
Vector
@Vector434852
Built a 1-layer O(n) model that reached 5.5 Val PPL on TinyStories / 8.5M params · trained on a 4060 laptop .
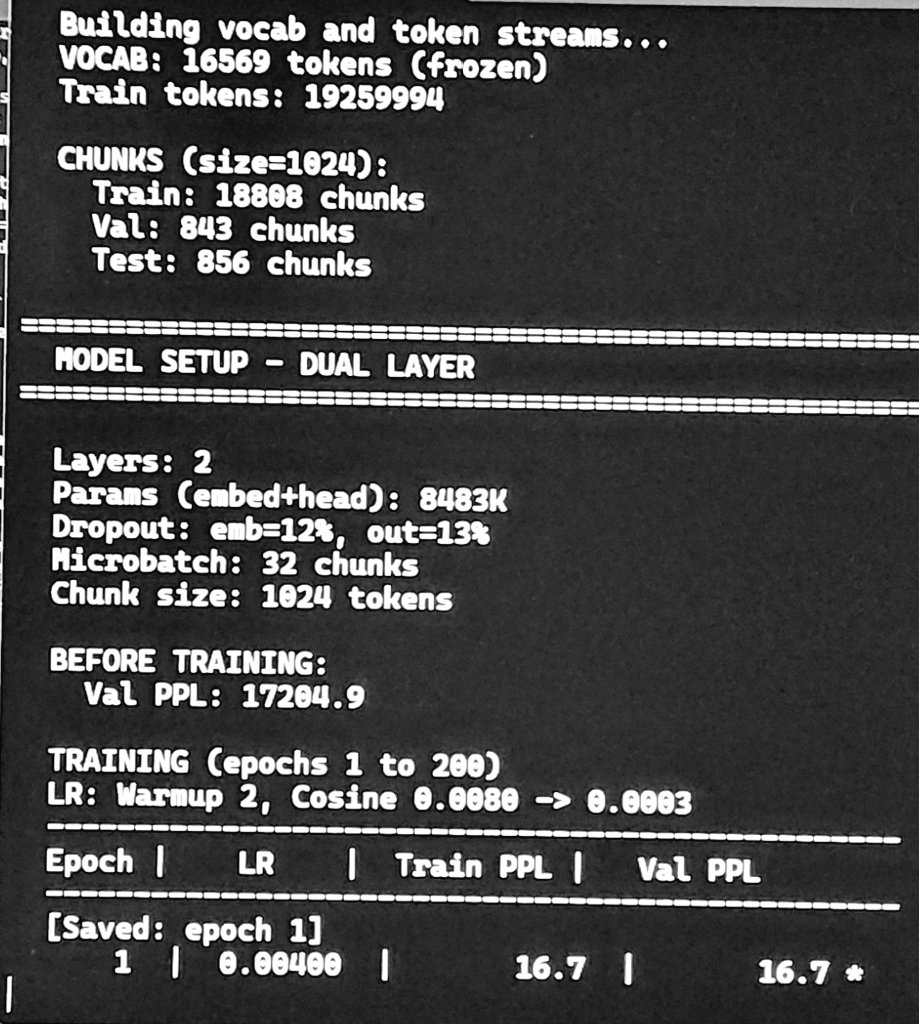
Optimizing my custom O(n) model.. val ppl 16.7 @ 1°epoch is fair .. 37 mins / epoch on rtx4060 laptop #LocalLLM #SmallModels #AI #MachineLearning #RTX4060 #FromScratch
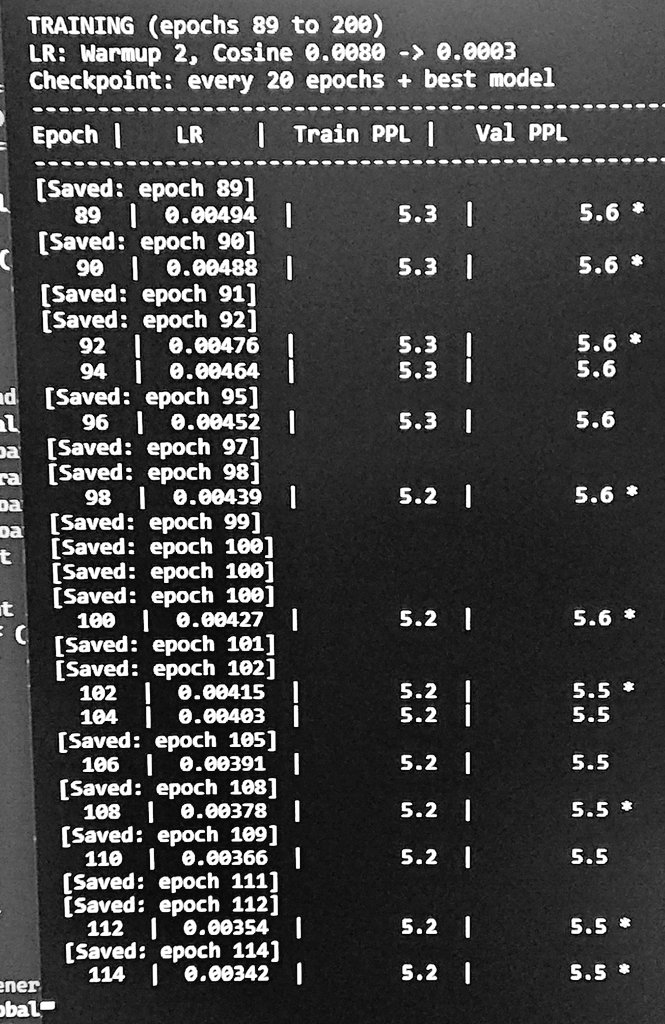
