
You might like







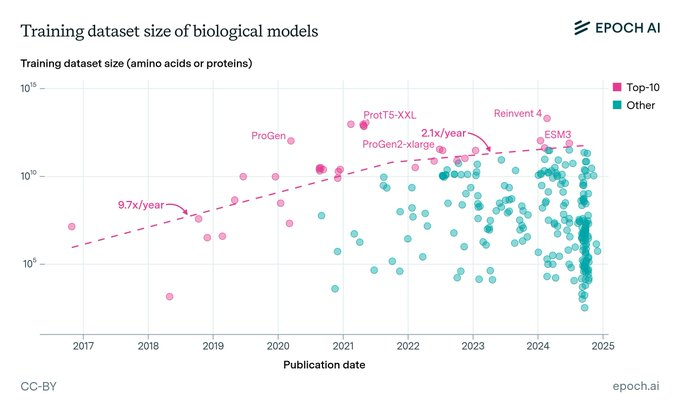
Biology’s lack of data is holding back its AI boom. Epoch’s latest report shows explosive growth in biological model training data size from 2017–2021 (9.7×/year), but a (2.1x/year) plateau since. AI models for biology are ready to transform science if the data can keep up.

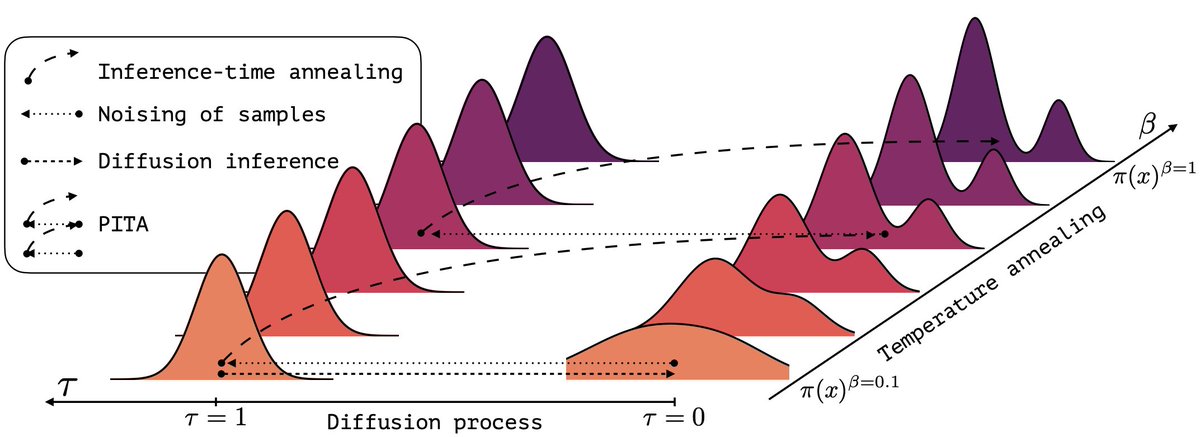
(1/n) Sampling from the Boltzmann density better than Molecular Dynamics (MD)? It is possible with PITA 🫓 Progressive Inference Time Annealing! A spotlight @genbio_workshop of @icmlconf 2025! PITA learns from "hot," easy-to-explore molecular states 🔥 and then cleverly "cools"…

🚀 After two+ years of intense research, we’re thrilled to introduce Skala — a scalable deep learning density functional that hits chemical accuracy on atomization energies and matches hybrid-level accuracy on main group chemistry — all at the cost of semi-local DFT. ⚛️🔥🧪🧬


Researchers can analyze vast protein datasets faster with MMseqs2-GPU in the MSA-Search NIM. Unlock new possibilities for disease research and therapeutic breakthroughs. #drugdiscovery ➡️ nvda.ws/4kMUoqd


Another great example of the UK's ability to develop unique data to push forward AI for bio infrastructure Props to @Basecamp_Res for launching the world's largest biodiscovery dataset, over 10x the number of protein sequences than are currently publicly available 🧬🚀

Protein structure ≠ protein folding/dynamics The new north star: energy‑landscape learning, rather than static structure prediction Next wave: AI that learns free energy for "true" inverse folding


most underrated fundraising strategy: revenue

🧬 News alert: We’re bringing BaseData out of stealth — the world’s largest and fastest growing biodiscovery dataset, built in collaboration with scientists across 26 countries. 🔍 BaseData adds 9.8 billion newly discovered protein sequences to the known tree of life — expanding…


Exciting work by @Basecamp_Res! Great to see the emphasis on diversity and also the comparison with @tatta_bio's Open MetaGenome (OMG) dataset curated from public databases. I'm super curious - how was the team able to 10x the recovered sequence diversity in the past few months?

