
Just wrapped up a great week in ICIP 2025 @ Anchorage, Alaska presenting our paper about Matching cross-domain fingerprint images using contrastive training. It was great getting inspired from brilliant minds. #ICIP2025




✨ Today we're launching AI coding features to our Pro+ subscribers located in the United States, including natural language to code generation, code completion, and an integrated chatbot. We'd love to hear from you with positive examples of AI coding in Colab: please share! 1/

Top ML Papers of the Week (June 5-11): - AlphaDev - MusicGen - Fine-Grained RLHF - Humor in ChatGPT - Concept Scrubbing in LLM - Augmenting LLMs with Databases ...


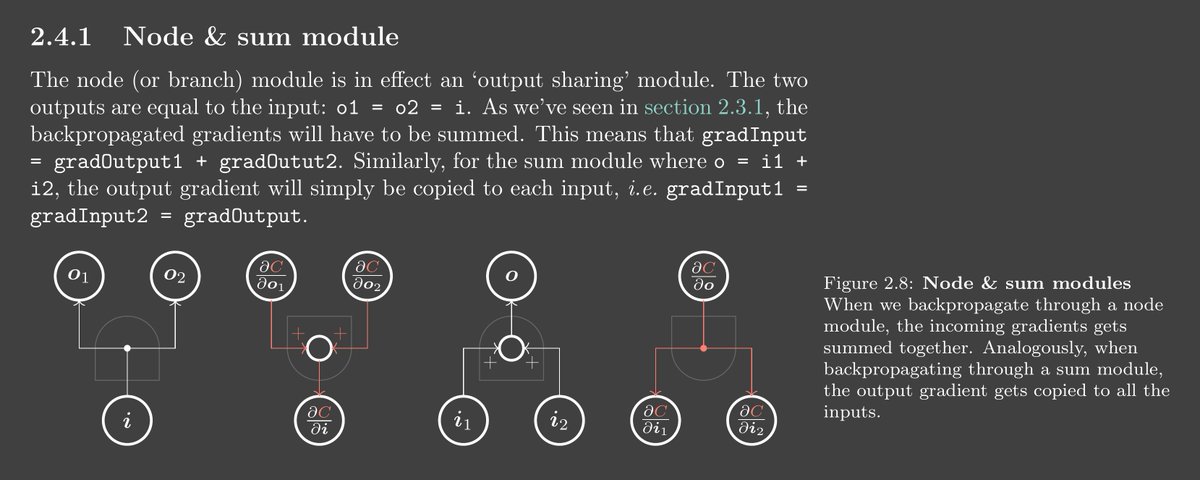
A neural net is made of simple building blocks. Learning how the output gradient is backpropagated through these basic components helps us understand how each part contributes to the final model performance. Below we see how the node & sum complimentary modules behave.

One year from now, what size LLM (large language model) do you think will be used for the most inferences?

















































United States 트렌드
- 1. Good Saturday 27.9K posts
- 2. Delap 14K posts
- 3. Burnley 33.3K posts
- 4. Gittens 8,235 posts
- 5. #SaturdayVibes 3,955 posts
- 6. Andrey Santos 2,603 posts
- 7. #Caturday 2,964 posts
- 8. Joao Pedro 6,331 posts
- 9. #BURCHE 16.5K posts
- 10. #askdave N/A
- 11. Neto 20.6K posts
- 12. Tosin 8,443 posts
- 13. Maresca 18.1K posts
- 14. Chalobah 4,347 posts
- 15. #MeAndTheeSeriesEP2 533K posts
- 16. The View 99.1K posts
- 17. Jair Bolsonaro 80.7K posts
- 18. Somali 85.6K posts
- 19. IT'S GAMEDAY 1,973 posts
- 20. Reece 6,843 posts
Something went wrong.
Something went wrong.