
Talvez você curta












The new steam age. This is actually becoming true in many cases. It's possible to do so much more on your own now.


My formulation is slightly different. Agent = 𝐂𝐨𝐧𝐭𝐞𝐱𝐭 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠 + 𝐋𝐋𝐌 + 𝐓𝐨𝐨𝐥𝐬. The real differentiation between most agent companies lies in how they build their CE and tools. Those using minimal model-specific hacks can transition seamlessly to new…

Can't agree more. Agent = LLM + tools. That’s Occam’s Razor. To build better agents, you either improve the LLM, or you create better tools. We shouldn't need complex agent frameworks.

Now I understand @DSPyOSS from this video, and I will attempt to break it down. Basically if you build software that uses LLMs, it helps you manage, test and optimize backend prompts. When a new LLM comes out, you can swap it in and get the new best prompts for your existing…



🎞️𝐂𝐡𝐚𝐢𝐧-𝐨𝐟-𝐕𝐢𝐬𝐮𝐚𝐥-𝐓𝐡𝐨𝐮𝐠𝐡𝐭 for Video Generation🎞️ #VChain is an inference-time chain-of-visual-thought framework that injects visual reasoning signals from multimodal models into video generation - Page: eyeline-labs.github.io/VChain - Code: github.com/Eyeline-Labs/V…


Eyeline Labs presents VChain for smarter video generation This new framework introduces a "chain-of-visual-thought" from large multimodal models to guide video generators, leading to more coherent and dynamic scenes.

From sitting in CMU lectures to giving one - grateful for the chance to guest lecture in the Program Analysis class this week! Shared insights on how static analysis makes its way from research papers to production code.


This is a very solid and promising research that scales consistency models to 10B+ video diffusion models. The combination of sCM and Variational Score Distillation is a very promising direction for few-step generation!

🚀Try out rCM—the most advanced diffusion distillation! ✅First to scale up sCM/MeanFlow to 10B+ video models ✅Open-sourced FlashAttention-2 JVP kernel & FSDP/CP support ✅High quality & diversity videos in 2~4 steps Paper: arxiv.org/abs/2510.08431 Code: github.com/NVlabs/rcm


Excited to share our latest work — Self-Improving Demonstrations (SID) 🎯 A new paradigm for Goal-Oriented VLN where agents teach themselves through exploration — no human demos needed, yet surpassing shortest-path supervision! Thrilled by what this means for scalable embodied…

🚨 Thrilled to introduce Self-Improving Demonstrations (SID) for Goal-Oriented Vision-and-Language Navigation — a scalable paradigm where navigation agents learn to explore by teaching themselves. ➡️ Agents iteratively generate and learn from their own successful trajectories ➡️…


Better Together: Leveraging Unpaired Multimodal Data for Stronger Unimodal Models "We introduce UML: Unpaired Multimodal Learner, a modality-agnostic training paradigm in which a single model alternately processes inputs from different modalities while sharing parameters across…


