
내가 좋아할 만한 콘텐츠















Build your entire AI workflow inside Azure Azure Blob Storage is now a supported Unstructured destination! Ship structured, GenAI-ready outputs directly into your Azure environment and unlock: - End-to-end ETL in Azure with minimal setup and zero connector maintenance -…
How do you keep your RAG up to date when your source documents are constantly changing? Most parsers make you reprocess everything, and that can quickly break the bank. With Unstructured’s pipelines you can: • Detect new/modified files • Skip processing unchanged files • Cut…
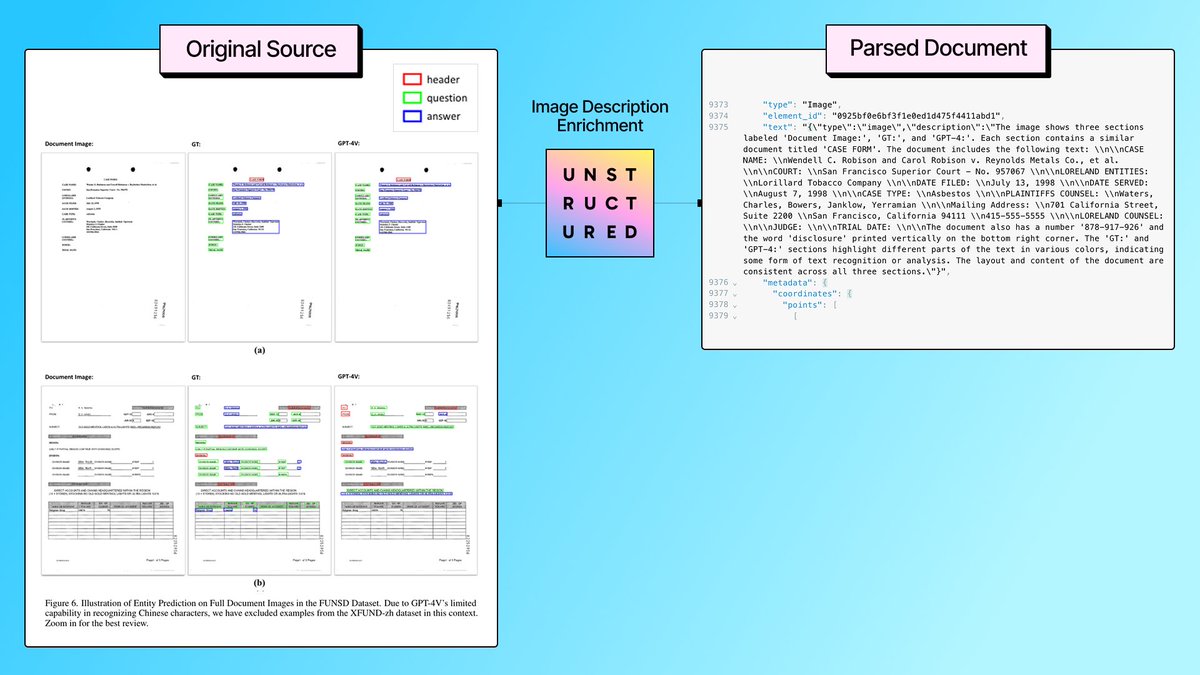
Struggling to make sense of a chart or graph? Your chatbots hit that same wall - unless they’ve got Unstructured! 🤓 Unstructured’s image description enrichment can serve as a “first take” on these kinds of graphs and charts (and other image types as well). We send the images to…






























































































United States 트렌드
- 1. Spotify 1.07M posts
- 2. Chris Paul 28.9K posts
- 3. Clippers 41.3K posts
- 4. Hartline 10.3K posts
- 5. Henry Cuellar 5,707 posts
- 6. #HappyBirthdayJin 102K posts
- 7. ethan hawke 4,160 posts
- 8. GreetEat Corp 1,168 posts
- 9. David Corenswet 7,008 posts
- 10. Jonathan Bailey 8,288 posts
- 11. South Florida 6,115 posts
- 12. #NSD26 25.1K posts
- 13. Apple Music 247K posts
- 14. Chris Henry 2,233 posts
- 15. Klein 16.4K posts
- 16. #JINDAY 80.6K posts
- 17. Nashville 33.4K posts
- 18. Adam Sandler 4,842 posts
- 19. #OurSuperMoonJin 81.3K posts
- 20. Ty Lue 1,440 posts
내가 좋아할 만한 콘텐츠
-
 Prem
Prem
@premai_io -
 LangChain
LangChain
@LangChainAI -
 LlamaIndex 🦙
LlamaIndex 🦙
@llama_index -
 FlowiseAI
FlowiseAI
@FlowiseAI -
 Jerry Liu
Jerry Liu
@jerryjliu0 -
 Harrison Chase
Harrison Chase
@hwchase17 -
 Please AI
Please AI
@PleasePlatforms -
 PromptLayer
PromptLayer
@promptlayer -
 Activeloop
Activeloop
@activeloopai -
 Lance Martin
Lance Martin
@RLanceMartin -
 Greg Kamradt
Greg Kamradt
@GregKamradt -
 Nils Reimers
Nils Reimers
@Nils_Reimers -
 Qdrant
Qdrant
@qdrant_engine -
 Mendable
Mendable
@mendableai -
 Misbah Syed
Misbah Syed
@MisbahSy
Something went wrong.
Something went wrong.