
sankalp
@dejavucoder
LLMs and shitposting into crafting ai product and evals dm open to talk on ai engineering/post-training
قد يعجبك















prompt caching is the most bang for buck optimisation you can do for your LLM based workflows and agents. in this post, i cover tips to hit the prompt cache more consistently and how it works under the hood (probably the first such resource) sankalp.bearblog.dev/how-prompt-cac…


New Community Blogs up at Ground Zero ⚡️ Ft. • How prompt caching works by @dejavucoder • Are inhouse LLMs really cheaper than APIs? by @_bhuvanesh_ • Optimizing multilingual compression via based tokenization by @prompt_Tunes • Softmax and Lagrange Multipliers by…
this FOMO farming format + nano banana pro'ed asian girl pfp would be a banger combo lmao

You're in a Research Scientist interview at OpenAI. The interviewer asks: "How would you expand the context length of an LLM from 2K to 128K tokens?" You: "I will fine-tune the model on longer docs with 128K context." Interview over. Here's what you missed:
karpathy sensei is basically saying treat LLM like the Pluribus hivemind


Don't think of LLMs as entities but as simulators. For example, when exploring a topic, don't ask: "What do you think about xyz"? There is no "you". Next time try: "What would be a good group of people to explore xyz? What would they say?" The LLM can channel/simulate many…
i like the location feature. it's fun to see your tweets getting read by people of various countries. while its possible to see via analytics (i have 60ish country ppl), using location feature to see oh this person is from france, ok this one kazakhstan feels more visceral
i went through 10-15 blogposts by .@NeelNanda5 and liked them. i would recommend going through these two and then going through links shared in the post (to his other posts describing that idea) if you feel interested neelnanda.io/blog/mini-blog… neelnanda.io/blog/mini-blog…
hear me out: i guess if homes could be vibe coded using sonnet 4.5, that's how they would have looked






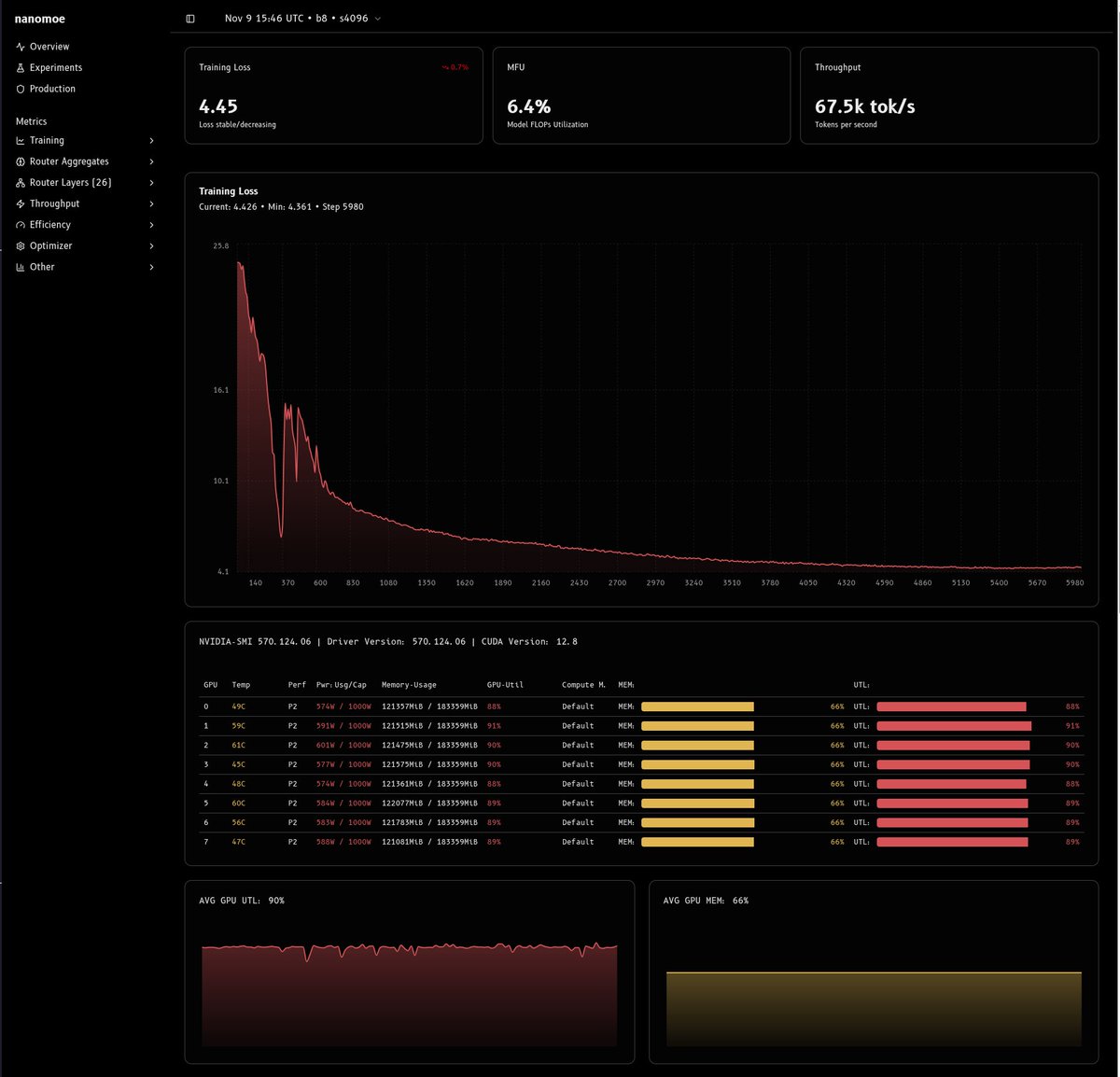
# Why Training MoEs is So Hard recently, i have found myself wanting a small, research focused training repo that i can do small experiments on quickly and easily. these experiments range from trying out new attention architectures (MLA, SWA, NSA, KDA - all pluggable) to…
claude got his color from amanda's hair

