
CJ Carr
@cortexelation
→ @dadabots ← Creative AI & Death Metal #DSP #MIR #NLP #ML #NeuralNetworks | @Harmonai_org
You might like













Our paper "Generating Black Metal and Math Rock: Beyond Bach, Beethoven, and Beatles" got accepted by NIPS 2017 Workshop for Machine Learning for Creativity and Design! @zzuk_at_aol #dadabots

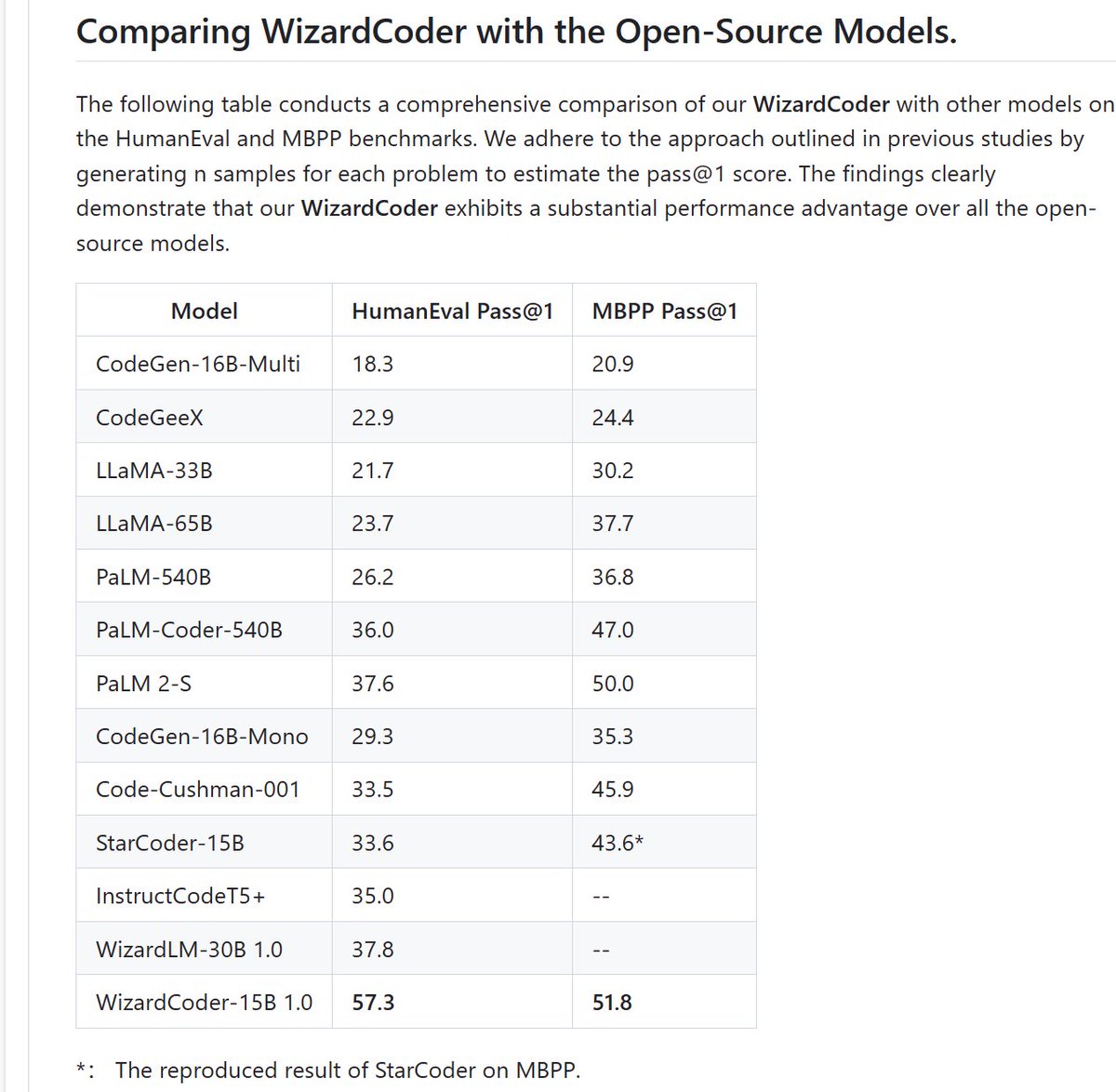
WizardCoder-15B is crushing it‼️🔥 Amazing progress in open-source code LLMs recently. I believe open-source may have progressed beyond closed-source models in this area. github.com/nlpxucan/Wizar…
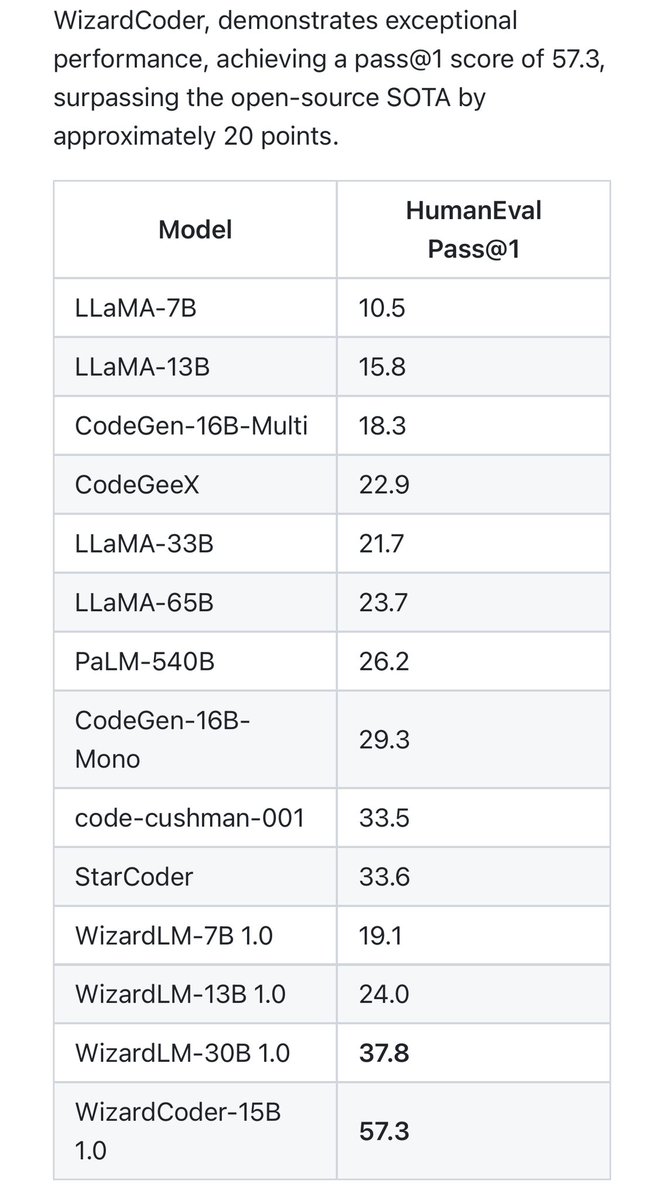

