

An exciting new approach for doing continual learning, using nested optimization for enhancing long context processing.

Introducing Nested Learning: A new ML paradigm for continual learning that views models as nested optimization problems to enhance long context processing. Our proof-of-concept model, Hope, shows improved performance in language modeling. Learn more: goo.gle/47LJrzI…



Excited to share our new paper, "DataRater: Meta-Learned Dataset Curation"! We explore a fundamental question: How can we *automatically* learn which data is most valuable for training foundation models? Paper: arxiv.org/pdf/2505.17895 to appear @NeurIPSConf Thread 👇

Our TPUs are headed to space! Inspired by our history of moonshots, from quantum computing to autonomous driving, Project Suncatcher is exploring how we could one day build scalable ML compute systems in space, harnessing more of the sun’s power (which emits more power than 100…


A large solar-powered AI satellite constellation would be able to prevent global warming by making tiny adjustments in how much solar energy reached Earth

To push self-driving into situations wilder than reality, we built a neural network world simulator that can create entirely synthetic worlds for the Tesla to drive in. Video below is fully generated & not a real video

My pleasure to come on Dwarkesh last week, I thought the questions and conversation were really good. I re-watched the pod just now too. First of all, yes I know, and I'm sorry that I speak so fast :). It's to my detriment because sometimes my speaking thread out-executes my…

The @karpathy interview 0:00:00 – AGI is still a decade away 0:30:33 – LLM cognitive deficits 0:40:53 – RL is terrible 0:50:26 – How do humans learn? 1:07:13 – AGI will blend into 2% GDP growth 1:18:24 – ASI 1:33:38 – Evolution of intelligence & culture 1:43:43 - Why self…
Excited to release new repo: nanochat! (it's among the most unhinged I've written). Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single,…


Introducing Tinker: a flexible API for fine-tuning language models. Write training loops in Python on your laptop; we'll run them on distributed GPUs. Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!…


Starting today, we’re introducing a major new update to AI Mode in Search, making visual exploration more natural than ever before. Now you can ask a question conversationally and get a range of visual results, with the ability to continuously refine your search in more natural…

Excited to launch Sora 2! Video models have come a long way; this is a tremendous research achievement. Sora is also the most fun I've had with a new product in a long time. The iOS app is available in the App Store in the US and Canada; we will expand quickly.

New on the Anthropic Engineering Blog: Most developers have heard of prompt engineering. But to get the most out of AI agents, you need context engineering. We explain how it works: anthropic.com/engineering/ef…

LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.…


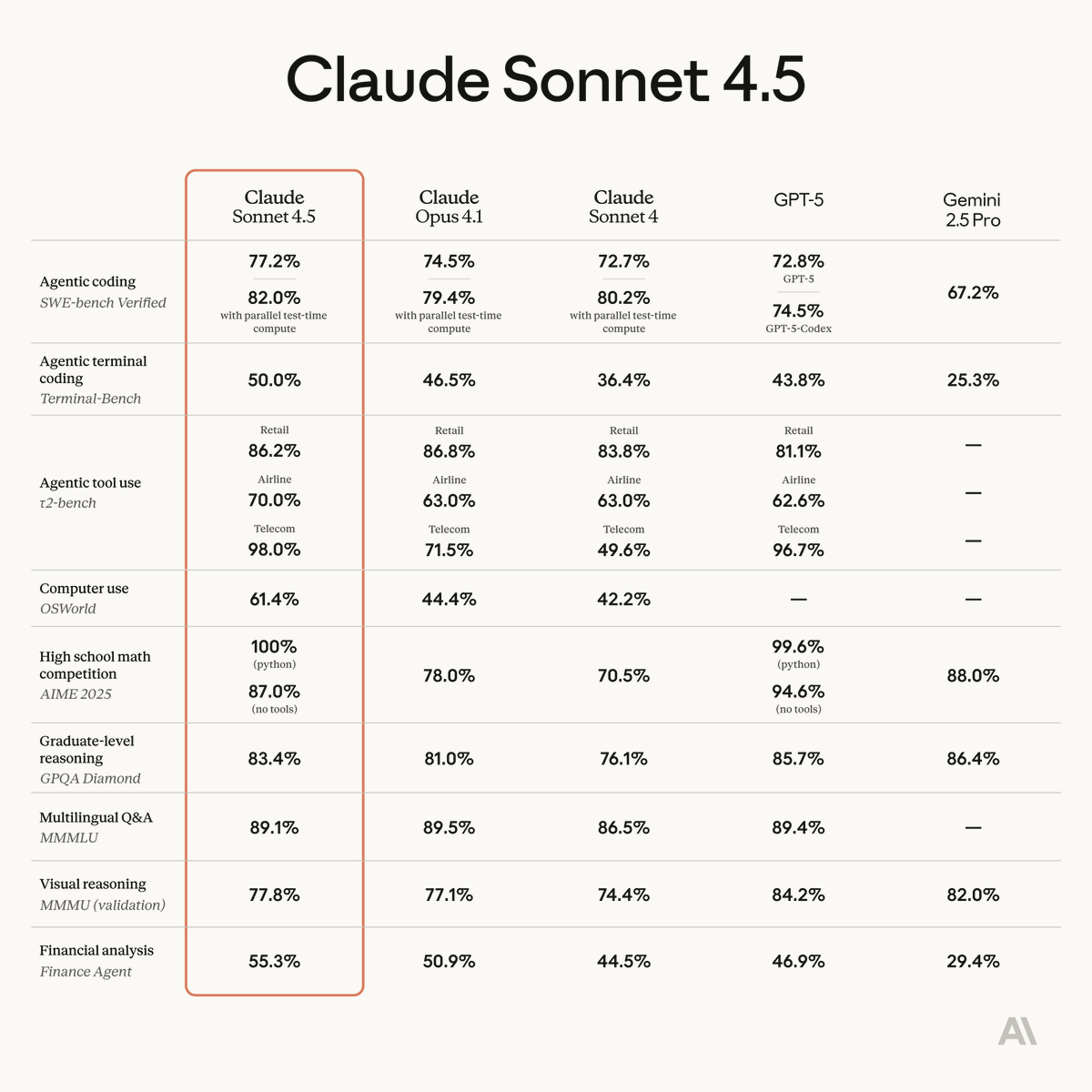
Introducing Claude Sonnet 4.5—the best coding model in the world. It's the strongest model for building complex agents. It's the best model at using computers. And it shows substantial gains on tests of reasoning and math.
Parents, guardians, educators and students can now find our latest AI resources and tools in the new AI Literacy hub, from insightful podcasts and Googler-led courses to how-to videos. Learn more → goo.gle/47v7yEq


in a normal world i'd make this a blogpost but i'm quite busy with tmr's ✨big announcement✨ so basically here are the 4 valid scenarios in the local models dream most big lab people believe 1, most investors/biz people believe 2, huggingface et al believe either 3 or 4, and…


suspect we're a few months (if not weeks!) away from a model that's good enough for tool calling / small enough to be shipped on devices/OSes by default these already exist in research space, but hitting mainstream /consumer space is when it'll really take off. apps will be…
In era of pretraining, what mattered was internet text. You'd primarily want a large, diverse, high quality collection of internet documents to learn from. In era of supervised finetuning, it was conversations. Contract workers are hired to create answers for questions, a bit…

Introducing the Environments Hub RL environments are the key bottleneck to the next wave of AI progress, but big labs are locking them down We built a community platform for crowdsourcing open environments, so anyone can contribute to open-source AGI
+1 for "context engineering" over "prompt engineering". People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window…

I really like the term “context engineering” over prompt engineering. It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.
From my friend @vinayramasesh: "I would benefit most from an explanation style in which you frequently pause to confirm, via asking me test questions, that I've understood your explanations so far. Particularly helpful are test questions related to simple, explicit examples.…
We're missing (at least one) major paradigm for LLM learning. Not sure what to call it, possibly it has a name - system prompt learning? Pretraining is for knowledge. Finetuning (SL/RL) is for habitual behavior. Both of these involve a change in parameters but a lot of human…





























































































United States Trends
- 1. Sunderland 86.5K posts
- 2. Texas Tech 9,662 posts
- 3. St. John 4,956 posts
- 4. #GoDawgs 3,003 posts
- 5. #iufb 1,091 posts
- 6. Merino 9,468 posts
- 7. Mendoza 8,155 posts
- 8. Obamacare 174K posts
- 9. Mississippi State 3,831 posts
- 10. Verstappen 23.1K posts
- 11. Letang N/A
- 12. #SUNARS 6,389 posts
- 13. Elyiss Williams N/A
- 14. Shapen N/A
- 15. Xhaka 8,054 posts
- 16. Philon N/A
- 17. Lebby N/A
- 18. Lawson Luckie N/A
- 19. #SaturdayVibes 5,803 posts
- 20. #BYUFOOTBALL N/A
Something went wrong.
Something went wrong.