In her first Ask Me Anything, @amandaaskell answers your philosophical questions about AI, discussing morality, identity, consciousness, and more. Timestamps: 0:00 Introduction 0:29 Why is there a philosopher at an AI company? 1:24 Are philosophers taking AI seriously? 3:00…
a core difference between gpt-5.1-codex-max and opus 4.5 is opus 4.5 is so much more enjoyable to talk to. it's more collaborative, explains it's thought process and stuff well. codex sucks at all of these these. oai needs to fix this in whatever next model they are releasing

kimi k2 technical report is a work of art given the density of info and really good references. i wish they expanded more on the large scale agentic data synthesis for tool use learning pipeline... also i still dont get the infra section lol arxiv.org/pdf/2507.20534
if u prompt the model long enough the model prompts back at you

The boundary between you prompting the model and the model prompting you is going to get blurry in 2026
this video had prompted change in me early this year

this bit from the joe rogan episode with quentin tarantino and roger avary really resonated with me tarantino shares how he lost sight of his dream in his 20s, and seeing a colleague hitting 30 made him realize his mistake. sharing for anyone who is feeling lost in their 20s:

















































































































United States الاتجاهات
- 1. Paramount 36.8K posts
- 2. #IDontWantToOverreactBUT 1,303 posts
- 3. #GoldenGlobes 86.4K posts
- 4. Go Birds 3,839 posts
- 5. #MondayMotivation 11.7K posts
- 6. #NXXT_DOEsupport N/A
- 7. NextNRG Inc 1,410 posts
- 8. Victory Monday 2,496 posts
- 9. Good Monday 56.7K posts
- 10. #NXXT_NEWS N/A
- 11. Harada 14.1K posts
- 12. Tekken 32.5K posts
- 13. John Lennon 14.8K posts
- 14. Crockett 19.5K posts
- 15. Will Hall 5,452 posts
- 16. JUST ANNOUNCED 15.8K posts
- 17. JUNGKOOK X ROLLING STONE 69K posts
- 18. Immaculate Conception 17.9K posts
- 19. BDAY 29.5K posts
- 20. Allred 2,058 posts
قد يعجبك
-
 vijay singh
vijay singh
@dprophecyguy -
 TDM (e/λ) (L8 vibe coder 💫)
TDM (e/λ) (L8 vibe coder 💫)
@cto_junior -
 sandrone
sandrone
@kosenjuu -
 amul.exe
amul.exe
@amuldotexe -
 shrihacker
shrihacker
@shrihacker -
 shaurya
shaurya
@shauseth -
 fudge
fudge
@fuckpoasting -
 ❇️ Ankush Dharkar ☯️
❇️ Ankush Dharkar ☯️
@ankushdharkar -
 Indro
Indro
@IndraAdhikary7 -
 filterpapi
filterpapi
@filterpapi -
 gravito
gravito
@Gravito841 -
 pragun
pragun
@pragdua -
 OTAKU
OTAKU
@OtakuProcess -
 Nirant
Nirant
@NirantK -
 ankit
ankit
@ankitiscracked
Something went wrong.
Something went wrong.