🔥🔥🔥 Introduce the newest WizardCoder model ! 1. Surpass Claude-Plus (+6.8), Bard (+15.3) and InstructCodeT5+ (+22.3) on HumanEval Benchmarks 2. Paper is coming, with brand-new Evol+ methods for code LLMs Github: github.com/nlpxucan/Wizar… HF Weight: huggingface.co/WizardLM/Wizar…


GPT-Engineer is BLOWING UP on GitHub right now 🔥 Prompt an AI agent to write an entire codebase 🤯 +2k stars today alone. I'll be experimenting with it this weekend to improve my workflow.


Absolutely fantastic work. Congrats! \m/

Darius's "Hyperbolic Audio Source Separation" paper has been recognized as one of the top 3% of all papers accepted at #ICASSP2023 @ieeeICASSP 👏🎉🍾 Paper: arxiv.org/abs/2212.05008 Code: github.com/merlresearch/h… Demo video: youtube.com/watch?v=RKsAMb…


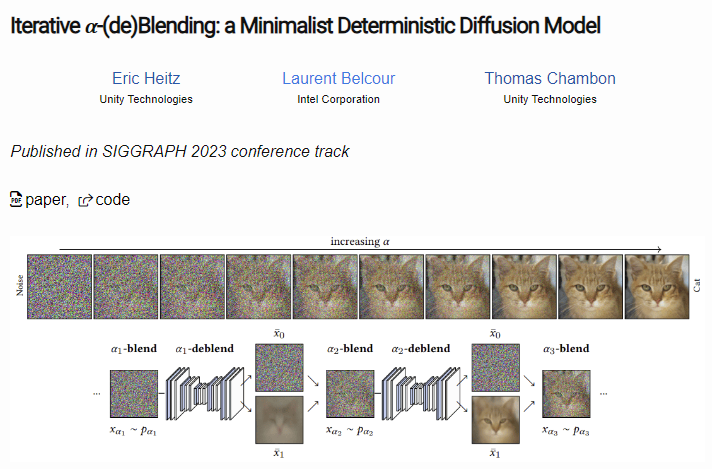
Interesting alternative derivation of diffusion models without differential equations or variational inference. Reminiscent of flow matching / rectified flow. Which of these perspectives is the simplest is subjective IMO, but more is better: new perspectives inspire new ideas!

