







Excited to announce I’m building Docuglean - an open-source, privacy-focused document intelligence layer with three key foundations:. • Agentic OCR for parsing documents into high-quality, ready-to-use data. powered by SOTA VLM models for complex tables, formats, and layouts.…

Love the huge OCR boost. Qwen3VL-235B-A22B beats GPT5 and Claude-Opus 4.1

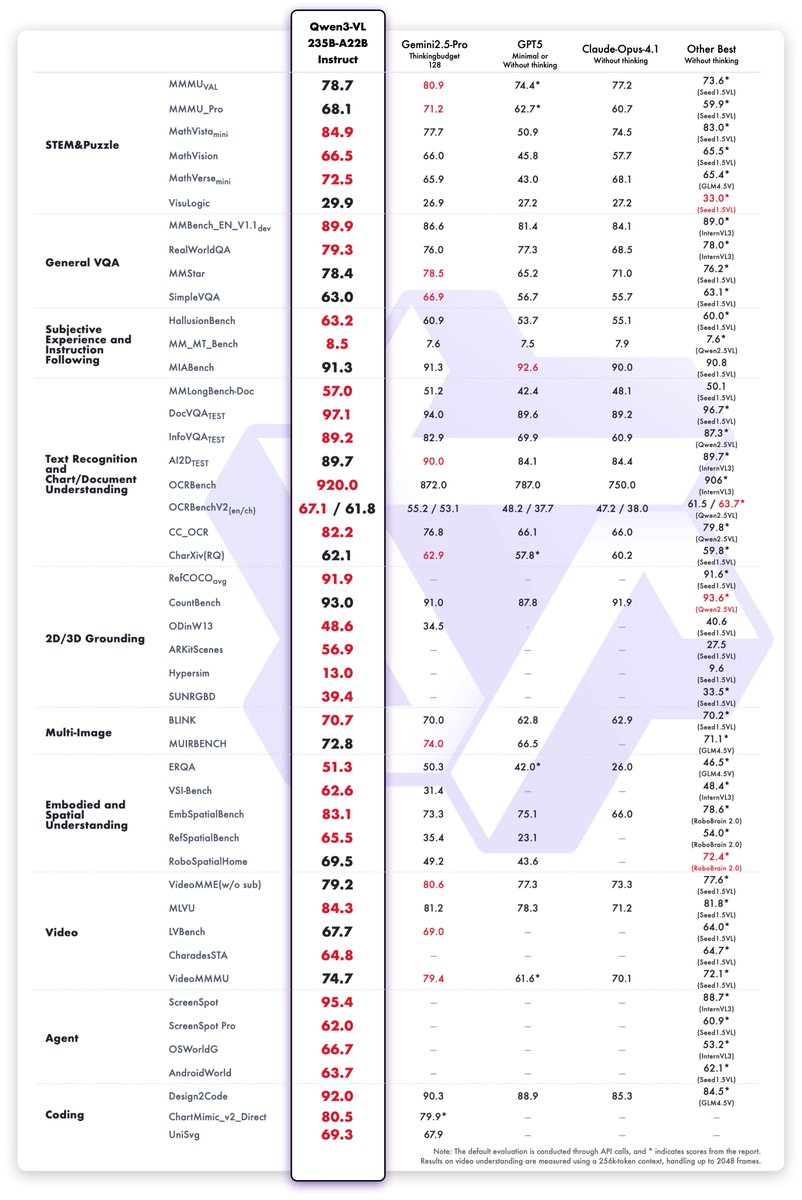
🚀 We're thrilled to unveil Qwen3-VL — the most powerful vision-language model in the Qwen series yet! 🔥 The flagship model Qwen3-VL-235B-A22B is now open-sourced and available in both Instruct and Thinking versions: ✅ Instruct outperforms Gemini 2.5 Pro on key vision…
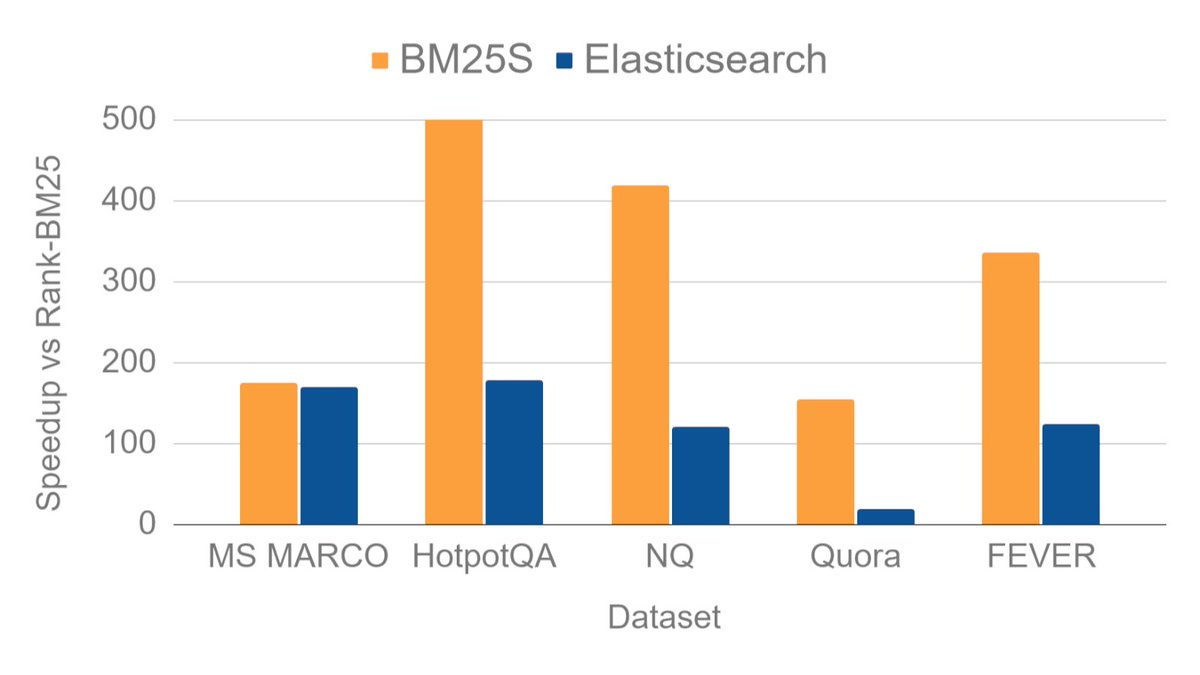
used bm25 for a doc search app and it was way better. faster, cheaper and gives results the way a user would search for docs. chose bm25s since it was smaller and known for its extremely fast retrieval with nicer results vs Elasticsearch, BM25-PT and Rank-BM25

