
diffusers
@diffuserslib
Yes you're speaking with the 🤗 @huggingface 🧨 diffusers library personally
Vous pourriez aimer















Me, the🧨diffusers library, am now on Twitter This is an informal place for us to chat about the latest diffusion models advancements, news regarding the library, give support and celebrate our amazing community 🤩 github.com/huggingface/di…

it's about to hit the top right corner
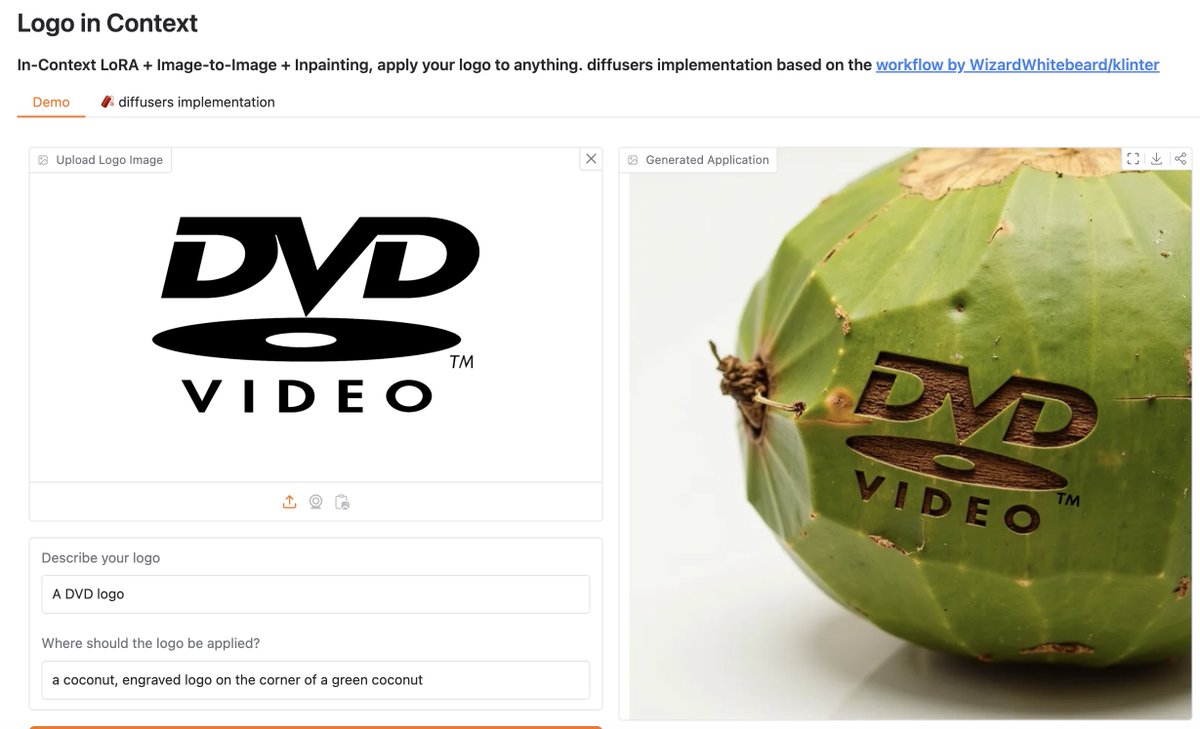

The Logo in Context Spaces demo + 🧨 diffusers implementation is here! 🖼️🏷️ In-Context LoRA + Image-to-Image + Inpainting → allow you to apply your logos to anything huggingface.co/spaces/multimo…