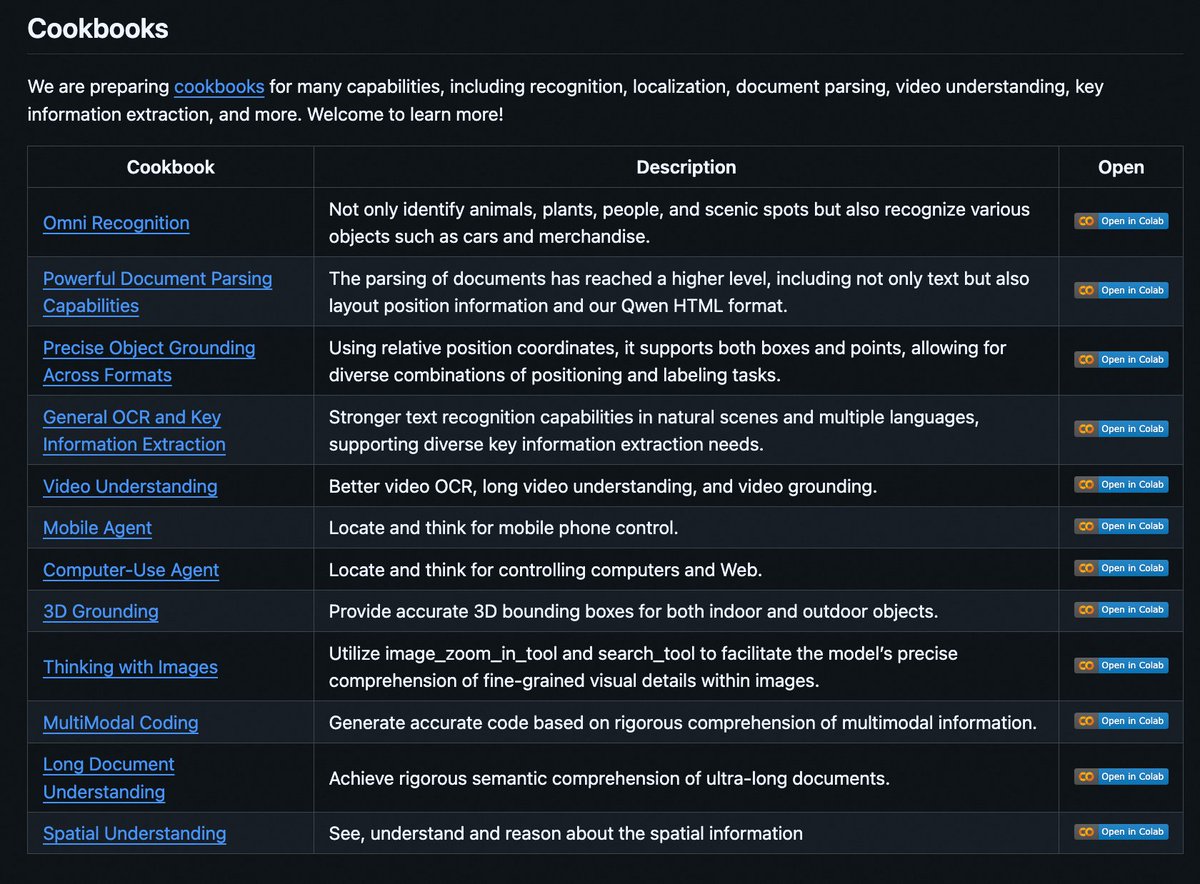
Introducing Qwen3-VL Cookbooks! 🧑🍳 A curated collection of notebooks showcasing the power of Qwen3-VL—via both local deployment and API—across diverse multimodal use cases: ✅ Thinking with Images ✅ Computer-Use Agent ✅ Multimodal Coding ✅ Omni Recognition ✅ Advanced…

Tina proved that LoRA can match or surpass full-parameter RL. Tora builds directly on that result, turning it into a full framework. Built on torchtune, it extends RL post-training to LoRA, QLoRA, DoRA, and QDoRA under one interface with GRPO, FSDP, and compile support. QLoRA…

Tina: Tiny Reasoning Models via LoRA LoRA-RL tuned 1.5B models on curated reasoning data, achieving +20% gains and 43% Pass@1 (AIME24) at $9 total cost. Outperforms full-parameter RL on DeepSeek-R1-Distill-Qwen-1.5B. - LoRA-based RL yields better performance with less compute.…


career update: ml researcher done : > built proprietary ML pipeline for a whole gnn pipeline exploring GCN, SAGE, GAT, GNNIE, some dev future work : > studying gnns as gradient-flow , geometric & Bayesian GNNs; working on interpretability, inference & full-stack dev








🧵1/ Latent diffusion shines in image generation for its abstraction, iterative-refinement, and parallel exploration. Yet, applying it to text reasoning is hard — language is discrete. 💡 Our work LaDiR (Latent Diffusion Reasoner) makes it possible — using VAE + block-wise…

🚨New Content: The Trillion Dollar AI Software Development Stack It will generate massive value, spawn hundreds of start-ups and has created the fastest growing companies in history. @stuffyokodraws and I did a deep-dive on market, start-ups and the evolving stack. ⬇️


🪩The one and only @stateofaireport 2025 is live! 🪩 It’s been a monumental 12 months for AI. Our 8th annual report is the most comprehensive it's ever been, covering what you *need* to know about research, industry, politics, safety and our new usage data. My highlight reel:

If you’re getting into PyTorch, give this a read. It discusses the usability, design patterns and implementation ideas behind the framework. A few bits and pieces that can help you build a good foundation.