8.5M params . 1 layer of custom O(n) attention on rtx4060 laptop . Val PPL 5.5 (still decreasing) on Tinystories.
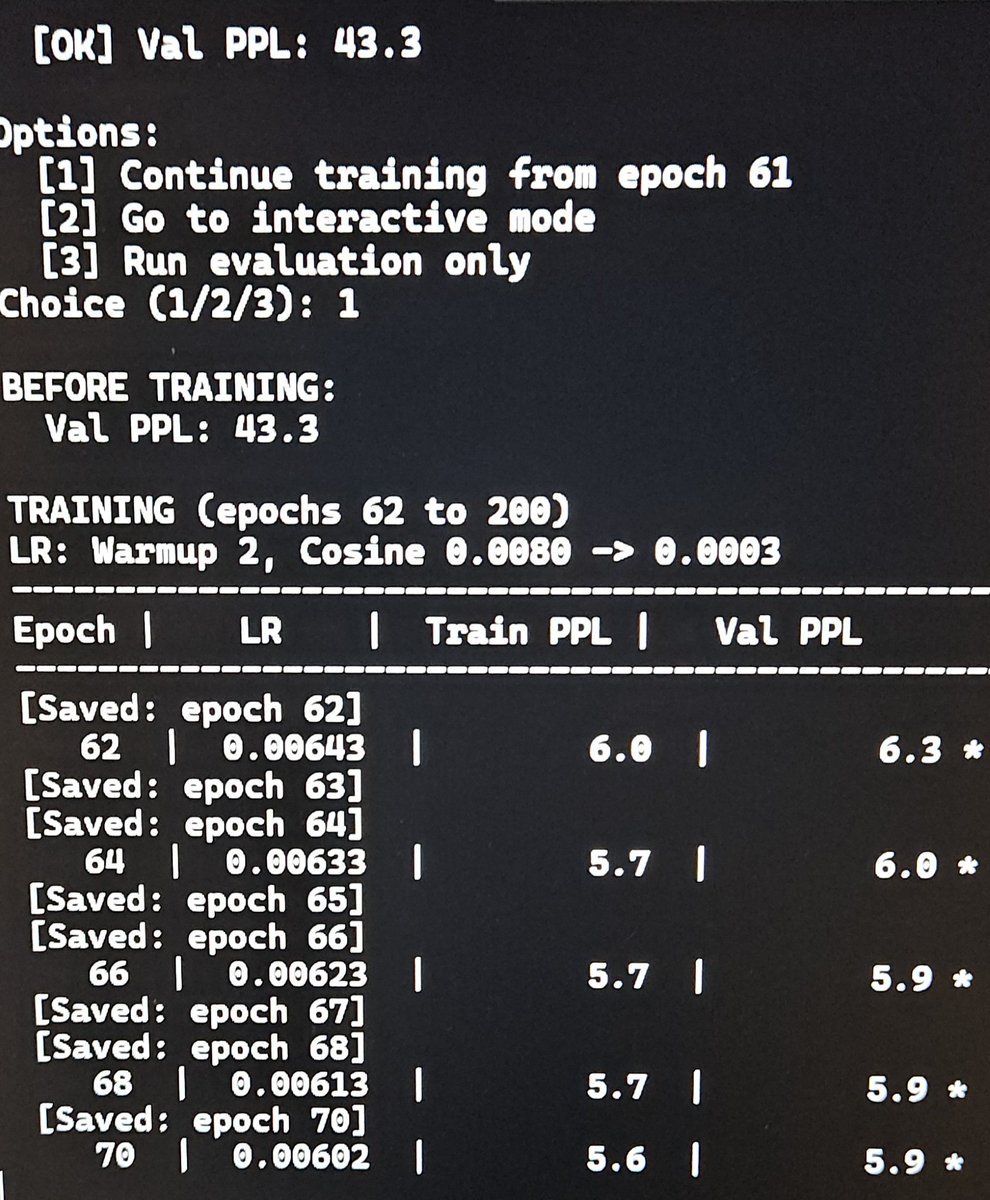
I'm working on a new breed of linear attention. 1 single layer reached PPL 6.5 in 30 epochs on a rtx4060 laptop.. more to come :)
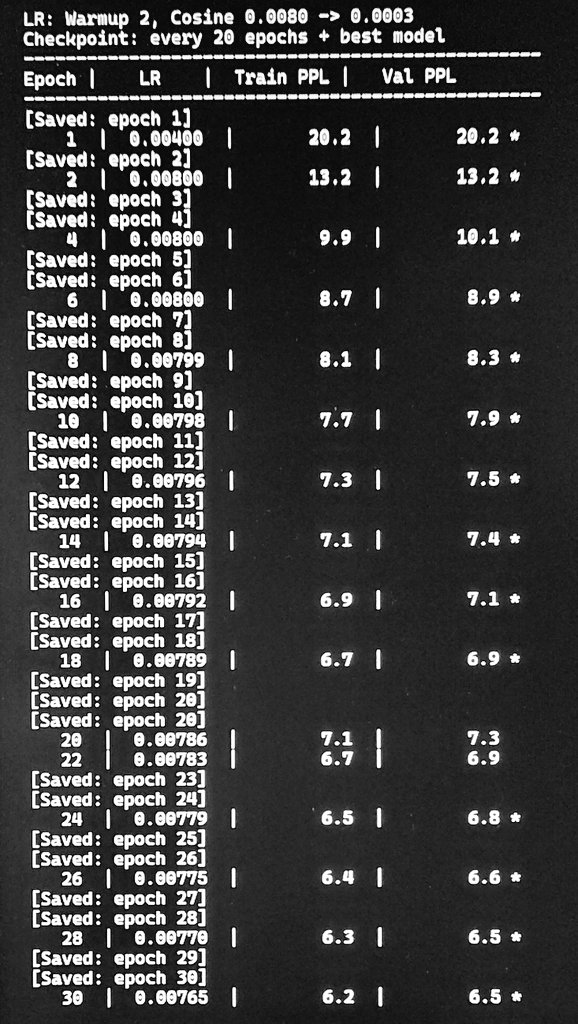
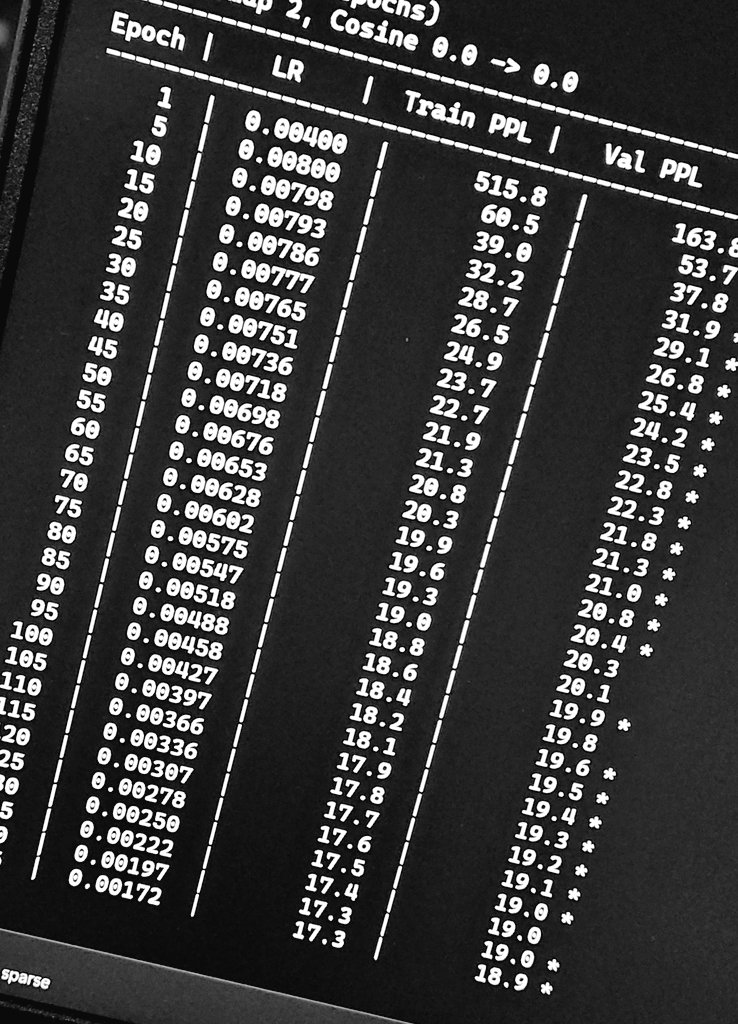
Built a new O(n) attention from scratch. Not Transformer / LSTM / Mamba. Single layer, 8.5M params, RTX 4060 laptop. TinyStories: Val PPL 18.6 | Test PPL 18.9 Context 2048 GPT-2 small needs ~124M params for similar PPL. ~15× parameter efficiency. @ylecun @karpathy Logs ↓

8.5M params 1 layer O(n) attention chunk=2048 RTX 4060 laptop ~72h training TinyStories val PPL: 18.9 (still dropping) No transformers were harmed. log ↓


































United States Trends
- 1. Seahawks N/A
- 2. Seahawks N/A
- 3. Stafford N/A
- 4. Woolen N/A
- 5. Vikings N/A
- 6. McVay N/A
- 7. Pats N/A
- 8. Puka N/A
- 9. #NFCChampionship N/A
- 10. #RHOP N/A
- 11. #LARvsSEA N/A
- 12. Cooper Kupp N/A
- 13. Xavier Smith N/A
- 14. Tom Brady N/A
- 15. Mike Macdonald N/A
- 16. #NFLPlayoffs N/A
- 17. Broncos N/A
- 18. Kenneth Walker N/A
- 19. Witherspoon N/A
- 20. Demarcus Lawrence N/A
Something went wrong.
Something went wrong.