
Umesh Patil
@_mesh
NLP/data scientist, psycholinguist IN: patil-umesh @umesh-patil.bsky.social







How do memory retrieval and prediction work together during sentence comprehension? We use computational modeling + eye-tracking to unpack their interaction in German possessive pronouns. New paper with @_joaoverissimo, @_mesh and @sol_lago doi.org/10.1016/j.jml.…

Contrary to standard prompting advice that you should give LLMs the context they need to succeed, I find it’s sometimes faster to be lazy and dash off a quick, imprecise prompt and see what happens. The key to whether this is a good idea is whether you can quickly assess the…

Interested in doing a PhD in French psycholinguistics 💻? We are looking for someone fluent in French and interested in Romance Languages. 3-year position (extension possible). 📅 Application deadline: December 20, 2024. Details: linguistlist.org/issues/35-3312

There are 2 mistakes you can make about LLMs: ① Thinking everything LLMs say is correct, they can reason, and with a bit more scale they’ll get us to superintelligence ② Thinking LLMs are good for almost nothing—they are FAR better at all #NLProc tasks than previous methods

East/West Germany's phantom borders More below
Interested in doing cross-linguistic comparisons using eye-tracking 👁️? Come do a 4-year postdoc with us! We are looking for someone fluent in Spanish and/or German 📅 Application deadline: March 1, 2024. More info: linguistlist.org/issues/35-369/

Great overview of compression algorithms for LLMs. Covers compression algorithms like pruning, quantization, knowledge distillation, low-rank approximation, parameter sharing, and efficient architecture design. This space is moving so fast. This is just a nice overview…


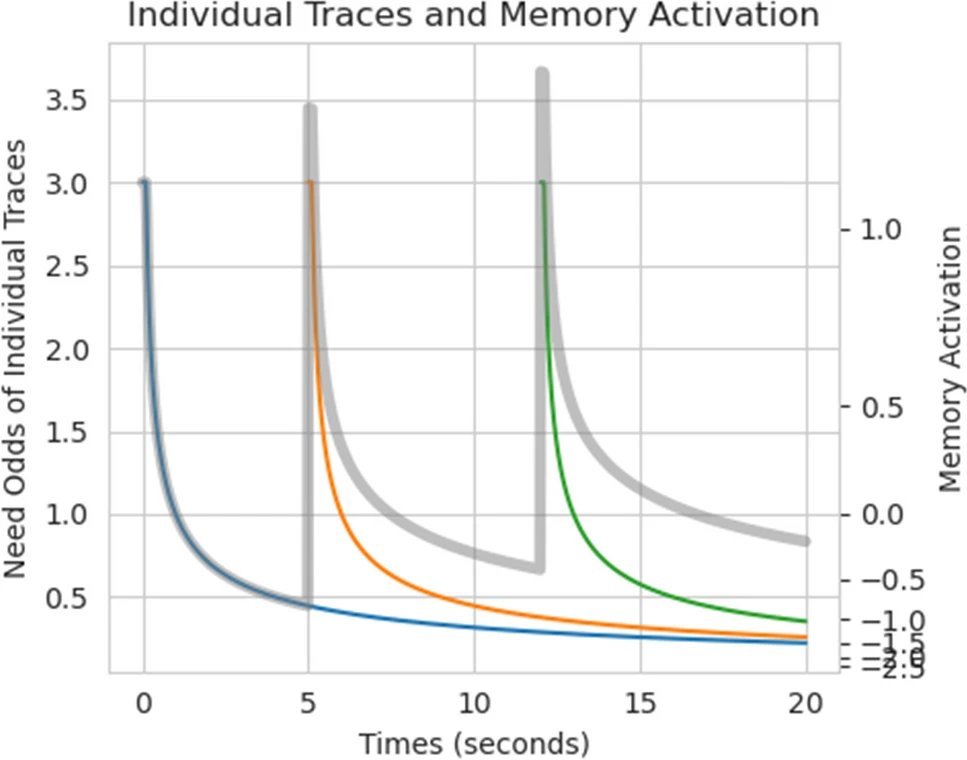
ACT-R is a phenomenal model for human long-term memory --- but have you wondered if and how well it matches the *neuroscience* of memory? Well, wonder no more: 🧵👇 1/4
Can you train an LLM from scratch using only the text that a human might plausibly read? Come find out today at 3:30PM! The organizers of the BabyLM challenge, the #CoNLL2023 shared task, will be presenting 🤩 babylm.github.io