When @_Laurent and I started learning about diffusion models, we were puzzled by the amount of jargon and concepts. So, we derived a model from scratch with our own graphics-people intuitions. Simple derivation, simple implementation, SOTA quality. ggx-research.github.io/publication/20…

Phonetic palindrome Record yourself saying “Serbian neighbours” Reverse it (Sound on)

every moment you leave an A100 idle in the cloud the Basilisk adds another tally to your karmic record


the year is 2030. after ed sheeran lost his case, musicians exhausted every 4-bar chord progression. pop music now features 23-bar cycles. tutorial videos explain how to escape copyright infringement using arabic 17 tone equal temperament. noise music experiences a renaissance.

One of the coolest uses I’ve seen of a NeRF so far

embodied experience as to what it is like to be a big bird

VRヘッドトラッキングを使ってドローンのパイロット気分を味わう youtu.be/N5cBKmFZ6Lo #FPV #POV #drone #OpenSource #HeadTracker #HMD #VR #VirtualReality #UX #experience

Announcing StableLM❗ We’re releasing the first of our large language models, starting with 3B and 7B param models, with 15-65B to follow. Our LLMs are released under CC BY-SA license. We’re also releasing RLHF-tuned models for research use. Read more→ stability.ai/blog/stability…

Rather than sign some letter to delay AI progress, I signed @LAION_AI petition to democratize AI research by establishing an international, publicly funded supercomputing facility equipped with 100K SOTA accelerators to train open source foundation models. openpetition.eu/petition/onlin…

possibly one of the funniest model on the hub (the RLHF tutorial that was the reason of its creation is also awesome - check it out)

Excited to introduce: StackLlama🦙 An end-to-end tutorial for training Llama with RLHF on preference data such as the StackExchange questions! Blog: hf.co/blog/stackllama Demo: hf.co/spaces/trl-lib… Code: github.com/lvwerra/trl/tr… The resulting model is surprisingly fun!🧵


The last couple of weeks on Twitter, aka GPT4 Twitter



Semi-realtime Stable Diffusion image-to-image (Van Gogh style), Unity plugin based on Apple's Core ML port. The latency is about 2 seconds on M1 Max MacBook Pro. github.com/keijiro/Stable…

🎧🧠

🎵Introducing Diffusion Radio - A 24/7 Livestream of AI-Generated Music!🎵 📢The Harmonai team is excited to announce a New YouTube Live Stream which will run 24/7, showcasing amazing samples of AI-generated music from our latest models!📢 🎉Enjoy!🎉 youtube.com/watch?v=uGRLOM…

youtube.com
YouTube
🎵 Diffusion Radio - 24/7 AI music from Harmonai 🎵 [NEW LINK IN...

New paper from our research team: First true multimodal image synthesis. You can prompt any combination of texts and images. Also shows the power of our multimodal embedding. Check out the Catronaut in the paper.