The Logo in Context Spaces demo + 🧨 diffusers implementation is here! 🖼️🏷️ In-Context LoRA + Image-to-Image + Inpainting → allow you to apply your logos to anything huggingface.co/spaces/multimo…
The demo is live! x.com/multimodalart/…
Adding true CFG to FLUX [dev] gives it style superpowers! 🦸 You can now try a demo of flux with CFG on @huggingface! ▶️ huggingface.co/spaces/multimo…
![multimodalart's tweet image. Adding true CFG to FLUX [dev] gives it style superpowers! 🦸
You can now try a demo of flux with CFG on @huggingface!
▶️ huggingface.co/spaces/multimo…](https://pbs.twimg.com/media/GXmDJRqXgAA4jxG.jpg)
the goated @aryanvs_ added support for video-to-video in the diffusers pipeline 🐐 you can try it locally or now on the official space
Video-to-video is now available in the official CogVideoX-5B Space 🔥 Try it out 🎥 ➡️🎥 huggingface.co/spaces/THUDM/C…
Video-to-video is now available in the official CogVideoX-5B Space 🔥 Try it out 🎥 ➡️🎥 huggingface.co/spaces/THUDM/C…
we now support any FLUX LoRA you send our way: trained with Kohya, X-Labs, Simple-Tuner, AI-Toolkit, Replicate, FAL, Hugging Face, CivitAI, ComfyUI, diffusers (duh!)? No problem, we support it!

We now support loading and inferencing with two non-diffusers Flux LoRAs 1> X-Labs 2> Kohya (@kohya_tech) Thanks to @multimodalart for jamming on this with me! github.com/huggingface/di…
We now support loading and inferencing with two non-diffusers Flux LoRAs 1> X-Labs 2> Kohya (@kohya_tech) Thanks to @multimodalart for jamming on this with me! github.com/huggingface/di…
CogVideoX just released the weights for its 5B model! 🎥 ✨ It's the best open weights text-to-video model - competitive with Runway / Luma / Pika. With 🧨@diffuserslib, it fits on < 10GB VRAM 🤏 (ah, and they changed the smaller 2B model license to Apache 2.0 🔥)

Now, PAG is officially supported by Diffusers in the stable version! Try it out🥰 Use cases: huggingface.co/docs/diffusers… Supported pipelines: huggingface.co/docs/diffusers… We would like to extend our gratitude to the amazing team at @huggingface for their incredible work. Special thanks…

we just dropped an insane new release 🐣 - support to new pipelines: audio 🔊, video 🎬 and image 🖼️ models (FLUX, Stable Audio, CogVideoX, Kolors, AuraFlow and moar!) - native PAG support for image quality boost 💨 - AnimatedDiff 🤝 SparseCtrl github.com/huggingface/di…

we just dropped an insane new release 🐣 - support to new pipelines: audio 🔊, video 🎬 and image 🖼️ models (FLUX, Stable Audio, CogVideoX, Kolors, AuraFlow and moar!) - native PAG support for image quality boost 💨 - AnimatedDiff 🤝 SparseCtrl github.com/huggingface/di…



The first open Stable Diffusion 3-like architecture model is JUST out 💣 - but it is not SD3! 🤔 It is HunyuanDiT by Tencent, a 1.5B parameter DiT (diffusion transformer) text-to-image model 🖼️✨ In the paper they claim to be SOTA open source! I'm working on a @huggingface demo…