We are happy to announce that we can once again offer Junior (3-6 months) and Senior (1-3 months) short-term fellowships to the #SFB1252. They are available in 2024.🎉 Apply by December 31st 🗓️and find more information on how to apply here. ▶️ sfb1252.uni-koeln.de/sites/sfb_1252…

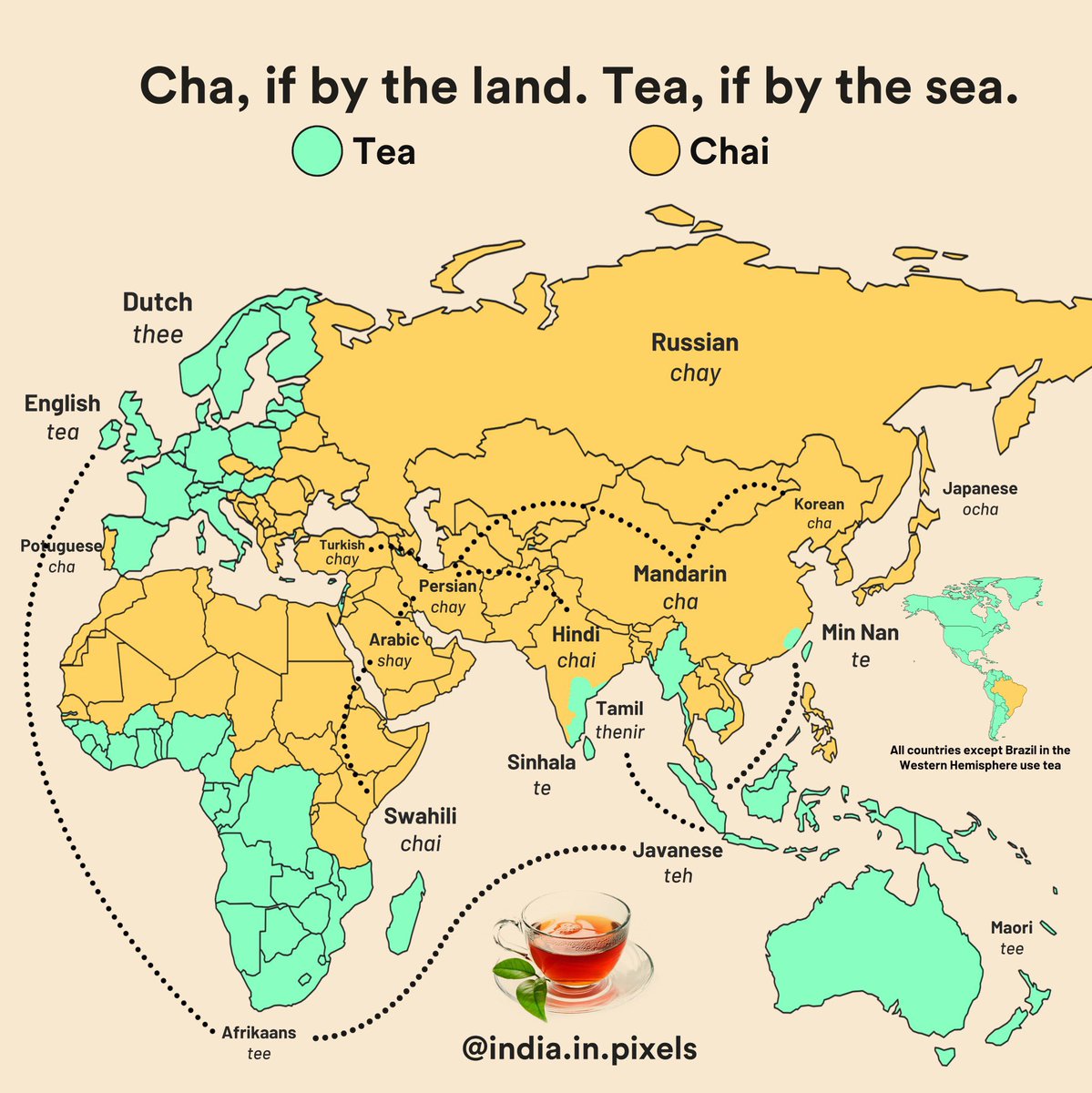
“Cha" and "te" are both Chinese words for tea. If a territory came into contact with the drink by: • The Silk Road = "cha" • Sea shipping routes (starting with Dutch traders) = "tea"

