
你可能會喜歡
















CSE's B. Aditya Prakash, Chao Zhang, and Xiuwei Zhang are among the 1⃣6⃣ #GTComputing faculty awarded promotion and tenure this year! Be sure to check out the full list in the story 👇, and join us in congratulating all our esteemed colleagues!🥳🎉 cc.gatech.edu/news/computing…

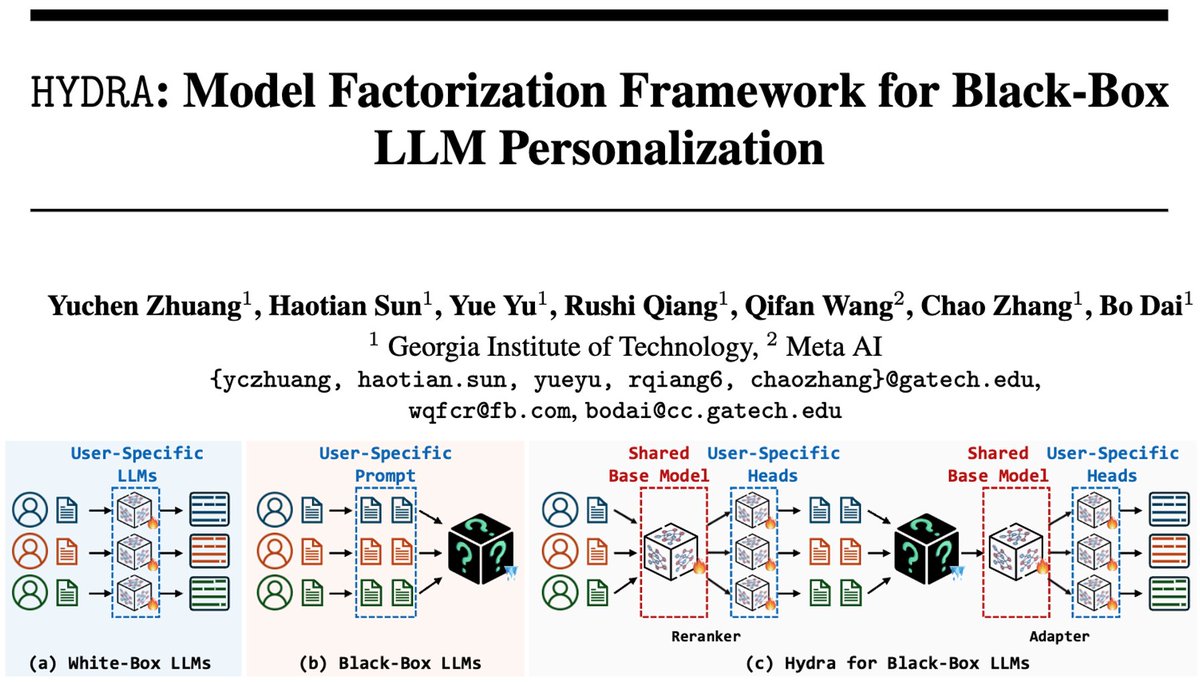
Excited to present HYDRA 🐉 at #NeurIPS2024! 🚀 Our novel model-factorization framework combines personal behavior patterns 👤 with global knowledge 🌐 for truly personalized LLM generation. Achieves 9%+ gains over SOTA across 5 tasks 🏆 using personalized RAG. Learn more:…