🧬 News alert: We’re bringing BaseData out of stealth — the world’s largest and fastest growing biodiscovery dataset, built in collaboration with scientists across 26 countries. 🔍 BaseData adds 9.8 billion newly discovered protein sequences to the known tree of life — expanding…

Some personal news: I’ve been promoted to tenured Associate Professor at the University of Toronto @UofT . When I moved here from Stanford (@Stanford) six years ago, I had no connections, no lab, just a belief that AI could change how we understand and deliver healthcare. What I…

Hot takes, pseudocode, score matching, EBMs and staircases found inside: markneumann.xyz/blog/modeling-…


If you cite Muon, I think you should definitely cite SSD (proceedings.mlr.press/v38/carlson15.…) by @CevherLIONS et al. (sorry I can't find the handle of other authors) -- which proposed spectral descent.

🚨Excited to announce that the Sovereign AI Unit is investing £8m in OpenBind: building the world's largest protein-ligand dataset. Backed by a top UK consortium, inc. Isomorphic Labs and Nobel Laureate David Baker, this will help the UK become the home for AI drug design 1/6🧵


Really pleased to share what I have been working on for 2 months: 🇬🇧 UK SovAI are today announcing our £8m seed investment into OpenBind - A consortium that will actually make AI for drug discovery great by generating 500k experiment protein-ligand complexes!! Explainer 🧵 (1/n)

Excited to see this announcement from the Government’s SovereignAI unit: funding for the world’s largest dataset of protein interactions, led by a truly world-class group of researchers As @demishassabis says, “This is a brilliant initiative for UK science”


🚀 Excited to release BoltzDesign1! ✨ Now with LogMD-based trajectory visualization. 🔗 Demo: rcsb.ai/ff9c2b1ee8 Feedback & collabs welcome! 🙌 🔗: GitHub: github.com/yehlincho/Bolt… 🔗: Colab: colab.research.google.com/github/yehlinc… @sokrypton @MartinPacesa

AGI timelines are very bimodal. It's either by 2030 or bust. AI progress over the last decade has been driven by scaling training compute of frontier systems (3.55x a year, 160x over 4 years). This simply cannot continue beyond this decade, whether you look at chips, power,…

There's an obvious way to fix CVD: removing plaques. There are 2-3 companies doing this. Why so few, given how pervasive CVD is? Lowering LDL is nice but removing plaques periodically seems even better.


The premier conference on Machine Learning for Computational Biology is Sep 9-10 at the NY Genome Center in NYC! Submission deadline is June 1 for 2-page abstracts and 8-page papers (eligible for proceedings track). Registration is now open! (Link below) Please retweet!

We’re now programming energy landscapes, not static folds. Conformational Biasing scans every point mutant 🧬against multiple states in ⏱️<60s on a single 4090—pushing K-Ras ON, tightening Spike-ACE2, rewiring LplA🔧

























































































United States Trends
- 1. Good Monday 32.1K posts
- 2. #MondayMotivation 33.5K posts
- 3. #Talus_Labs N/A
- 4. Happy Birthday Marines 4,368 posts
- 5. Pond 178K posts
- 6. Rudy Giuliani 19.7K posts
- 7. Semper Fi 4,252 posts
- 8. #MondayVibes 2,222 posts
- 9. United States Marine Corps 4,792 posts
- 10. #MondayMorning 1,376 posts
- 11. 8 Democrats 12.3K posts
- 12. Mark Meadows 18.3K posts
- 13. Happy New Week 48.4K posts
- 14. #USMC N/A
- 15. The BBC 455K posts
- 16. Resign 121K posts
- 17. Devil Dogs 1,272 posts
- 18. Victory Monday N/A
- 19. Edmund Fitzgerald 3,923 posts
- 20. Tim Kaine 27.9K posts






Something went wrong.
Something went wrong.