
danielw
@dddanielwang
独立开发 & 西语海外销售,开发 agent 能力边界,分享通用 agent 实战经验与方法论 building http://anyvocab.com, opencodian (opencode in obsd): http://github.com/DanielDaniel2201/opencodian
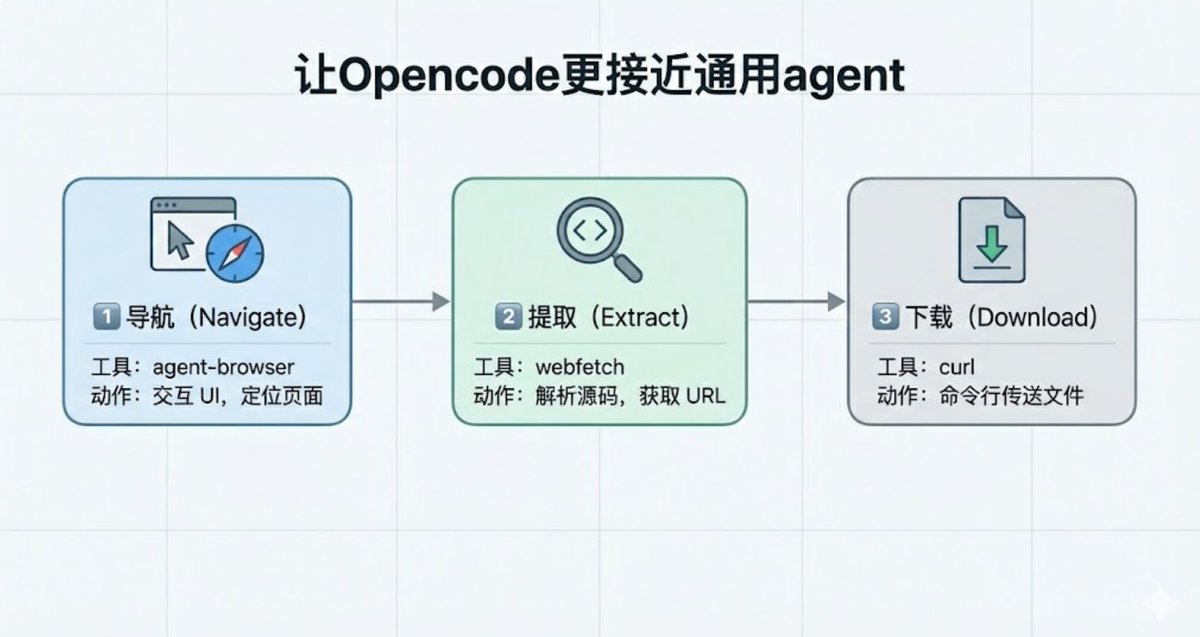
manus 和 claude cowork 太贵了! 我用 agent-browser 赋予 opencode 使用浏览器的能力,向通用 agent靠近(附agent工作轨迹) 成功的测试 Prompt:下载qs世界大学学科排名excel 然而单个 agent-browser 工具是完成不了的:agent-brower…
关于 Skill的又一重磅直播!

对Skills和Claude Agent生态感兴趣的朋友不妨来听听明天上午9:30的𝕏直播 特别感谢Asa @AppSaildotDEV 的张罗和活动,邀请到了多位重磅技术和业务专家: Vercel和Nextjs核心成员,同时也是耳熟能详的skills包作者 @andrewqu @gao_jude Rust专家、中文社区头号布道者 @blackanger…

不知道playwright cli跟agent-browser cli比何如,有时间了跑跑我的silly test case但是这俩都不能像dev-browser一样用插件借调用户已有的的浏览器

📢 Meet Playwright CLI — a SKILL-friendly way of the browser automation. Learn more at github.com/microsoft/play…. Happy testing!
对我在开发opencodian超级大的借鉴意义,我可以借此机会规范vibe coding流程,锻炼自己开发和应用agent的能力 非常感谢 大佬不仅开源这么棒的 agent,还如此公开自己开发过程

思考了一下,不能再做一个llm wrapper了,感觉在重复造轮子,真的有一丁点contribution吗 又想加memory,又想加browser 还是老老实实用已有的opencode plugin就好 如果有新alternative的技术,尝鲜就好…

