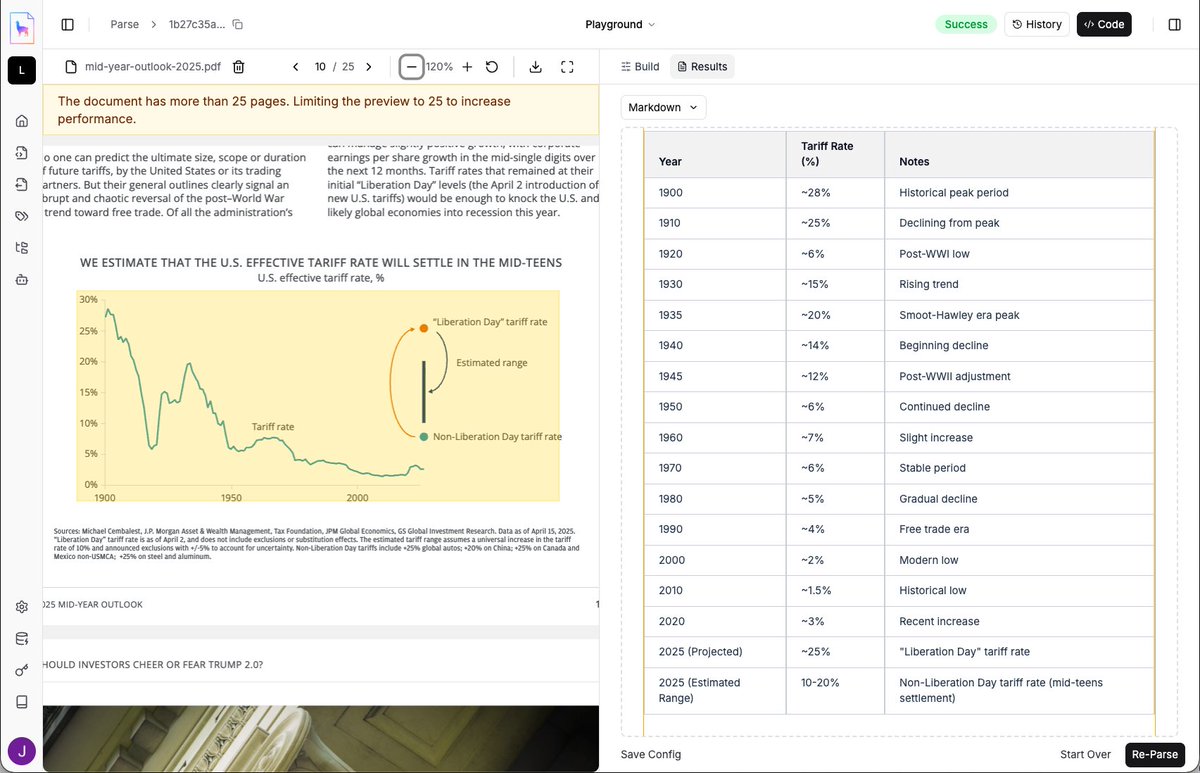
An unsolved problem for document OCR is chart understanding, and most LLMs aren’t very good at direct conversion to numbers. We’ve created an experimental “agentic chart parsing” model/algorithm 📈🧪 that is able to best-effort understand the precise values of each value in a…



This OCR model was probably the best one with the least hype Awesome release with both a serverless API and open models on @huggingface The org only has 85 followers on the hub ?!

Last week we launched Chandra, the newest model in our OCR family 🚀 Despite a busy week for OCR releases, it topped independent benchmarks and received incredible community feedback.


Hot take: DAgger (Ross 2011) should be the first paper you read to get into RL, instead of Sutton's book. Maybe also read scheduled sampling (Bengio 2015). And before RL, study supervised learning thoroughly.



Training LLMs end to end is hard. Very excited to share our new blog (book?) that cover the full pipeline: pre-training, post-training and infra. 200+ pages of what worked, what didn’t, and how to make it run reliably huggingface.co/spaces/Hugging…


thank god i’m unemployed so i can take a break from learning cuda & just read this banger hehe

Training LLMs end to end is hard. Very excited to share our new blog (book?) that cover the full pipeline: pre-training, post-training and infra. 200+ pages of what worked, what didn’t, and how to make it run reliably huggingface.co/spaces/Hugging…

We just built and released the largest dataset for supervised fine-tuning of agentic LMs, 1.27M trajectories (~36B tokens)! Up until now, large-scale SFT for agents is rare - not for lack of data, but because of fragmentation across heterogeneous formats, tools, and interfaces.…

Reinforcement Learning of Large Language Models, Spring 2025(UCLA) Great set of new lectures on reinforcement learning of LLMs. Covers a wide range of topics related to RLxLLMs such as basics/foundations, test-time compute, RLHF, and RL with verifiable rewards(RLVR).