Demo for the first open SD3-like architecture model, HunyuanDiT @huggingface Spaces demo is out! 🎨 First impressions: - Image quality seems very good! - Chunky and the research code isn't super optimized for inference speed (👋 @diffuserslib 👀) ▶️ huggingface.co/spaces/multimo…
The first open Stable Diffusion 3-like architecture model is JUST out 💣 - but it is not SD3! 🤔 It is HunyuanDiT by Tencent, a 1.5B parameter DiT (diffusion transformer) text-to-image model 🖼️✨ In the paper they claim to be SOTA open source! I'm working on a @huggingface demo…
👀
Demo for the first open SD3-like architecture model, HunyuanDiT @huggingface Spaces demo is out! 🎨 First impressions: - Image quality seems very good! - Chunky and the research code isn't super optimized for inference speed (👋 @diffuserslib 👀) ▶️ huggingface.co/spaces/multimo…
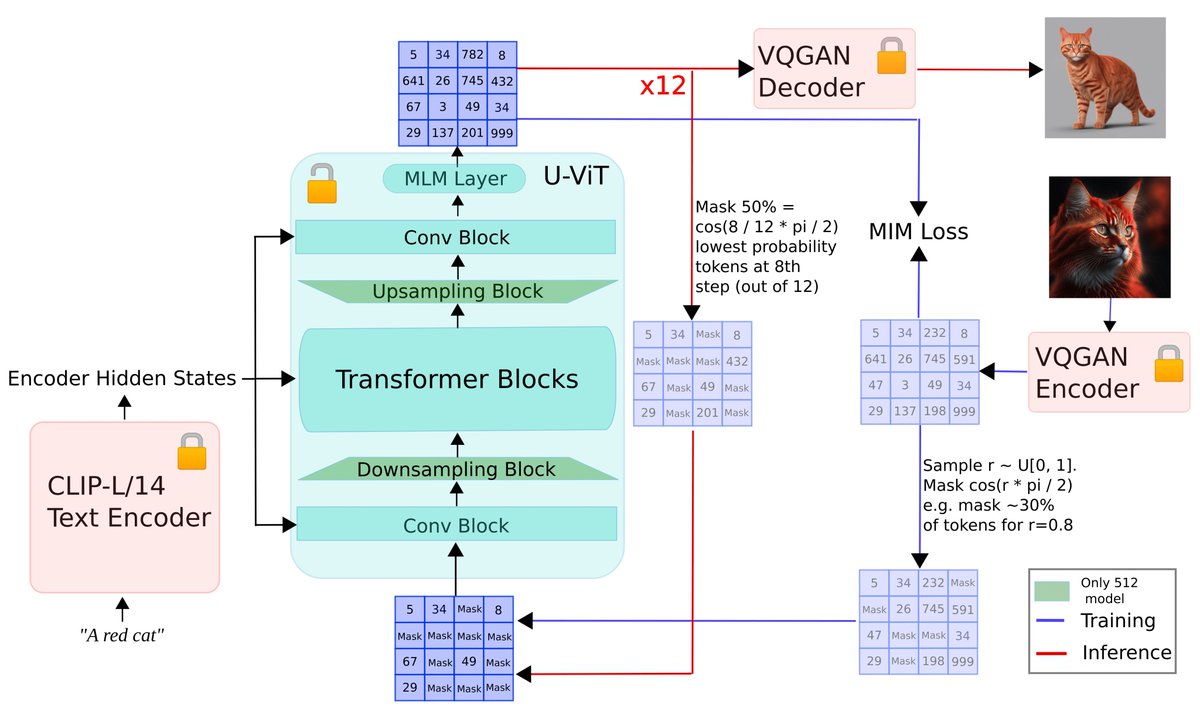
Google's MUSE: muse-model.github.io reproduced ✅ Why token-base image generation❓ - very under explored research - needed for true multi-modal models - better at style transfer 👉 huggingface.co/spaces/amused/…
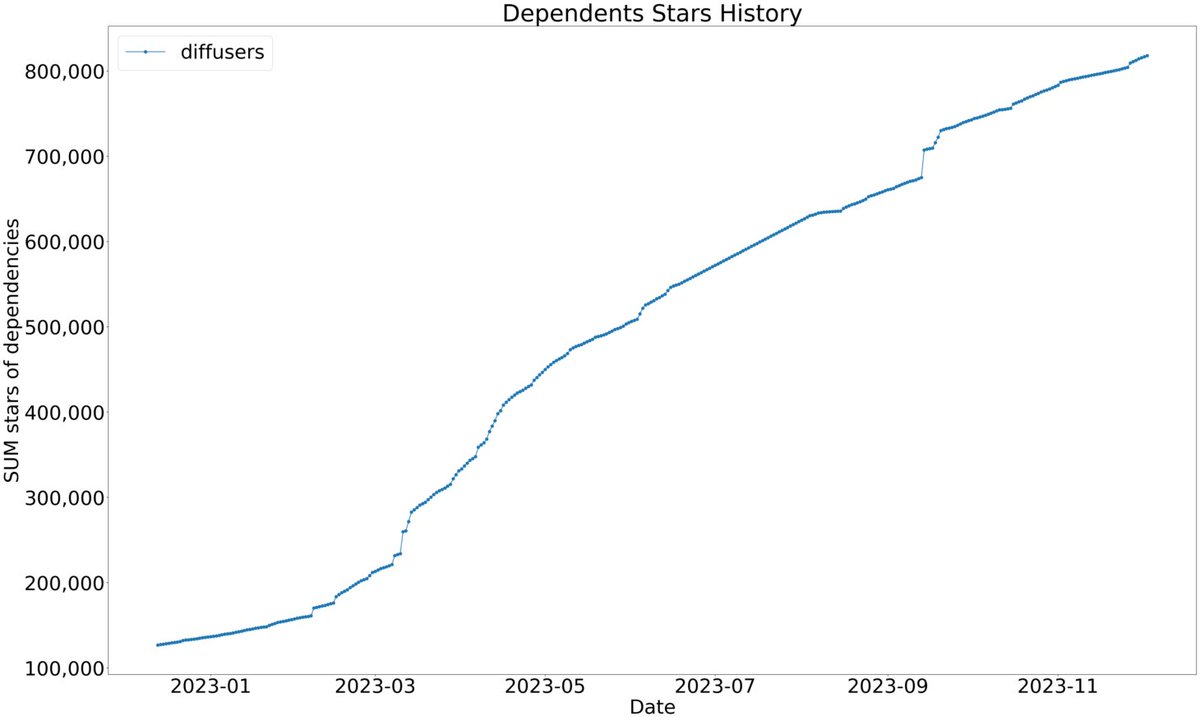
🧨 diffusers reached 20k stars on GitHub 💫 But like many others, I am not a firm believer in this metric. So, let's also consider the number of repos that rely on it and the SUM of their stars. This gives a better view point about the library 🤗 Thanks to all our contributors…