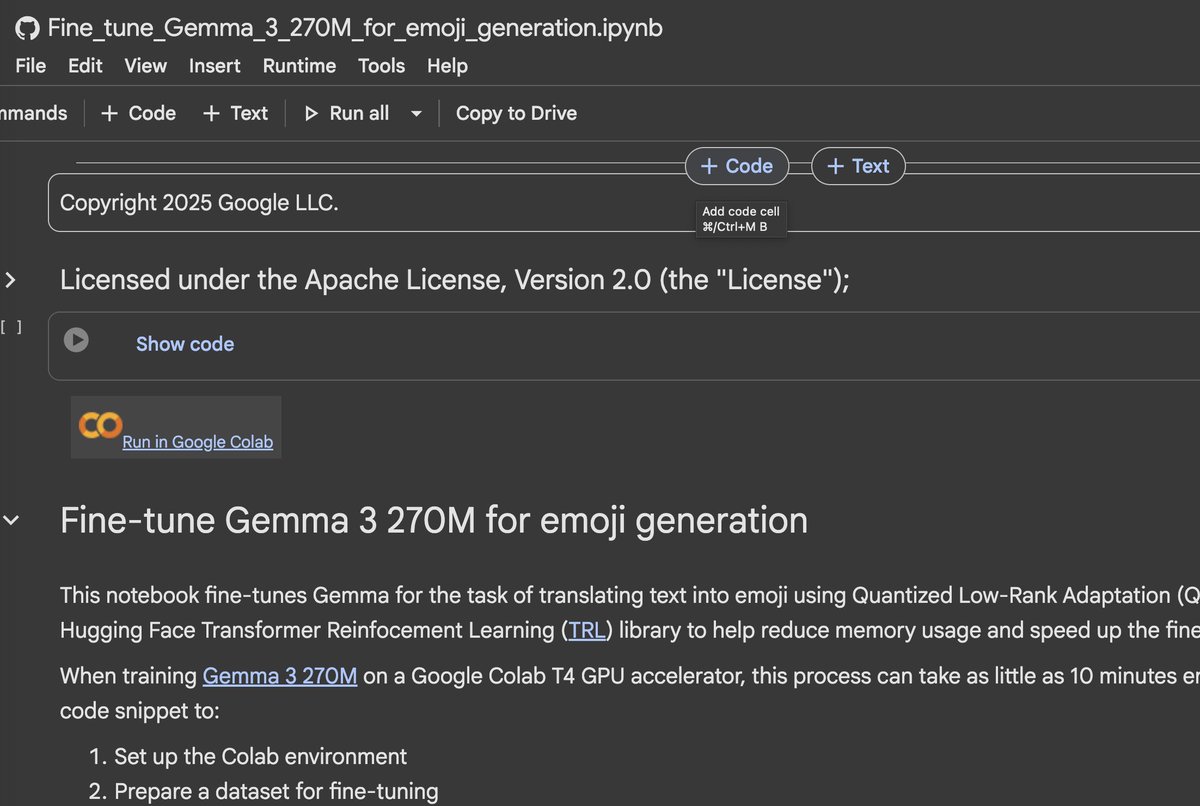
deepmind just dropped a handy little colab on fine-tuning gemma3-270m for emoji generation. this is a super lower resource task with 270m parameter model, qlora, short sequences. so it's a great one to try out locally or on colab. it's also a nice one to deploy in a js app…






















































































United States Tendências
- 1. Auburn 46.1K posts
- 2. At GiveRep N/A
- 3. Brewers 65.6K posts
- 4. Cubs 56.7K posts
- 5. #SEVENTEEN_NEW_IN_TACOMA 33.5K posts
- 6. Georgia 68.5K posts
- 7. Gilligan's Island 4,847 posts
- 8. #byucpl N/A
- 9. Utah 25.5K posts
- 10. MACROHARD 4,674 posts
- 11. Arizona 42.1K posts
- 12. Kirby 24.3K posts
- 13. Wordle 1,576 X N/A
- 14. #AcexRedbull 4,288 posts
- 15. Michigan 63.2K posts
- 16. #SVT_TOUR_NEW_ 25.2K posts
- 17. #Toonami 2,995 posts
- 18. Boots 51.2K posts
- 19. mingyu 91.9K posts
- 20. Hugh Freeze 3,282 posts
Talvez você curta
-
 SevenX Ventures
SevenX Ventures
@SevenXVentures -
 JEETENDRA SOLANKI
JEETENDRA SOLANKI
@jeetr1511 -
 Frank (Haofan) Wang
Frank (Haofan) Wang
@Haofan_Wang -
 Khalil Lechelt
Khalil Lechelt
@khalillechelt -
 Wendell Strode
Wendell Strode
@StrodeWendell -
 Robert Riachi
Robert Riachi
@robertriachi -
 Sergiu Nistor
Sergiu Nistor
@SergiuNistor6 -
 Hsing-Huan Chung
Hsing-Huan Chung
@HsingHuan -
 KatzeKot
KatzeKot
@katze_kot -
 thetnaingtun
thetnaingtun
@thetnaingchen -
 Beebo is Our Lord and Savior
Beebo is Our Lord and Savior
@Beeboooooooo333
Something went wrong.
Something went wrong.