wow, only if there was rl algorithms that had (self) distillation term for reverse kld. that everyone trying to remove tldr: replace pi_ref with pi_teacher you get on policy distillation


Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…
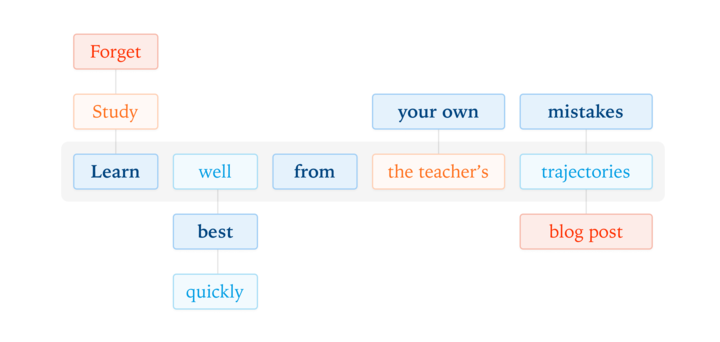

elanapearl.github.io/blog/2025/the-… it's a debugging detective story where you follow along the reasoning behind each step and solve it as we go it also explains ML & PyTorch concepts as they become necessary to understand what's breaking, why, and how to fix it🔎

zhihu is a really good site. lots of hidden alpha + deep dives.


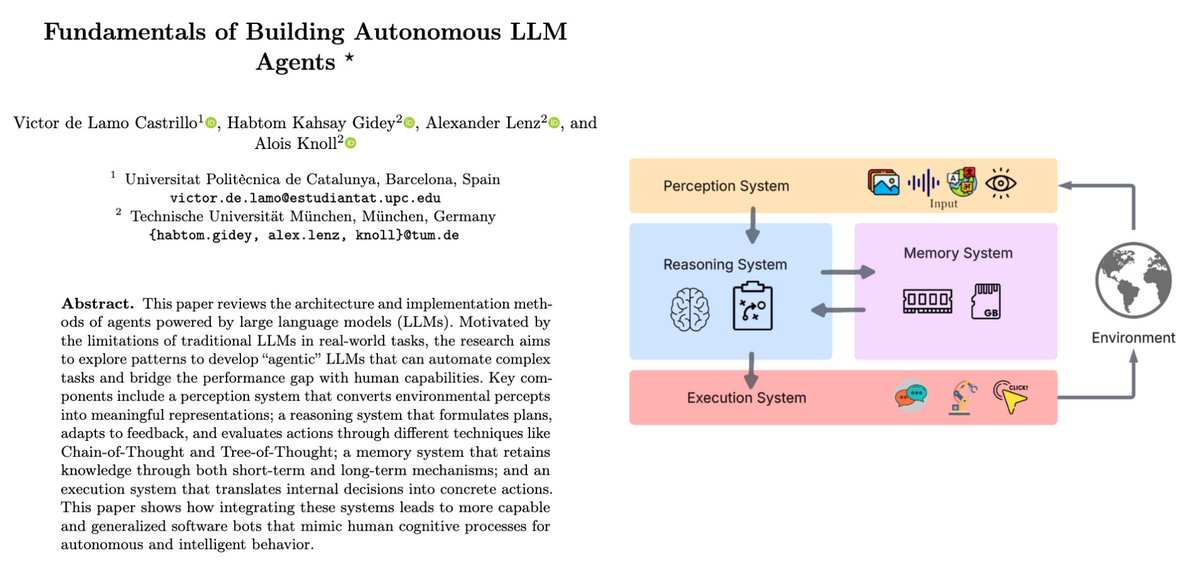
🤖 I finally understand the fundamentals of building real AI agents. This new paper “Fundamentals of Building Autonomous LLM Agents” breaks it down so clearly it feels like a blueprint for digital minds. Turns out, true autonomy isn’t about bigger models. It’s about giving an…

































































United States Trends
- 1. #CARTMANCOIN 1,717 posts
- 2. Broncos 66.1K posts
- 3. yeonjun 218K posts
- 4. Raiders 66.4K posts
- 5. Bo Nix 18.2K posts
- 6. Geno 18.7K posts
- 7. Sean Payton 4,787 posts
- 8. daniela 45.5K posts
- 9. #criticalrolespoilers 5,014 posts
- 10. #TNFonPrime 4,032 posts
- 11. Kenny Pickett 1,508 posts
- 12. Kehlani 9,576 posts
- 13. Jalen Green 7,601 posts
- 14. Chip Kelly 1,983 posts
- 15. Pete Carroll 1,974 posts
- 16. Bradley Beal 3,549 posts
- 17. TALK TO YOU OUT NOW 27.4K posts
- 18. #Pluribus 2,717 posts
- 19. byers 30K posts
- 20. Tammy Faye 1,309 posts








Something went wrong.
Something went wrong.