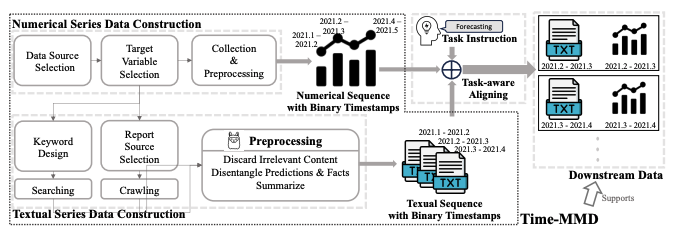
Time-MMD: A New Multi-Domain Multimodal Dataset for Time Series Analysis ⏰: Friday, December 13 This is in collaboration with @HessianLiu, Shangqing Xu, @leozhao_zhiyuan, @Harsha_64, Aditya B. Sasanur, Megha Sharma, @jiamingcui1997, @qingsongedu, @chaozhangcs, @badityap
Aligning Large Language Models with Representation Editing: A Control Perspective. ⏰: Thursday, December 12 This is in collaboration with: @Haorui_Wang123*, Wenhao Mu*,@YuanqiD, @yuchen_zhuang, @YifeiZhou02, Yue Song, @rongzhi_zhang, @kaiwang_gua, @chaozhangcs.
Day 1 of #NeurIPS2024 kicks off today! Check out the GT @ NeurIPS 2024 website 🔗👇 for a deep dive of @GeorgiaTech's 162+ researchers and their 84 papers being presented this week in Vancouver! sites.gatech.edu/research/neuri… @gtcomputing @GTResearchNews @ICatGT @gatech_scs #NeurIPS

🔍 Reward modeling is a reasoning task—can self-generated CoT-style critiques help? 🚀 Check out my intern work at Llama Team @AIatMeta, 3.7-7.3% gains on RewardBench vs. RM & LLM judge baselines, with better generalization & data efficiency! arxiv.org/abs/2411.16646 #rlhf #LLM



Happy to share RE-Control is accepted to #NeurIPS2024!
1/n Want to align your LLM with human objectives but lack the computing resources for fine-tuning?😭😭 We propose RE-Control, which aligns LLMs through representation editing (RE) from a control perspective!🤩🤩 Arxiv: arxiv.org/pdf/2406.05954 Code: github.com/Lingkai-Kong/R…

Introducing RankRAG, a novel RAG framework that instruction-tunes a single LLM for the dual purposes of top-k context ranking and answer generation in RAG. For context ranking, it performs exceptionally well by incorporating a small fraction of ranking data into the training…




1/n Want to align your LLM with human objectives but lack the computing resources for fine-tuning?😭😭 We propose RE-Control, which aligns LLMs through representation editing (RE) from a control perspective!🤩🤩 Arxiv: arxiv.org/pdf/2406.05954 Code: github.com/Lingkai-Kong/R…
🎉 Congrats, Lingkai! 🎓 I am incredibly proud of your achievements and the impact you've made at @GTCSE. Wishing you all the best as you embark on your exciting new journey. Keep soaring! 🚀 #ProudMentor
I'll cherish my time at @GTCSE! Also looking forward to my new journey at @HCRCS working with @MilindTambe_AI!

🧵1/n LLMs significantly improve Evolutionary Algorithms for molecular discovery! For 18 different molecular optimization tasks, we demonstrate how to achieve SOTA performance by incorporating different LLMs! Learn more in our new paper! Website: molleo.github.io(w/ Code)

We recently explored if LLMs can be used to accelerate materials discovery. Instead of using LLMs to predict properties or generating new materials directly, we ask it to iteratively modify a starting material towards a given property target. Details here: arxiv.org/abs/2406.13163

Having troubles with blind domain adaptation for GPTs through OpenAI or Azure 🤔? We are excited to introduce BBox-Adapter 🔌— Lightweight Adapting for Black-Box #LLMs📦. BBox-Adapter offers a transparent, privacy-conscious, and cost-effective solution for customizing…


Big thanks to @anthonygitter for the nice summary of our #RECOMB2024 paper!