📢📢CALL FOR ABSTRACTS📢📢 Interested in Naturalistic Approaches to Reference? Then submit an abstract for our workshop at next year's #DGfS2024 in Bochum 🗣️🧑💼👥

Calls, DGfS 2024 AG 12: Naturalistic Approaches to Reference: Call for Papers: We invite presentations on all varieties of (online) methods, as well as presentations with a focus on language in interaction (e.g. on speech-gesture integration or other… dlvr.it/SqhK3w
If IRIS indeed does clustering of papers based on context rather than citations, it seems really useful to bypass the citation bias

Do an entire literature review – from a single paper. IRIS uses AI to bypass citation bias and categorize papers beautifully. Here is how to use it (free): 👇


People are testing large language models (LLMs) on their "cognitive" abilities - theory of mind, causality, syllogistic reasoning, etc. Many (most?) of these evaluations are deeply flawed. To evaluate LLMs effectively, we need some principles from experimental psychology.🧵


We still hear the cries for help from those trapped under the rubble. Many of our own families and neighbours have not survived. Thousands in #Syria are dead. Thousands more are missing. Please help us in our response by donating. #Earthquake gofund.me/8602b47f

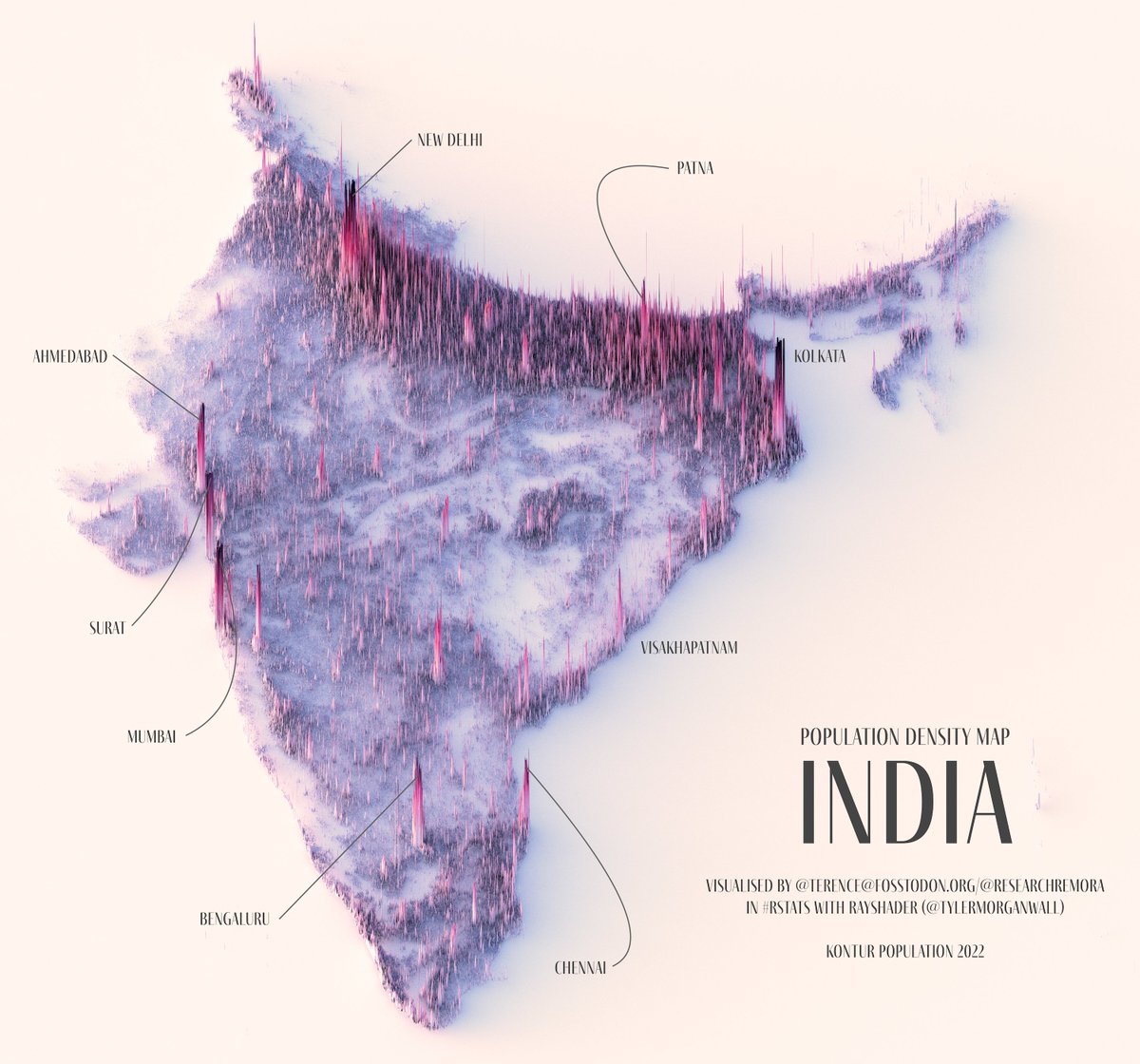
India just passed China as the most populous country in the world. Why? Because of the biggest accident in history Look at where people live in India. What's that band up north?

Announcing the BabyLM 👶 Challenge, the shared task at @conll_conf and CMCL'23! We’re calling on researchers to pre-train language models on (relatively) small datasets inspired by the input given to children learning language. babylm.github.io arxiv.org/abs/2301.11796