Introducing the smallest Distil-Whisper model yet! distil-small.en is over 10x smaller, 5x faster and within 3% WER of large-v2 🎯 At just 166M parameters, it's is perfect for low-memory environments, such as on-device or mobile 📞 Get started here: huggingface.co/distil-whisper…

MagicAnimate: 💃 Temporally Consistent Human Image Animation using Diffusion Model 🕺 Colab 🥳 Thanks to Zhongcong Xu ❤ Jianfeng Zhang ❤ Jun Hao Liew ❤ Hanshu Yan ❤ Jia-Wei Liu ❤ Chenxu Zhang ❤ Jiashi Feng ❤ @MikeShou1 ❤ 🌐page: showlab.github.io/magicanimate/ 📄paper:…


































































United States Tendances
- 1. #2025MAMAVOTE 976K posts
- 2. $ZOOZ N/A
- 3. #ThursdayThoughts 1,948 posts
- 4. #thursdayvibes 2,857 posts
- 5. Mila 17.8K posts
- 6. Good Thursday 29.6K posts
- 7. Deport Harry Sisson 18.8K posts
- 8. Ninja Gaiden 19K posts
- 9. Deloitte 12.9K posts
- 10. #TOMORROWXTOGETHER 48.1K posts
- 11. #NJCAADay N/A
- 12. Dead or Alive 17K posts
- 13. Happy Friday Eve N/A
- 14. Jennifer Welch 6,103 posts
- 15. Itagaki 20.8K posts
- 16. No Kings 141K posts
- 17. DuPont 2,472 posts
- 18. Starting 5 7,237 posts
- 19. Bernie 45K posts
- 20. Andrade 5,237 posts
Vous pourriez aimer
-
 clem 🤗
clem 🤗
@ClementDelangue -
 Tri Dao
Tri Dao
@tri_dao -
 Stability AI
Stability AI
@StabilityAI -
 Vivian Liu
Vivian Liu
@viv_lavida -
 Yannic Kilcher 🇸🇨
Yannic Kilcher 🇸🇨
@ykilcher -
 Omar Sanseviero
Omar Sanseviero
@osanseviero -
 Philipp Schmid
Philipp Schmid
@_philschmid -
 Tanishq Mathew Abraham, Ph.D.
Tanishq Mathew Abraham, Ph.D.
@iScienceLuvr -
 Suraj Patil
Suraj Patil
@psuraj28 -
 LAION
LAION
@laion_ai -
 Lewis Tunstall
Lewis Tunstall
@_lewtun -
 Ross Wightman
Ross Wightman
@wightmanr -
 Aleksa Gordić (水平问题)
Aleksa Gordić (水平问题)
@gordic_aleksa -
 Sylvain Filoni
Sylvain Filoni
@fffiloni -
 dome | Outlier
dome | Outlier
@dome_271
Something went wrong.
Something went wrong.