"Contrastive Fitness Learning: Reprogramming Protein Language Models for Low-N Learning of Protein Fitness Landscape" by @luoyunan and team. doi.org/10.1101/2024.0… 1/
Want smarter LLM agents? 🤖 Join Haotian's @haotiansun014 poster on AdaPlanner tomorrow! 📅 It enables LLMs to think ahead & plan adaptively based on feedback. #NeurIPS2023 #LLMs #LLMagent arxiv.org/abs/2305.16653

Excited to introduce AdaPlanner, our LLM agent for solving embodied tasks via closed-loop planning. Key features: 1) Adaptively refines LLM-generated plan from environment feedback, with both in-plan and out-of-plan refining strategies 2) A code-style LLM prompt structure to…
#NeurIPS2023 How can #LLMs generate synthetic data for training smaller models? Join Yue's @yue___yu poster session at NeurIPS2023 (Session 6) & find out more! arxiv.org/abs/2306.15895

🚀 Checkout our new preprint! 🔍 LLM-as-training-data-generator is a recent paradigm for zero-shot learning. We design attributed prompts to generate diverse training data from #LLMs automatically. 1/n Link: arxiv.org/abs/2306.15895 Code: shorturl.at/amBV8

Yuchen will present this work at today's poster session 1 #423. Don't miss out if you are at #NeurIPS2023

"May the force be with you" at #NeurIPS2023! Interested in ML forcefield & MD simulation? Don't miss today's poster session 1 #1919. My student Rui will share our work on unified force-centric pre-training over 3D molecular conformations! arxiv.org/abs/2308.14759
#KDD2023 If you care about uncertainty qualification and trustworthy AI, don't miss our tutorial tomorrow 1pm at Room 202A
We will present our #KDD tutorial on “Uncertainty Quantification in Deep Learning” at 1-4pm, Aug. 6th. We will discuss recent progress in uncertainty-aware DNNs and their applications across various domains. Welcome to attend & engage with us! (lingkai-kong.com/kdd23_tutorial/) @kdd_news


1/4 🧵 A new research introduces AttrPrompt, a Language Model as Training Data Generator. This is a game-changer for Zero-Shot Learning, a paradigm that allows AI to understand tasks it's never seen before. 🚀 @yue___yu Quick Read: marktechpost.com/2023/07/02/a-n…




















































































































United States 趨勢
- 1. Liverpool 137K posts
- 2. #UFCQatar 19.4K posts
- 3. Slot 103K posts
- 4. Chris Paul 9,302 posts
- 5. Lamine 42.4K posts
- 6. Anfield 25.5K posts
- 7. Isak 26.8K posts
- 8. Dalby 1,064 posts
- 9. Rutgers 4,067 posts
- 10. Forest 115K posts
- 11. Klopp 8,238 posts
- 12. Ferran 17.1K posts
- 13. Arbuckle N/A
- 14. Fermin 18.9K posts
- 15. Konate 11.8K posts
- 16. Camp Nou 74.5K posts
- 17. #LIVNFO 16.2K posts
- 18. Point God 5,056 posts
- 19. Perez 26.6K posts
- 20. Joan Garcia 12.4K posts
你可能會喜歡
-
 Yue Yu
Yue Yu
@yue___yu -
 Yu Su
Yu Su
@ysu_nlp -
 Yuchen Zhuang
Yuchen Zhuang
@yuchen_zhuang -
 Yu Zhang
Yu Zhang
@yuz9yuz -
 Ziniu Hu
Ziniu Hu
@acbuller -
 Jundong Li
Jundong Li
@LiJundong -
 Danqing Zhang
Danqing Zhang
@Danqing_Z -
 🌴Muhao Chen🌴
🌴Muhao Chen🌴
@muhao_chen -
 lesong
lesong
@dasongle -
 Bowen Jin
Bowen Jin
@BowenJin13 -
 Meng Jiang
Meng Jiang
@Meng_CS -
 Haoming Jiang
Haoming Jiang
@jiang_haoming -
 Jian Kang
Jian Kang
@jiank_uiuc -
 Tuo Zhao
Tuo Zhao
@tourzhao -
 Yu Meng
Yu Meng
@yumeng0818
Something went wrong.
Something went wrong.