Here is a talk a gave at AMLAP summarizing some of the points we make in BBS paper “Deep Problems with Neural Network Models of Human Vision”: youtube.com/watch?v=7C_0vB… Still a few days to write a comment. Good way to spend a blizzard of a Christmas? cambridge.org/core/journals/…
... and that's a wrap on #CoNLL2022 ! Thanks to all the organizers, reviewers, authors, and attendees for making #CoNLL2022 what it was! ♥️ Looking forward to #CoNLL2023 already... It will feature a really cool shared task! 😃😃 babylm.github.io Stay tuned 📺 👋👋🎆🎆

Support: General Linguistics: PhD, University of Cologne, Cologne, Germany: The Collaborative Research Centre CRC 1252 “Prominence in Language” in Cologne, Germany, announces short-term Junior fellowships available between April and December 2023 for a… dlvr.it/Sdv9nf




























































































United States الاتجاهات
- 1. New York 938K posts
- 2. New York 938K posts
- 3. Virginia 489K posts
- 4. #DWTS 39K posts
- 5. $TAPIR N/A
- 6. Texas 202K posts
- 7. Prop 50 160K posts
- 8. Sixers 12.6K posts
- 9. Bulls 34.1K posts
- 10. Cuomo 388K posts
- 11. TURN THE VOLUME UP 7,283 posts
- 12. #Election2025 15.1K posts
- 13. Jay Jones 92.7K posts
- 14. Maxey 7,737 posts
- 15. Embiid 5,980 posts
- 16. Eugene Debs 1,601 posts
- 17. WOKE IS BACK 27.4K posts
- 18. Andy 64K posts
- 19. Harden 9,032 posts
- 20. Josh Giddey 5,356 posts






Something went wrong.
Something went wrong.