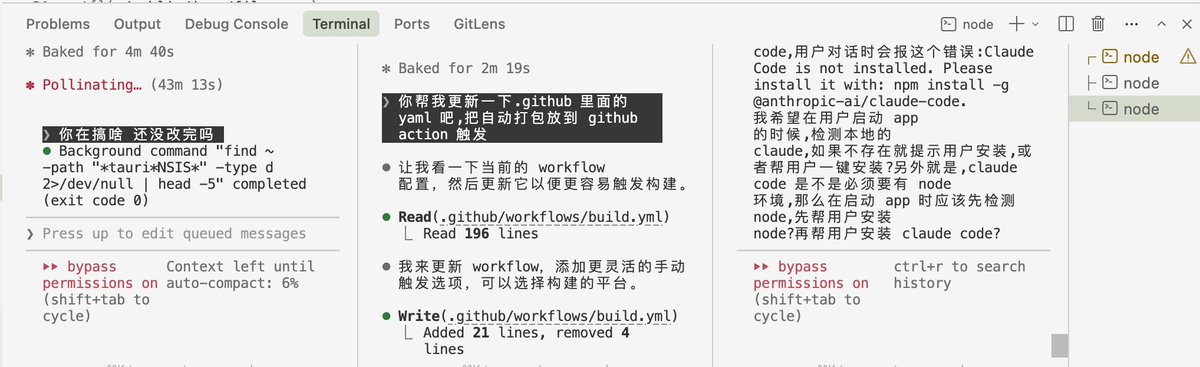
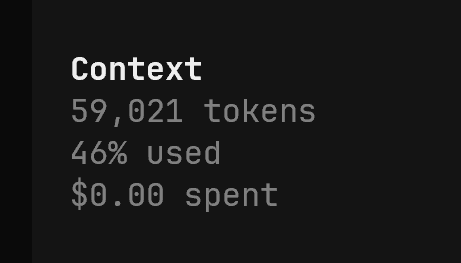
GPT5.2太美妙了,6万token,直接帮我修好gemini 3 pro和opus 4.5几百万token没修好的bug 我从gemini, claude叛变为gpt忠实的信徒 我通过opencode用Copilot的gpt5.2 很奇怪gpt5.2 codex一直用不了,提示disabled,但是明明enable了
赞同,有了需求之后,从最小原型出发,也就是一个llm prompt开始 如果解决不了需求,再逐步迭代,加tool call,memory等等add-on claude code本身就是向universal use迭代,而不是specific use
我在开发Opencodian的时候就希望能做一个跨对话记忆功能,因为重开一个全新对话session,还是有点太孤立了 试图从skills中汲取灵感,做progressive disclosure:每个对话持久化后形成一个description,历史对话们的descriptions在新对话中会跟随用户的promtp一起喂给LLM…


对于为agent设计的工具类 skill不应该是塞满command信息,也得有heuristics/人类偏好的/高效使用的规范 灵感来源于不愉快的使用经历:x.com/dddanielwang/s……
agent-browser的初体验: 结论:opencode + opus + agent-browser不如manus lite (借调用户浏览器) 因为论文需求要下载qs世界大学学科排名excel,突然想到 @vercel 新发了agent-browser,号称CLI for agent,试试看能不能让Opencode利用agent-browser来帮我自动化这种任务…

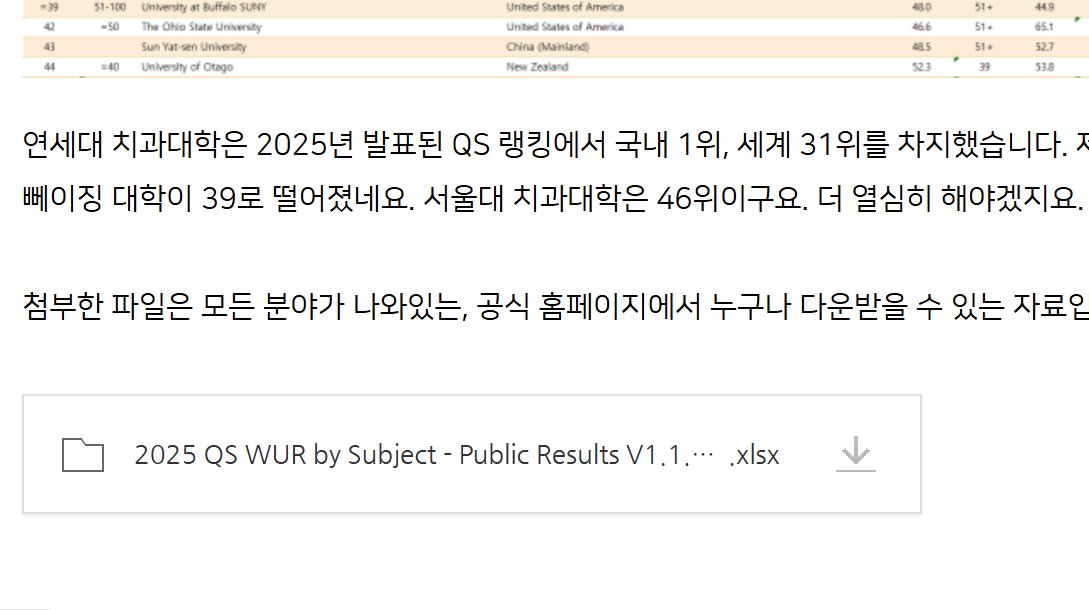
感觉这个实验又为Ralph loop提供了支持,ralph就是反复把同一个coding prompt喂给agent,直到完成 ralph skill for claude code: github.com/wquguru/ralph-… 以及大佬做的ralph可视化: wquguru.github.io/ralph-ryan/


Prompt 新技能 Get: Google 论文里有个实验叫 NameIndex, 正常提示下,模型准确率大概 21.33%, 把同一个 prompt 重复一遍之后,直接拉到 97.33%。 跟给人安排工作一模一样, 重要的事情说三遍这套, 对人管用,对 LLM 也一样。














































































United States Trends
- 1. Another ICE N/A
- 2. Romero N/A
- 3. Border Patrol N/A
- 4. Burnley N/A
- 5. Jasper Johnson N/A
- 6. Thomas Frank N/A
- 7. Armed N/A
- 8. Harry Wilson N/A
- 9. Gigi N/A
- 10. Wink N/A
- 11. Jose Ramirez N/A
- 12. #Caturday N/A
- 13. #saturdaymorning N/A
- 14. Good Saturday N/A
- 15. Travis Perry N/A
- 16. #FrankOut N/A
- 17. MetLife N/A
- 18. #ICEOUT N/A
- 19. The Discombobulator N/A
- 20. #COYS N/A
Something went wrong.
Something went wrong.