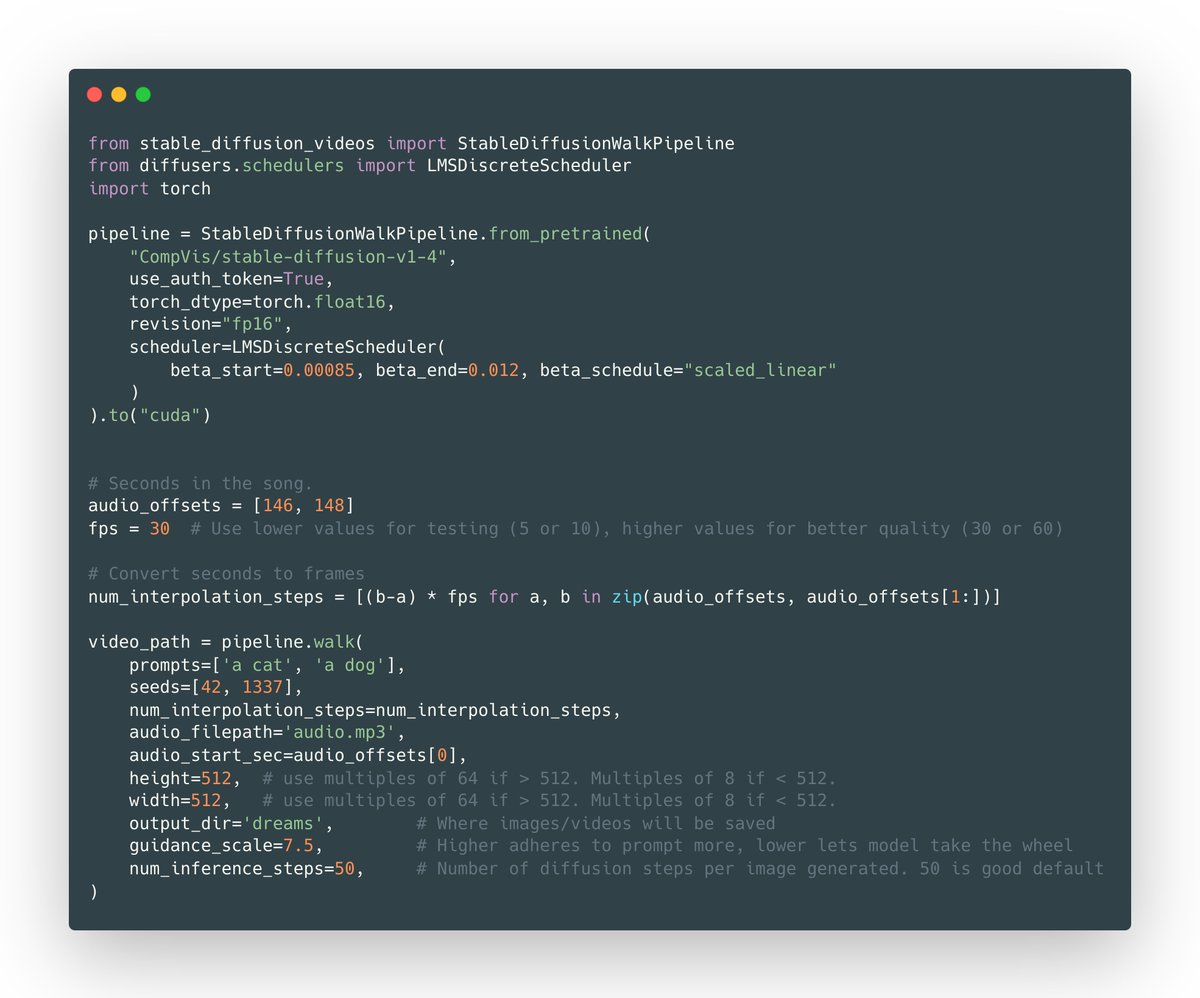
You can now make stable diffusion music videos that interpolate to the beat of a song using stable_diffusion_videos==0.5.0! 🚀 I basically rewrote the codebase! Everything is in the pipeline class now, so you can load other models too. Anyway, here's how to use it...













































































































United States Trends
- 1. zendaya 5,735 posts
- 2. trisha paytas 2,034 posts
- 3. Apple TV 10.6K posts
- 4. No Kings 232K posts
- 5. #FanCashDropPromotion 1,493 posts
- 6. #FridayVibes 7,967 posts
- 7. #เพียงเธอตอนจบ 2.1M posts
- 8. LINGORM ONLY YOU FINAL EP 2.09M posts
- 9. #FursuitFriday 14.3K posts
- 10. #Yunho 29.4K posts
- 11. GAME DAY 33.7K posts
- 12. Arc Raiders 5,215 posts
- 13. Mamdani 297K posts
- 14. Cuomo 128K posts
- 15. Eli Roth N/A
- 16. My President 62.5K posts
- 17. Trevon Diggs N/A
- 18. Bolton 300K posts
- 19. Karoline Leavitt 46.4K posts
- 20. Good Friday 64.9K posts
You might like
-
 dadabots
dadabots
@dadabots -
 Javier Nistal
Javier Nistal
@latentspaces -
 Stefan Lattner
Stefan Lattner
@deeplearnmusic -
 ISMIR Conference
ISMIR Conference
@ISMIRConf -
 Eduardo Fonseca
Eduardo Fonseca
@edfonseca_ -
 Jordi Pons
Jordi Pons
@jordiponsdotme -
 Pedro Sarmento
Pedro Sarmento
@umpedronosapato -
 Ethan Manilow
Ethan Manilow
@ethanmanilow -
 Scott H. Hawley
Scott H. Hawley
@drscotthawley -
 Yi-Hsuan Yang
Yi-Hsuan Yang
@affige_yang -
 Marco Martínez
Marco Martínez
@marcoamaram -
 Dorien Herremans
Dorien Herremans
@dorienherremans -
 Matan Gover
Matan Gover
@matangover
Something went wrong.
Something went wrong.