
Overthinking is quietly becoming the biggest hidden cost in LLM deployment. Yuan3.0 Flash tackles this with RAPO + RIRM — not by forcing shorter outputs, but by teaching models when to stop thinking. 📷Explore now: github.com/Yuan-lab-LLM/Y… ✨ What’s different: ✅ RIRM…
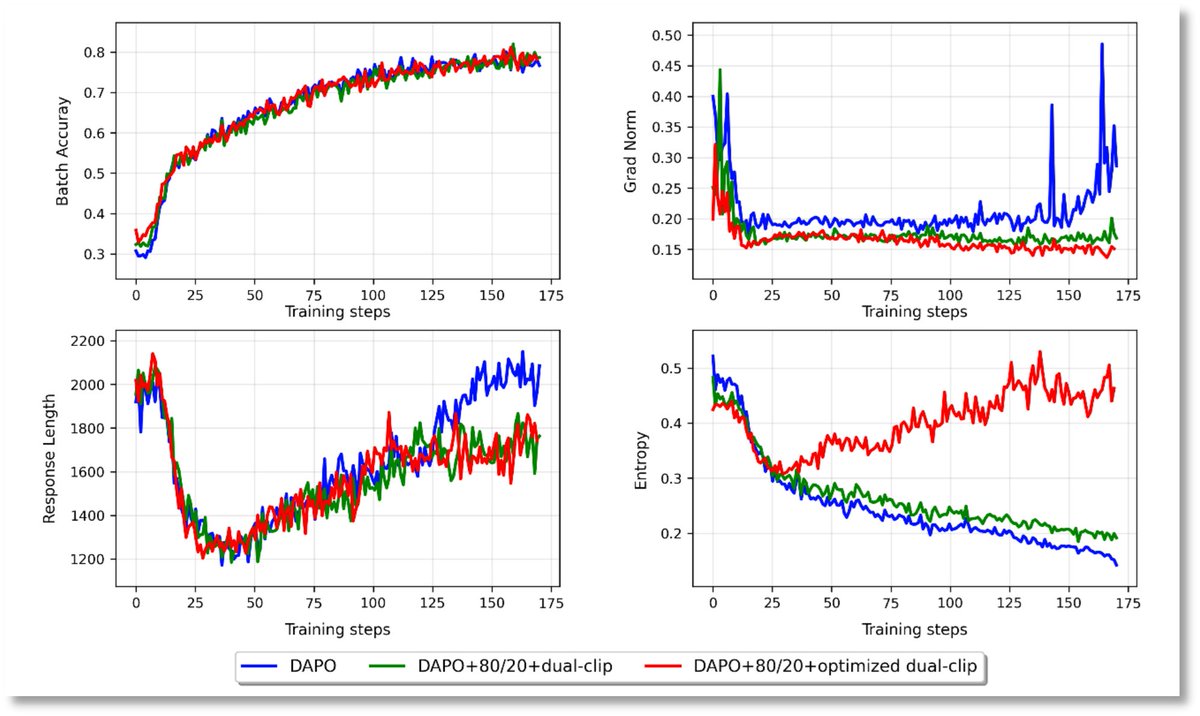
AI large #model overthinks—even after nailing the right answer? No more redundant verification without new evidence. Yuan3.0 Flash’s RIRM (Reflection Inhibition Reward Mechanism) is the breakthrough method that holds models accountable not just for getting answers right, but for…
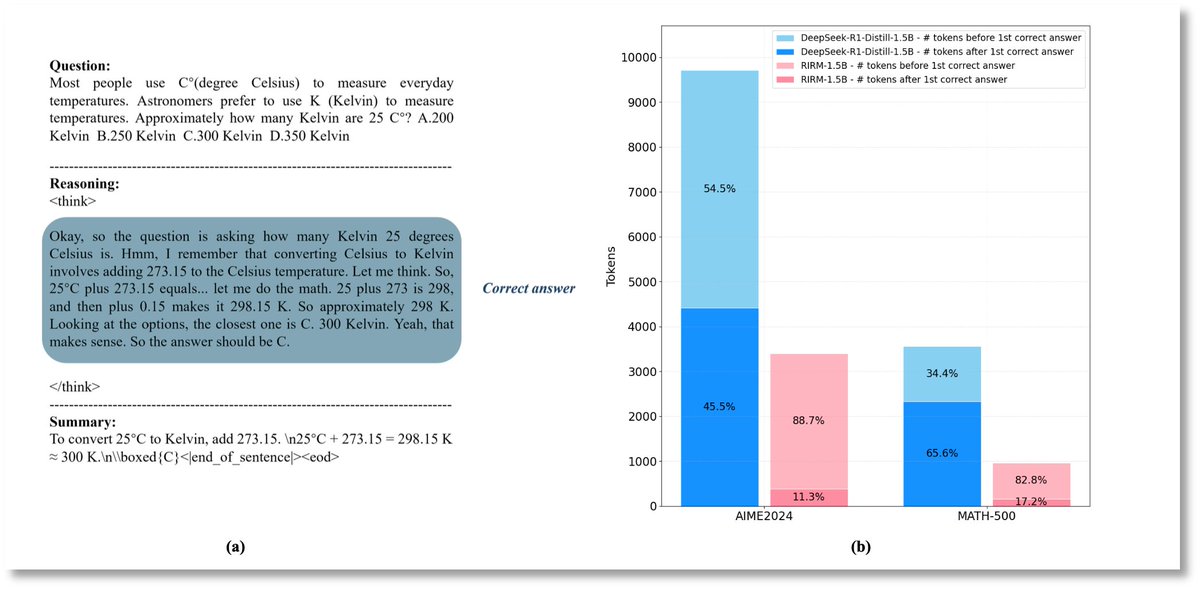
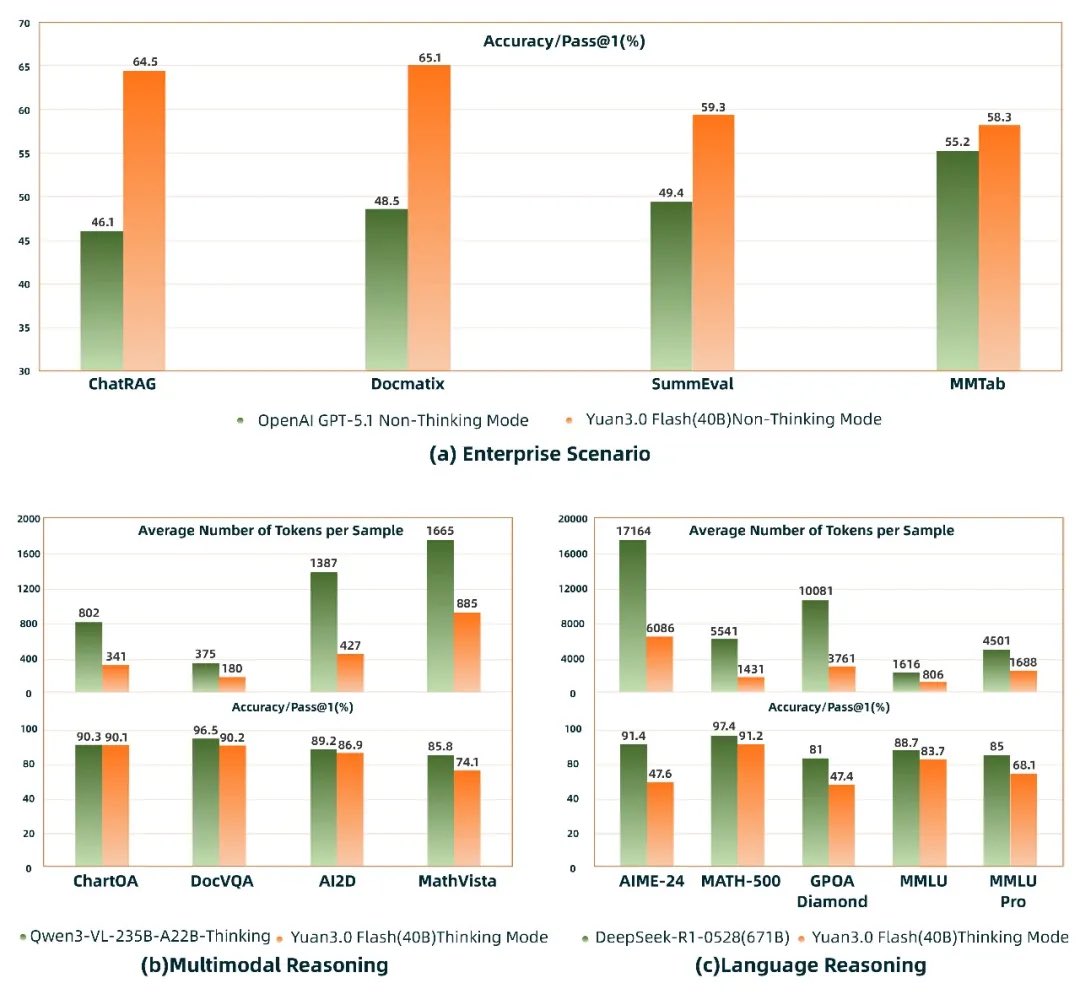
Announcing Yuan 3.0 Flash — an open-source, multimodal #LLM that’s “Higher Intelligence with Fewer Tokens” Explore the next-gen efficient LLM now: github.com/Yuan-lab-LLM/Y… ✨ 40B MoE (only 3.7B active), RIRM cuts 75% inference tokens—higher accuracy, lower cost ✨…

































United States Trends
- 1. Dabo N/A
- 2. Jassi N/A
- 3. Notre Dame N/A
- 4. Wendy N/A
- 5. Blades Brown N/A
- 6. Rivers N/A
- 7. Stacey N/A
- 8. Lobo N/A
- 9. Deion N/A
- 10. #FursuitFriday N/A
- 11. March for Life N/A
- 12. Ryan Wedding N/A
- 13. Jemele N/A
- 14. Nate Oats N/A
- 15. #TALON N/A
- 16. Bad Bunny N/A
- 17. OpTic N/A
- 18. Marc Anthony N/A
- 19. Bricillo N/A
- 20. Afghanistan N/A
Something went wrong.
Something went wrong.