VGT (GiT and ViT) + a specialized OCR engine like PaddleOCR and a VLM like Qwen for fallbacks is all you need for a high-quality structured data ready for LLMs Building this for our agentic ocr and def looking for testers. Send me your most complex PDFs :)

Oldie but goodie. Stumbled across this late 2024 paper while digging into recent OCR research. The timing works well with the advanced doc layout analysis solutions I've been working on


reading this research paper on using Vision Grid Transformer for Document Layout Analysis. Pretty solid approach for breaking down document pages into structured components like headers, titles, and body text. The value lies when you extract text from each section separately and…

Excited to announce I’m building Docuglean - an open-source, privacy-focused document intelligence layer with three key foundations:. • Agentic OCR for parsing documents into high-quality, ready-to-use data. powered by SOTA VLM models for complex tables, formats, and layouts.…
I reviewed 100 models over the past 30 days. Here are 5 things I learnt. TL;DR: Spent a month testing every AI model for work, a few tools I'm building and RL. Build task-specific evals. Most are overhyped, a few are gems, model moats are ephemeral, and routers/gateways are the…
High-quality data is the fuel for modern data deep learning model training. HT @lilianweng lilianweng.github.io/posts/2024-02-…































































































United States トレンド
- 1. Austin Reaves 52.2K posts
- 2. #LakeShow 3,181 posts
- 3. Trey Yesavage 38.3K posts
- 4. Jake LaRavia 6,187 posts
- 5. #LoveIsBlind 4,562 posts
- 6. Rudy 9,318 posts
- 7. jungwoo 110K posts
- 8. Jeremy Lin N/A
- 9. doyoung 82.2K posts
- 10. #Lakers 1,178 posts
- 11. Blue Jays 62.2K posts
- 12. Happy Birthday Kat N/A
- 13. #AEWDynamite 23.2K posts
- 14. Pelicans 4,495 posts
- 15. Kacie 1,887 posts
- 16. Snell 13.7K posts
- 17. Devin Booker 1,275 posts
- 18. Dodgers in 7 1,629 posts
- 19. Wolves 64.7K posts
- 20. Kenny Smith N/A







Something went wrong.
Something went wrong.